6-----Scrapy框架中Item Pipeline用法
当Item 在Spider中被收集之后,就会被传递到Item Pipeline中进行处理
每个item pipeline组件是实现了简单的方法的python类,负责接收到item并通过它执行一些行为,同时也决定此Item是否继续通过pipeline,或者被丢弃而不再进行处理
item pipeline的主要作用:
1、清理html数据
2、验证爬取的数据
3、去重并丢弃
4、讲爬取的结果保存到数据库中或文件中
编写自己的item pipeline
process_item(self,item,spider)
每个item piple组件是一个独立的pyhton类,必须实现以process_item(self,item,spider)方法
每个item pipeline组件都需要调用该方法,这个方法必须返回一个具有数据的dict,或者item对象,或者抛出DropItem异常,被丢弃的item将不会被之后的pipeline组件所处理
下面的方法也可以选择实现
open_spider(self,spider)
表示当spider被开启的时候调用这个方法
close_spider(self,spider)
当spider挂去年比时候这个方法被调用
from_crawler(cls,crawler)
这个和我们在前面说spider的时候的用法是一样的,可以用于获取settings配置文件中的信息,需要注意的这个是一个类方法,用法例子如下:
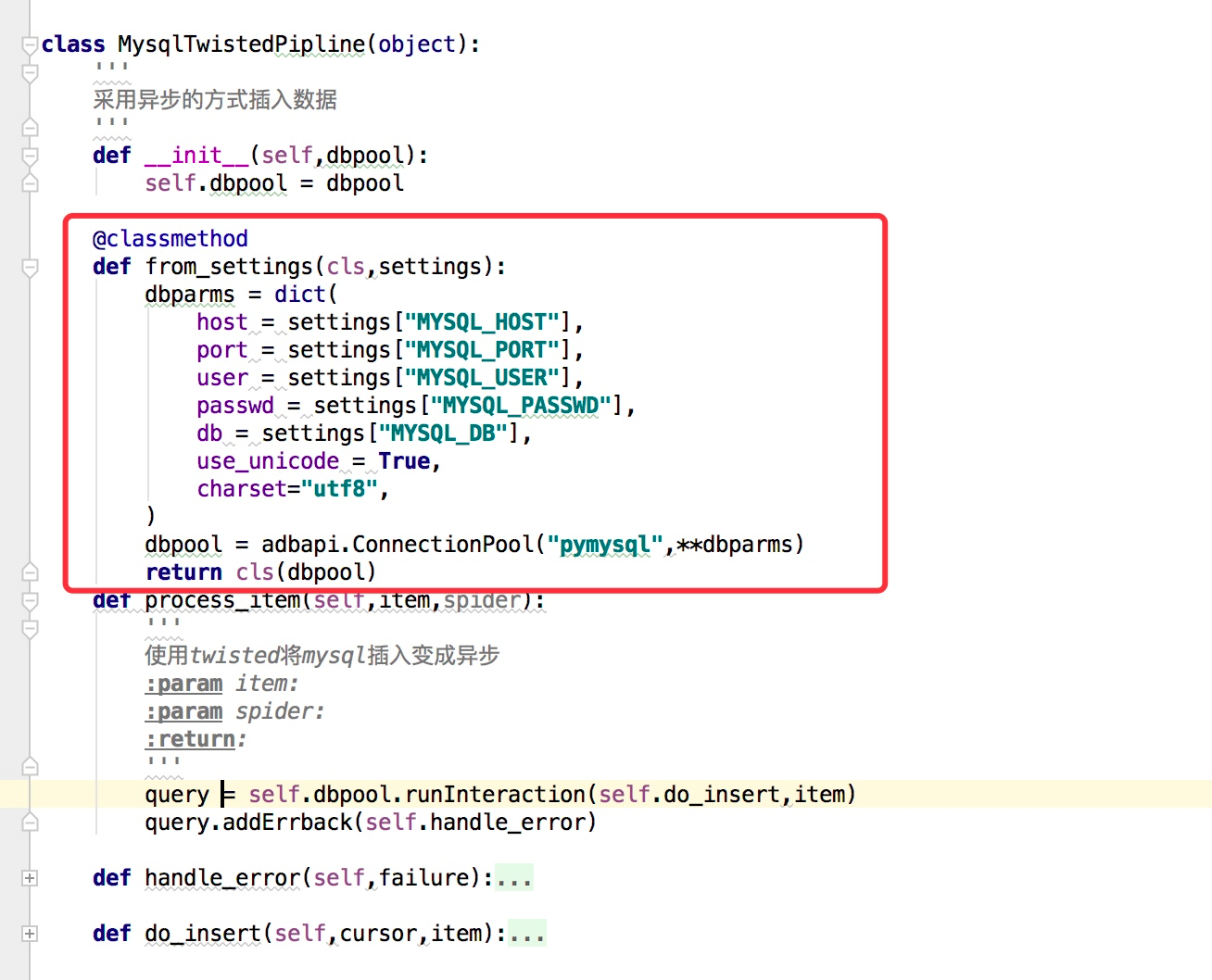
一些item pipeline的使用例子(官网说明)
例子1
这个例子实现的是判断 item中是否包含 price以及price_excludes_vat,如果存在则调整了price属性,都让 item['price'] = item['price'] * self.vat_factor,如果不存在则返回 DropItem
from scrapy.exceptions import DropItem
class PricePipeline(object):
vat_factor = 1.15
def process_item(self, item, spider):
if item['price']:
if item['price_excludes_vat']:
item['price'] = item['price'] * self.vat_factor
return item
else:
raise DropItem("Missing price in %s" % item)
例子2
这个例子是将item写入到json文件中
import json
class JsonWriterPipeline(object):
def __init__(self):
self.file = open('items.jl', 'wb')
def process_item(self, item, spider):
line = json.dumps(dict(item)) + "\n"
self.file.write(line)
return item
例子3
将 item写入到 MongoDB,同时这里演示了 from_crawler的用法
import pymongo
class MongoPipeline(object):
collection_name = 'scrapy_items'
def __init__(self, mongo_uri, mongo_db):
self.mongo_uri = mongo_uri
self.mongo_db = mongo_db
@classmethod
def from_crawler(cls, crawler):
return cls(
mongo_uri=crawler.settings.get('MONGO_URI'),
mongo_db=crawler.settings.get('MONGO_DATABASE', 'items')
)
def open_spider(self, spider):
self.client = pymongo.MongoClient(self.mongo_uri)
self.db = self.client[self.mongo_db]
def close_spider(self, spider):
self.client.close()
def process_item(self, item, spider):
self.db[self.collection_name].insert(dict(item))
return item
例子4:去重
一个用于去重的过滤器,丢弃那些已经被处理过的 item,假设item有一个唯一的id,但是我们spider返回的多个 item中包含了相同的 id,去重方法如下:这里初始化了一个集合,每次判断id是否在集合中已经存在,从而做到去重的功能
from scrapy.exceptions import DropItem
class DuplicatesPipeline(object):
def __init__(self):
self.ids_seen = set()
def process_item(self, item, spider):
if item['id'] in self.ids_seen:
raise DropItem("Duplicate item found: %s" % item)
else:
self.ids_seen.add(item['id'])
return item
启用一个item Pipeline组件
在settings配置文件中y9ou一个ITEM_PIPELINES的配置参数,例子如下:
ITEM_PIPELINES = {
'myproject.pipelines.PricePipeline': 300,
'myproject.pipelines.JsonWriterPipeline': 800,
}
每个pipeline后面有一个数值,这个数组的范围是0-1000,这个数值确定了他们的运行顺序,数字越小越优先。
6-----Scrapy框架中Item Pipeline用法的更多相关文章
- scrapy框架中Item Pipeline用法
scrapy框架中item pipeline用法 当Item 在Spider中被收集之后,就会被传递到Item Pipeline中进行处理 每个item pipeline组件是实现了简单的方法的pyt ...
- Python爬虫从入门到放弃(十六)之 Scrapy框架中Item Pipeline用法
当Item 在Spider中被收集之后,就会被传递到Item Pipeline中进行处理 每个item pipeline组件是实现了简单的方法的python类,负责接收到item并通过它执行一些行为, ...
- Python之爬虫(十八) Scrapy框架中Item Pipeline用法
当Item 在Spider中被收集之后,就会被传递到Item Pipeline中进行处理 每个item pipeline组件是实现了简单的方法的python类,负责接收到item并通过它执行一些行为, ...
- Scrapy框架中选择器的用法【转】
Python爬虫从入门到放弃(十四)之 Scrapy框架中选择器的用法 请给作者点赞 --> 原文链接 Scrapy提取数据有自己的一套机制,被称作选择器(selectors),通过特定的Xpa ...
- scrapy框架中Download Middleware用法
scrapy框架中Download Middleware用法 Downloader Middleware处理的过程主要在调度器发送requests请求的时候以及网页将response结果返回给sp ...
- scrapy框架中选择器的用法
scrapy框架中选择器的用法 Scrapy提取数据有自己的一套机制,被称作选择器(selectors),通过特定的Xpath或者CSS表达式来选择HTML文件的某个部分Xpath是专门在XML文件中 ...
- Scrapy框架中的Pipeline组件
简介 在下图中可以看到items.py与pipeline.py,其中items是用来定义抓取内容的实体:pipeline则是用来处理抓取的item的管道 Item管道的主要责任是负责处理有蜘蛛从网页中 ...
- Python爬虫从入门到放弃(十四)之 Scrapy框架中选择器的用法
Scrapy提取数据有自己的一套机制,被称作选择器(selectors),通过特定的Xpath或者CSS表达式来选择HTML文件的某个部分Xpath是专门在XML文件中选择节点的语言,也可以用在HTM ...
- Python之爬虫(十六) Scrapy框架中选择器的用法
Scrapy提取数据有自己的一套机制,被称作选择器(selectors),通过特定的Xpath或者CSS表达式来选择HTML文件的某个部分Xpath是专门在XML文件中选择节点的语言,也可以用在HTM ...
随机推荐
- 算法Sedgewick第四版-第1章基础-2.1Elementary Sortss-002插入排序法(Insertion sort)
一.介绍 1.时间和空间复杂度 运行过程 2.特点: (1)对于已排序或接近排好的数据,速度很快 (2)对于部分排好序的输入,速度快 二.代码 package algorithms.elementar ...
- JavaPersistenceWithHibernate第二版笔记-第六章-Mapping inheritance-006Mixing inheritance strategies(@SecondaryTable、@PrimaryKeyJoinColumn、<join fetch="select">)
一.结构 For example, you can map a class hierarchy to a single table, but, for a particular subclass, s ...
- php 函数追踪扩展 phptrace
php 函数追踪扩展 phptrace 介绍 phptrace 是一个低开销的用于跟踪.分析 php 运行情况的工具. 它可以跟踪 php 在运行时的函数调用.请求信息.执行流程.并且提供有过滤器.统 ...
- 原型模式与serializable
写原型模式时课件上有一个实现模式是利用可串行化接口实现,然后就发现那个代码(如下),串行化接口里面没有函数,这种接口被曾为标记接口,implements这个接口后就可以对其进行各种流操作了,其实就是O ...
- 2019年第十届蓝桥杯省赛总结(JavaA组)
//update3.28:省一rank4,莫名进了国赛好神奇.. 记yzm10第一次体验A组(纯粹瞎水). 早闻山东的JavaA组神仙打架,进国赛都成了奢望(往年只有五个名额),因此抱着做分母的心态来 ...
- 树莓派(Raspberry Pi 3) - 系统烧录及xshell连接
树莓派(Raspberry pi)是一块集成度极高的ARM开发板,不仅包含了HDMI,RCA,CSI,HDMI,GPIO等端口,还支持蓝牙以及无线通信.由于 Raspberry Pi 几乎是为 Lin ...
- Mac下的UI自动化测试 (四)
在实际写testcase的时候会使用unittest框架,但是在sikuli中需要使用它提供的command来运行,位于/Applications/SikuliX.app/run,使用-r参数指定要运 ...
- Algorithms - Quick Sort
印象 图2 快速排序过程 思想 通过一趟排序将待排记录分割成独立的两部分,其中一部分记录的关键字均比另一部分记录的关键字小,则可分别对这两部分记录继续进行排序,以达到整个序列有序的目的. 分析 稳定: ...
- codevs3027(dp)
题目链接: http://codevs.cn/problem/3027/ 题意: 中文题目诶~ 思路: dp 先给所有线段按照右端点值升序 sort 一下, 用 dp[i] 存储以第 i 条线段结尾的 ...
- docker与虚拟机性能比较(转)
http://blog.csdn.net/cbl709/article/details/43955687 本博客来源于我的个人博客: www.chenbiaolong.com 欢迎访问. 概要 doc ...