基于单层决策树的AdaBoost算法原理+python实现
这里整理一下实验课实现的基于单层决策树的弱分类器的AdaBoost算法。
由于是初学,实验课在找资料的时候看到别人的代码中有太多英文的缩写,不容易看懂,而且还要同时看代码实现的细节、算法的原理什么的,就体验很不好。
于是我这里代码中英文没有用缩写,也尽量把思路写清楚。
基本概念
集成学习:通过组合多个基分类器(base classifier)来完成学习任务,基分类器一般采用弱学习器。
弱学习器:只学习正确率仅仅略优于随机猜测的学习器。通过集成方法,就能组合成一个强学习器。
Bagging和Boosting:集成学习主要的两种把弱分类器组装成强分类器的方法。
AdaBoost是adaptive boosting的缩写。
Bagging:从原始数据集中有放回地抽训练集,每轮训练集之间是独立的。每次使用一个训练集得到一个模型。分类问题就让这些模型投票得到分类结果,回归问题就算这些模型的均值。
Boosting:每一轮的训练集不变,只是训练集中每个样本在分类器中的权重发生变化,并且每一轮的样本的权重分布依赖上一轮的分类结果。每个弱分类器也都有各自的权重,分类误差小的分类器有更大的权重。
举个例子:Bagging+决策树=随机森林;Boosting+决策树=提升树
AdaBoost:计算样本权重->计算错误率->计算弱学习器的权重->更新样本权重...重复。
原理+代码实现
就是构造弱分类器,再根据一定方法组装起来。
from numpy import *
加载数据集
用的是实验课给的数据集(horseColic 马疝病数据集)...这部分不多说了。带_array后缀的是列表,带_matrix后缀的是把相应array变成的np矩阵。
def load_dataset(filename):
num_feature = len(open(filename).readline().split('\t'))
data_array = []
label_array = []
f = open(filename)
for line in f.readlines():
line_array = []
current_line = line.strip().split('\t')
for i in range(num_feature - 1):
line_array.append(float(current_line[i]))
data_array.append(line_array)
label_array.append(float(current_line[-1]))
return data_array, label_array
基于单层决策树构建弱分类器
1、废话文学一下,stump的意思是树桩,单层决策树就是只有一层的决策树,就是简单的通过大于和小于根据阈值(threshold)把数据分为两堆。在阈值一边的数据被分到类别-1,另一边分到类别1。
def stump_classify(data_matrix, dimension, threshold, inequality_sign):
# dimension是数据集第dimension维的特征,对应data_matrix的第dimension列
return_array = ones((shape(data_matrix)[0], 1))
if inequality_sign == 'less_than':
return_array[data_matrix[:, dimension] <= threshold] = -1.0
else:
return_array[data_matrix[:, dimension] > threshold] = -1.0
return return_array
2、遍历上面stump_classify函数所有可能的输入值,找到最佳的单层决策树(给定权重向量d时所得到的最佳单层决策树)。best_stump就是最佳的单层决策树,一个字典,里面存放这个单层决策树的'dimension'(上一段代码注释)、'threshold'(阈值)、'inequality_sign'(不等号,less_than和greater_than)。
结合代码和注释看即可。
def build_stump(data_array, class_labels, d):
data_matrix = mat(data_array)
label_matrix = mat(class_labels).T
m, n = shape(data_matrix)
num_steps = 10.0
best_stump = {} # 用于存放给定权重向量d时所得到的最佳单层决策树的相关信息
best_class_estimate = mat(zeros((m, 1)))
'''
将最小错误率min_error设为inf
对数据集中的每一个特征(第一层循环):
对每一个步长(第二层循环):
对每一个不等号(第三层循环):
建立一棵单层决策树并利用加权数据集对它进行测试
如果错误率低于min_error,则将当前单层决策树设为最佳单层决策树
返回最佳单层决策树
'''
min_error = inf
for i in range(n):
range_min = data_matrix[:, i].min()
range_max = data_matrix[:, i].max()
step_size = (range_max - range_min) / num_steps
for j in range(-1, int(num_steps) + 1):
for inequality_sign in ['less_than', 'greater_than']:
threshold = (range_min + float(j) * step_size)
predicted_values = stump_classify(data_matrix, i, threshold, inequality_sign) # 调用stump_classify函数来得到预测结果
error_array = mat(ones((m, 1))) # 这是一个与分类预测结果相同长度的列向量,如果predicted_values中的值不等于label_matrix中的标签值,对应位置就为1,否则为0.
error_array[predicted_values == label_matrix] = 0
weighted_error = d.T * error_array # 这个是加权错误率,这个将用来更新权重向量d
if weighted_error < min_error:
min_error = weighted_error
best_class_estimate = predicted_values.copy()
best_stump['dimension'] = i
best_stump['threshold'] = threshold
best_stump['inequality_sign'] = inequality_sign
return best_stump, min_error, best_class_estimate
加权错误率weighted_error是与AdaBoost交互的地方,每次用于更新权重向量d.
Adaboost的训练过程和分类
训练
训练出来的返回值是: weak_classifier_array, aggregate_class_estimate,一个存放了很多弱分类器的数组和集成学习的类别估计值。
于是思路是,对于每次迭代:利用build_stump找到最佳的单层决策树;把这个最佳单层决策树放进弱分类器数组;利用错误率计算弱分类器的权重α;更新权重向量d;更新集成学习的类别估计值;更新错误率。
里面出现的公式:
错误率:

利用错误率计算弱分类器的权重α:
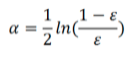
可见错误率ε越高,这个分类器的权重就越小。代码中:
alpha = float(0.5 * log((1.0 - error) / max([error, 1e-16])))
(注:max函数里面加中括号是因为之前from numpy import *了,这个max是np.amax,不加中括号会有一个warning.)
- 更新权重向量d:就是使被分错的样本在接下来学习中可以重点对其进行学习。
第i个样本分类正确就是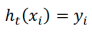
,Zt是sum(D)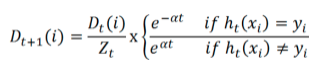
上面公式浅看一下,编程是对着化简合并后的公式来的:
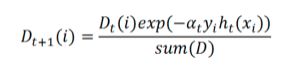
代码中:
exp的指数:exponent = multiply(-1 * alpha * mat(class_labels).T, class_estimate)
d:d = multiply(d, exp(exponent))和d = d / d.sum()
- 集成学习的类别估计值(aggregate_class_estimate)就是把每个弱分类器给出的估计值按照每个弱分类器的权重累加起来。代码中是在一个循环里:
aggregate_class_estimate += alpha * class_estimate
下面直接放代码应该就很清楚了:
def ada_boost_train_decision_stump(data_array, class_labels, num_iteration=40):
weak_classifier_array = []
m = shape(data_array)[0]
d = mat(ones((m, 1)) / m)
aggregate_class_estimate = mat(zeros((m, 1)))
for i in range(num_iteration):
best_stump, error, class_estimate = build_stump(data_array, class_labels, d) # 利用build_stump找到最佳单层决策树
alpha = float(0.5 * log((1.0 - error) / max([error, 1e-16]))) # 算α
best_stump['alpha'] = alpha
weak_classifier_array.append(best_stump) # 把这个最佳单层决策树扔进弱分类器数组
exponent = multiply(-1 * alpha * mat(class_labels).T, class_estimate) # 算d
d = multiply(d, exp(exponent))
d = d / d.sum()
aggregate_class_estimate += alpha * class_estimate # 算集成学习的类别估计值
aggregate_errors = multiply(sign(aggregate_class_estimate) != mat(class_labels).T, ones((m, 1)))
error_rate = aggregate_errors.sum() / m
if error_rate == 0.0: # 如果错误率为0了就退出循环
break
return weak_classifier_array, aggregate_class_estimate
分类
就是写个循环,把上面得到的弱分类器数组里面每个弱分类器的放进stump_classify函数里面跑一遍,根据每个的权重把结果累加起来即可。
def ada_boost_classify(data_array, classifier_array):
data_matrix = mat(data_array)
m = shape(data_matrix)[0]
aggregate_class_estimate = mat(zeros((m, 1)))
for i in range(len(classifier_array)):
class_estimate = stump_classify(data_matrix,
classifier_array[i]['dimension'],
classifier_array[i]['threshold'],
classifier_array[i]['inequality_sign'])
aggregate_class_estimate += classifier_array[i]['alpha'] * class_estimate
return sign(aggregate_class_estimate)
以上就是实现过程了。下面再放上比较正规的伪代码:

完整代码
from numpy import *
def load_dataset(filename):
num_feature = len(open(filename).readline().split('\t'))
data_array = []
label_array = []
f = open(filename)
for line in f.readlines():
line_array = []
current_line = line.strip().split('\t')
for i in range(num_feature - 1):
line_array.append(float(current_line[i]))
data_array.append(line_array)
label_array.append(float(current_line[-1]))
return data_array, label_array
def stump_classify(data_matrix, dimension, threshold, inequality_sign):
return_array = ones((shape(data_matrix)[0], 1))
if inequality_sign == 'less_than':
return_array[data_matrix[:, dimension] <= threshold] = -1.0
else:
return_array[data_matrix[:, dimension] > threshold] = -1.0
return return_array
def build_stump(data_array, class_labels, d):
data_matrix = mat(data_array)
label_matrix = mat(class_labels).T
m, n = shape(data_matrix)
num_steps = 10.0
best_stump = {}
best_class_estimate = mat(zeros((m, 1)))
min_error = inf
for i in range(n):
range_min = data_matrix[:, i].min()
range_max = data_matrix[:, i].max()
step_size = (range_max - range_min) / num_steps
for j in range(-1, int(num_steps) + 1):
for inequality_sign in ['less_than', 'greater_than']:
threshold = (range_min + float(j) * step_size)
predicted_values = stump_classify(data_matrix, i, threshold, inequality_sign)
error_array = mat(ones((m, 1)))
error_array[predicted_values == label_matrix] = 0
weighted_error = d.T * error_array
if weighted_error < min_error:
min_error = weighted_error
best_class_estimate = predicted_values.copy()
best_stump['dimension'] = i
best_stump['threshold'] = threshold
best_stump['inequality_sign'] = inequality_sign
return best_stump, min_error, best_class_estimate
def ada_boost_train_decision_stump(data_array, class_labels, num_iteration=40):
weak_classifier_array = []
m = shape(data_array)[0]
d = mat(ones((m, 1)) / m)
aggregate_class_estimate = mat(zeros((m, 1)))
for i in range(num_iteration):
best_stump, error, class_estimate = build_stump(data_array, class_labels, d)
alpha = float(0.5 * log((1.0 - error) / max([error, 1e-16])))
best_stump['alpha'] = alpha
weak_classifier_array.append(best_stump)
exponent = multiply(-1 * alpha * mat(class_labels).T, class_estimate)
d = multiply(d, exp(exponent))
d = d / d.sum()
aggregate_class_estimate += alpha * class_estimate
aggregate_errors = multiply(sign(aggregate_class_estimate) != mat(class_labels).T, ones((m, 1)))
error_rate = aggregate_errors.sum() / m
if error_rate == 0.0:
break
return weak_classifier_array, aggregate_class_estimate
def ada_boost_classify(data_array, classifier_array):
data_matrix = mat(data_array)
m = shape(data_matrix)[0]
aggregate_class_estimate = mat(zeros((m, 1)))
for i in range(len(classifier_array)):
class_estimate = stump_classify(data_matrix,
classifier_array[i]['dimension'],
classifier_array[i]['threshold'],
classifier_array[i]['inequality_sign'])
aggregate_class_estimate += classifier_array[i]['alpha'] * class_estimate
return sign(aggregate_class_estimate)
def main():
data_array, label_array = load_dataset('AdaBoost/horseColicTraining2.txt')
weak_classier_array, aggregate_class_estimate = ada_boost_train_decision_stump(data_array, label_array, 40)
test_array, test_label_array = load_dataset('AdaBoost/horseColicTest2.txt')
print(weak_classier_array)
predictions = ada_boost_classify(data_array, weak_classier_array)
error_array = mat(ones((len(data_array), 1)))
print('error rate of training set: %.3f%%'
% float(error_array[predictions != mat(label_array).T].sum() / len(data_array) * 100))
predictions = ada_boost_classify(test_array, weak_classier_array)
error_array = mat(ones((len(test_array), 1)))
print('error rate of test set: %.3f%%'
% float(error_array[predictions != mat(test_label_array).T].sum() / len(test_array) * 100))
if __name__ == '__main__':
main()
输出是:前面是训练得到的弱分类器,后面是错误率。
[{'dimension': 9, 'threshold': 3.0, 'inequality_sign': 'greater_than', 'alpha': 0.4616623792657674}, {'dimension': 17, 'threshold': 52.5, 'inequality_sign': 'greater_than', 'alpha': 0.31248245042467104}, {'dimension': 3, 'threshold': 55.199999999999996, 'inequality_sign': 'greater_than', 'alpha': 0.2868097320169572}, {'dimension': 18, 'threshold': 62.300000000000004, 'inequality_sign': 'less_than', 'alpha': 0.23297004638939556}, {'dimension': 10, 'threshold': 0.0, 'inequality_sign': 'less_than', 'alpha': 0.19803846151213728}, {'dimension': 5, 'threshold': 2.0, 'inequality_sign': 'greater_than', 'alpha': 0.1884788734902058}, {'dimension': 12, 'threshold': 1.2, 'inequality_sign': 'less_than', 'alpha': 0.1522736899747682}, {'dimension': 7, 'threshold': 1.2, 'inequality_sign': 'greater_than', 'alpha': 0.15510870821690584}, {'dimension': 5, 'threshold': 0.0, 'inequality_sign': 'less_than', 'alpha': 0.1353619735335944}, {'dimension': 4, 'threshold': 28.799999999999997, 'inequality_sign': 'less_than', 'alpha': 0.12521587326132164}, {'dimension': 11, 'threshold': 2.0, 'inequality_sign': 'greater_than', 'alpha': 0.13347648128207715}, {'dimension': 9, 'threshold': 4.0, 'inequality_sign': 'less_than', 'alpha': 0.14182243253771004}, {'dimension': 14, 'threshold': 0.0, 'inequality_sign': 'greater_than', 'alpha': 0.10264268449708018}, {'dimension': 0, 'threshold': 1.0, 'inequality_sign': 'less_than', 'alpha': 0.11883732872109554}, {'dimension': 4, 'threshold': 19.2, 'inequality_sign': 'greater_than', 'alpha': 0.09879216527106725}, {'dimension': 2, 'threshold': 36.72, 'inequality_sign': 'less_than', 'alpha': 0.12029960885056902}, {'dimension': 3, 'threshold': 92.0, 'inequality_sign': 'less_than', 'alpha': 0.10846927663989149}, {'dimension': 15, 'threshold': 0.0, 'inequality_sign': 'less_than', 'alpha': 0.09652967982091365}, {'dimension': 3, 'threshold': 73.6, 'inequality_sign': 'greater_than', 'alpha': 0.08958515309272022}, {'dimension': 18, 'threshold': 8.9, 'inequality_sign': 'less_than', 'alpha': 0.0921036196127237}, {'dimension': 16, 'threshold': 4.0, 'inequality_sign': 'greater_than', 'alpha': 0.10464142217079568}, {'dimension': 11, 'threshold': 3.2, 'inequality_sign': 'less_than', 'alpha': 0.09575457291711578}, {'dimension': 20, 'threshold': 0.0, 'inequality_sign': 'greater_than', 'alpha': 0.09624217440331542}, {'dimension': 17, 'threshold': 37.5, 'inequality_sign': 'less_than', 'alpha': 0.07859662885189661}, {'dimension': 9, 'threshold': 2.0, 'inequality_sign': 'less_than', 'alpha': 0.07142863634550768}, {'dimension': 5, 'threshold': 2.0, 'inequality_sign': 'greater_than', 'alpha': 0.07830753154662261}, {'dimension': 4, 'threshold': 28.799999999999997, 'inequality_sign': 'less_than', 'alpha': 0.07606159074712755}, {'dimension': 4, 'threshold': 19.2, 'inequality_sign': 'greater_than', 'alpha': 0.08306752811081908}, {'dimension': 7, 'threshold': 4.2, 'inequality_sign': 'greater_than', 'alpha': 0.08304167411411778}, {'dimension': 3, 'threshold': 92.0, 'inequality_sign': 'less_than', 'alpha': 0.08893356802801176}, {'dimension': 14, 'threshold': 3.0, 'inequality_sign': 'greater_than', 'alpha': 0.07000509315417822}, {'dimension': 7, 'threshold': 5.3999999999999995, 'inequality_sign': 'less_than', 'alpha': 0.07697582358566012}, {'dimension': 18, 'threshold': 0.0, 'inequality_sign': 'less_than', 'alpha': 0.08507457442866745}, {'dimension': 5, 'threshold': 3.2, 'inequality_sign': 'less_than', 'alpha': 0.06765903873020729}, {'dimension': 7, 'threshold': 3.0, 'inequality_sign': 'greater_than', 'alpha': 0.08045680822237077}, {'dimension': 12, 'threshold': 1.2, 'inequality_sign': 'less_than', 'alpha': 0.05616862921969537}, {'dimension': 11, 'threshold': 2.0, 'inequality_sign': 'greater_than', 'alpha': 0.06454264376249834}, {'dimension': 7, 'threshold': 5.3999999999999995, 'inequality_sign': 'less_than', 'alpha': 0.053088884353829344}, {'dimension': 11, 'threshold': 0.0, 'inequality_sign': 'less_than', 'alpha': 0.07346058614788575}, {'dimension': 13, 'threshold': 0.0, 'inequality_sign': 'greater_than', 'alpha': 0.07872267320907471}]
error rate of training set: 19.732%
error rate of test set: 19.403%
基于单层决策树的AdaBoost算法原理+python实现的更多相关文章
- 基于单层决策树的AdaBoost算法源码
基于单层决策树的AdaBoost算法源码 Mian.py # -*- coding: utf-8 -*- # coding: UTF-8 import numpy as np from AdaBoos ...
- 集成学习值Adaboost算法原理和代码小结(转载)
在集成学习原理小结中,我们讲到了集成学习按照个体学习器之间是否存在依赖关系可以分为两类: 第一个是个体学习器之间存在强依赖关系: 另一类是个体学习器之间不存在强依赖关系. 前者的代表算法就是提升(bo ...
- AdaBoost算法原理简介
AdaBoost算法原理 AdaBoost算法针对不同的训练集训练同一个基本分类器(弱分类器),然后把这些在不同训练集上得到的分类器集合起来,构成一个更强的最终的分类器(强分类器).理论证明,只要每个 ...
- 集成学习之Adaboost算法原理
在boosting系列算法中,Adaboost是最著名的算法之一.Adaboost既可以用作分类,也可以用作回归. 1. boosting算法基本原理 集成学习原理中,boosting系列算法的思想:
- 集成学习之Adaboost算法原理小结
在集成学习原理小结中,我们讲到了集成学习按照个体学习器之间是否存在依赖关系可以分为两类,第一个是个体学习器之间存在强依赖关系,另一类是个体学习器之间不存在强依赖关系.前者的代表算法就是是boostin ...
- 机器学习之Adaboost算法原理
转自:http://www.cnblogs.com/pinard/p/6133937.html 在集成学习原理小结中,我们讲到了集成学习按照个体学习器之间是否存在依赖关系可以分为两类,第一个是个体学习 ...
- 基于单决策树的AdaBoost
①起源:Boosting算法 Boosting算法的目的是每次基于全部数据集,通过使用同一种分类器不同的抽取参数方法(如决策树,每次都可以抽取不同的特征维度来剖分数据集) 训练一些不同弱分类器(单次分 ...
- AdaBoost算法原理及OpenCV实例
备注:OpenCV版本 2.4.10 在数据的挖掘和分析中,最基本和首要的任务是对数据进行分类,解决这个问题的常用方法是机器学习技术.通过使用已知实例集合中所有样本的属性值作为机器学习算法的训练集,导 ...
- AdaBoost 算法原理及推导
AdaBoost(Adaptive Boosting):自适应提升方法. 1.AdaBoost算法介绍 AdaBoost是Boosting方法中最优代表性的提升算法.该方法通过在每轮降低分对样例的权重 ...
随机推荐
- ASP.NET Web 应用 Docker踩坑历程
听说Docker这玩意挺长时间了,新建Web应用的时候,也注意到有个启用Docker的选项. 前两天扫了一眼<[大话云原生]煮饺子与docker.kubernetes之间的关系>,觉得有点 ...
- 攻防世界-MISC:János-the-Ripper
这是攻防世界MISC高手进阶区的题目: 点击下载附件一,解压后得到一个没有后缀的文件,老规矩用010editor打开,发现存在一个flag.txt文件 用foremost分离一下: flag.txt被 ...
- Linux vs Unix - Linux与Unix到底有什么不同?
来自:Linux迷链接:https://www.linuxmi.com/linux-vs-unix.html Linux和Unix这两个术语可以互换地用来指同一操作系统.这在很大程度上是由于他们惊人的 ...
- 739. Daily Temperatures - LeetCode
Question 739. Daily Temperatures Solution 题目大意:比今天温度还要高还需要几天 思路:笨方法实现,每次遍历未来几天,比今天温度高,就坐标减 Java实现: p ...
- Java高并发-概念
一.为什么需要并行 业务要求 http处理多个客户端请求 java虚拟机启动多个线程 进程开销比线程大的多 性能 多线程在多核系统比单线程要好的多 摩尔定律失效 二.几个重要概念 2.1 同步和异步 ...
- Git分离头指针
Git头指针 Git中有HEAD头指针的概念.HEAD头指针通常指向某个分支的最近一次提交,但我们也可以改变它的指向,使其指向某个commit,此时处于分离头指针的状态. 如下,改变HEAD的指向,g ...
- [CSP-S 2019 Day2]Emiya家今天的饭
思路: 这种题目就考我们首先想到一个性质.这题其实容易想到:超限的菜最多只有一个,再加上这题有容斥那味,就枚举超限的菜然后dp就做完了. 推式子能力还是不行,要看题解. 式子还需要一个优化,就是废除冗 ...
- 可变参数——JavaSE基础
可变参数 方法声明中,在指定参数类型后加一个省略号...即可声明可变参数 可变参数必须是参数列表的最后一个参数 声明 public void test(int... i){ System.out.pr ...
- BI 如何让SaaS产品具有 “安全感”和“敏锐感”(上)
SaaS模式一经推出,凭借自身的高性价比.低维护成本,无需软硬件维护.无需运维等明晃晃的优点,得到了爆发式的增长,甚至全面改变了软件的开发模式.各位老总的问候语,不知从什么时候开始,都变成了:&quo ...
- CentOS6.5修改镜像源问题
千呼万唤使出来阿,随着centos版本不断地更新好多镜像源已经被放弃了治疗,尤其是低版本的centos,下面以CentOS6.5为例进行刨析吧! 上干货: 配置文件 vi /etc/yum.repos ...