Spark RDD概念学习系列之RDD的依赖关系(宽依赖和窄依赖)(三)
RDD的依赖关系?
RDD和它依赖的parent RDD(s)的关系有两种不同的类型,即窄依赖(narrow dependency)和宽依赖(wide dependency)。
1)窄依赖指的是每一个parent RDD的Partition最多被子RDD的一个Partition使用,如图1所示。
2)宽依赖指的是多个子RDD的Partition会依赖同一个parent RDD的Partition,如图2所示。
RDD作为数据结构,本质上是一个只读的分区记录集合。一个RDD可以包含多个分区,每个分区就是一个dataset片段。RDD可以相互依赖。
1)如果RDD的每个分区最多只能被一个Child RDD的一个分区使用,则称之为narrow dependency。
2)如果多个Child RDD分区都可以依赖,则称之为wide / shuffle dependency 。
Spark之所以将依赖分为narrow 和 shuffle / wide 。基于两点原因
1、首先,narrow dependencies可以支持在同一个cluster node上,以pipeline形式执行多条命令,例如在执行了map后,紧接着执行filter。
相反,shuffle / wide dependencies 需要所有的父分区都是可用的,可能还需要调用类似MapReduce之类的操作进行跨节点传递。
2、其次,则是从失败恢复的角度考虑。 narrow dependencies的失败恢复更有效,因为它只需要重新计算丢失的parent partition即可,而且可以并行地在不同节点进行重计算。
相反,shuffle / wide dependencies 牵涉RDD各级的多个parent partition。
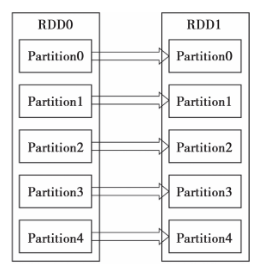
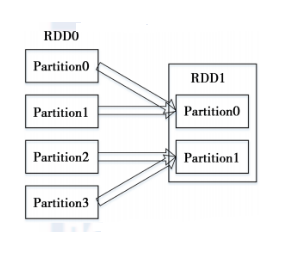
图 1 RDD的窄依赖 图 2 RDD的宽依赖
接下来可以从不同类型的转换来进一步理解RDD的窄依赖和宽依赖的区别,如图3所示。
对于map和filter形式的转换来说,它们只是将Partition的数据根据转换的规则进行转化,并不涉及其他的处理,可以简单地认为只是将数据从一个形式转换到另一个形式。对于union,只是将多个RDD合并成一个,parent RDD的Partition(s)不会有任何的变化,可以认为只是把parent RDD的Partition(s)简单进行复制与合并。对于join,如果每个Partition仅仅和已知的、特定的Partition进行join,那么这个依赖关系也是窄依赖。对于这种有规则的数据的join,并不会引入昂贵的Shuffle。对于窄依赖,由于RDD每个Partition依赖固定数量的parent RDD(s)的Partition(s),因此可以通过一个计算任务来处理这些Partition,并且这些Partition相互独立,这些计算任务也就可以并行执行了。
对于groupByKey,子RDD的所有Partition(s)会依赖于parent RDD的所有Partition(s),子RDD的Partition是parent RDD的所有Partition Shuffle的结果,因此这两个RDD是不能通过一个计算任务来完成的。同样,对于需要parent RDD的所有Partition进行join的转换,也是需要Shuffle,这类join的依赖就是宽依赖而不是前面提到的窄依赖了。
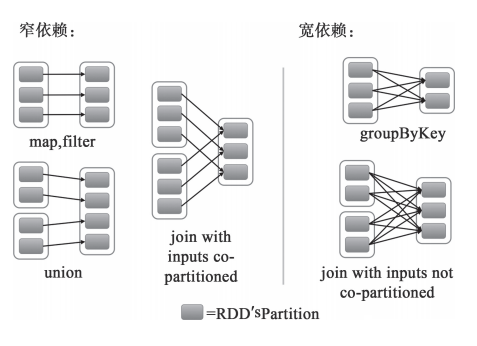
不同的操作依据其特性,可能会产生不同的依赖。例如map、filter操作会产生 narrow dependency 。reduceBykey操作会产生 wide / shuffle dependency。
通俗点来说,RDD的每个Partition,仅仅依赖于父RDD中的一个Partition,这才是窄。 就这么简单!
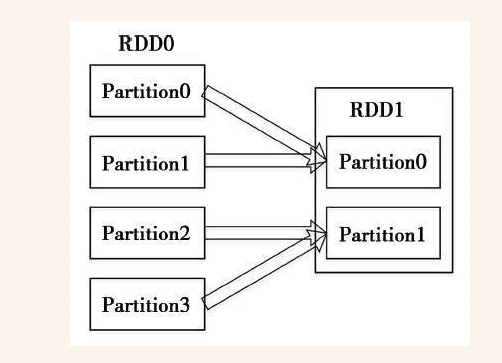
我以前总感觉这是窄依赖,其实 Rdd1的partition0依赖父Rdd0的 partition0和partition1,所以是宽依赖!
所有的依赖都要实现trait Dependency[T]:
abstract class Dependency[T] extends Serializable { def rdd: RDD[T]}其中rdd就是依赖的parent RDD。对于窄依赖的实现是:abstract class NarrowDependency[T](_rdd: RDD[T]) extends Dependency[T] { //返回子RDD的partitionId依赖的所有的parent RDD的Partition(s) def getParents(partitionId: Int): Seq[Int] override def rdd: RDD[T] = _rdd}现在有两种窄依赖的具体实现,一种是一对一的依赖,即OneToOneDependency:class OneToOneDependency[T](rdd: RDD[T]) extends NarrowDependency[T](rdd) { override def getParents(partitionId: Int) = List(partitionId)还有一个是范围的依赖,即RangeDependency,它仅仅被org.apache.spark.rdd.UnionRDD使用。UnionRDD是把多个RDD合成一个RDD,这些RDD是被拼接而成,即每个parent RDD的Partition的相对顺序不会变,只不过每个parent RDD在UnionRDD中的Partition的起始位置不同。因此它的getPartents如下:
override def getParents(partitionId: Int) = { if(partitionId >= outStart && partitionId < outStart + length) { List(partitionId - outStart + inStart) } else { Nil }}其中,inStart是parent RDD中Partition的起始位置,outStart是在UnionRDD中的起始位置,length就是parent RDD中Partition的数量。
对于宽依赖的实现是:
宽依赖的实现只有一种:ShuffleDependency。子RDD依赖于parent RDD的所有Partition,因此需要Shuffle过程:
class ShuffleDependency[K, V, C]( @transient _rdd: RDD[_ <: Product2[K, V]], val partitioner: Partitioner, val serializer: Option[Serializer] = None, val keyOrdering: Option[Ordering[K]] = None, val aggregator: Option[Aggregator[K, V, C]] = None, val mapSideCombine: Boolean = false)extends Dependency[Product2[K, V]] {override def rdd = _rdd.asInstanceOf[RDD[Product2[K, V]]]//获取新的shuffleIdval shuffleId: Int = _rdd.context.newShuffleId()//向ShuffleManager注册Shuffle的信息val shuffleHandle: ShuffleHandle =_rdd.context.env.shuffleManager.registerShuffle( shuffleId, _rdd.partitions.size, this) _rdd.sparkContext.cleaner.foreach(_.registerShuffleForCleanup(this))}Spark RDD概念学习系列之RDD的依赖关系(宽依赖和窄依赖)(三)的更多相关文章
- Spark RDD概念学习系列之rdd的依赖关系彻底解密(十九)
本期内容: 1.RDD依赖关系的本质内幕 2.依赖关系下的数据流视图 3.经典的RDD依赖关系解析 4.RDD依赖关系源码内幕 1.RDD依赖关系的本质内幕 由于RDD是粗粒度的操作数据集,每个Tra ...
- Spark RDD概念学习系列之RDD的转换(十)
RDD的转换 Spark会根据用户提交的计算逻辑中的RDD的转换和动作来生成RDD之间的依赖关系,同时这个计算链也就生成了逻辑上的DAG.接下来以“Word Count”为例,详细描述这个DAG生成的 ...
- Spark RDD概念学习系列之RDD的checkpoint(九)
RDD的检查点 首先,要清楚.为什么spark要引入检查点机制?引入RDD的检查点? 答:如果缓存丢失了,则需要重新计算.如果计算特别复杂或者计算耗时特别多,那么缓存丢失对于整个Job的影响是不容 ...
- Spark RDD概念学习系列之RDD的5大特点(五)
RDD的5大特点 1)有一个分片列表,就是能被切分,和Hadoop一样,能够切分的数据才能并行计算. 一组分片(partition),即数据集的基本组成单位,对于RDD来说,每个分片都会被一个计 ...
- Spark RDD概念学习系列之RDD是什么?(四)
RDD是什么? 通俗地理解,RDD可以被抽象地理解为一个大的数组(Array),但是这个数组是分布在集群上的.详细见 Spark的数据存储 Spark的核心数据模型是RDD,但RDD是个抽象类 ...
- Spark RDD概念学习系列之RDD的容错机制(十七)
RDD的容错机制 RDD实现了基于Lineage的容错机制.RDD的转换关系,构成了compute chain,可以把这个compute chain认为是RDD之间演化的Lineage.在部分计算结果 ...
- Spark RDD概念学习系列之RDD的缓存(八)
RDD的缓存 RDD的缓存和RDD的checkpoint的区别 缓存是在计算结束后,直接将计算结果通过用户定义的存储级别(存储级别定义了缓存存储的介质,现在支持内存.本地文件系统和Tachyon) ...
- Spark RDD概念学习系列之RDD的操作(七)
RDD的操作 RDD支持两种操作:转换和动作. 1)转换,即从现有的数据集创建一个新的数据集. 2)动作,即在数据集上进行计算后,返回一个值给Driver程序. 例如,map就是一种转换,它将数据集每 ...
- Spark RDD概念学习系列之RDD的缺点(二)
RDD的缺点? RDD是Spark最基本也是最根本的数据抽象,它具备像MapReduce等数据流模型的容错性,并且允许开发人员在大型集群上执行基于内存的计算. 为了有效地实现容错,(详细见ht ...
随机推荐
- Maven3路程(五)用Maven创建Hibernate项目
本文将用Maven3.Hibernate3.6.Oracle10g整合,作为例子. 环境清单: 1.Maven3.0.5 2.Hibernate3.6.5 Final 3.JDK1.7.0.11 4. ...
- dom4j API使用简介
dom4j API使用简介 功能简介 dom4j是一个Java的XML API,类似于jdom,用来读写XML文件的.dom4j是一个非常非常优秀的Java XML API,具有性能优异.功能强大和极 ...
- delete-node-in-a-bst
https://leetcode.com/problems/delete-node-in-a-bst/ /** * Definition for a binary tree node. * struc ...
- DataGridView 相关操作
一.单元格内容的操作// 取得当前单元格内容 Console.WriteLine(DataGridView1.CurrentCell.Value); // 取得当前单元格的列 Index Consol ...
- ORG 07C00H的意思
简单说来,该指令用来修正该指令以后出现的(变量/标志的)内存地址,也就是说如果有ORG 0x12345h,那么在该指令以后的变量的地址将被修正为0x12345+old_addr.对于DOS中的COM文 ...
- HDU 1513 Palindrome
题目就是给一个字符串问最少插入多少个字符能让原字符串变为回文字符串. 算法: 用原串的长度减去原串与翻转后的串的最大公共字串的长度,就是所求答案. //#define LOCAL #include & ...
- 51nod1537 分解
http://blog.csdn.net/qingshui23/article/details/52350523 详细题解%%%%对矩阵乘法的不熟悉.以及不会推公式 #include<cstdi ...
- 七:zookeeper与paxos的分析
zookeeper是什么 官方说辞:Zookeeper 分布式服务框架是Apache Hadoop 的一个子项目,它主要是用来解决分布式应用中经常遇到的一些数据管理问题,如:统一命名服务.状态同步服务 ...
- 【转】在Source Insight中看Python代码
原文网址:http://www.cnblogs.com/xuxm2007/archive/2010/09/02/1815695.html SI是个很强大的代码查看修改工具,以前用来看C,C++都是相当 ...
- 扩容盘、SD卡扩容
内存卡的前世今生回想当年,大家都还在用着非智能机,由于功能单一,需要存储的数据也就是通讯录和短信.虽然那时也有手机游戏,但大多都是几十KB,并不需要太大的存储空间.但随着手机功能的多样化,尤其是音乐. ...