scrapy框架爬取开源中国项目大厅所有的发布项目。
本文爬取的字段,项目名称,发布时间,项目周期,应用领域,最低报价,最高报价,技术类型
1,items中定义爬取字段。
import scrapy class KaiyuanzhongguoItem(scrapy.Item):
# define the fields for your item here like:
# name = scrapy.Field()
name = scrapy.Field()
publishTime = scrapy.Field()
cycle = scrapy.Field()
application = scrapy.Field()
budgetMinByYuan = scrapy.Field()
budgetMaxByYuan = scrapy.Field()
ski = scrapy.Field()
2, 爬虫主程序
# -*- coding: utf-8 -*-
import scrapy
import json
from kaiyuanzhongguo.items import KaiyuanzhongguoItem
class KyzgSpider(scrapy.Spider):
name = 'kyzg'
# allowed_domains = ['www.xxx.com']
base_url = 'https://zb.oschina.net/project/contractor-browse-project-and-reward?pageSize=10¤tPage='
start_urls = ['https://zb.oschina.net/project/contractor-browse-project-and-reward?pageSize=10¤tPage=1']
def parse(self, response):
result = json.loads(response.text)
totalpage = result['data']['totalPage']
for res in result['data']['data']:
item = KaiyuanzhongguoItem()
item['name'] = res['name']
item['publishTime'] = res['publishTime']
item['cycle'] = res['cycle']
item['application'] = res['application']
item['budgetMinByYuan'] = res['budgetMinByYuan']
item['budgetMaxByYuan'] = res['budgetMaxByYuan']
skillList = res['skillList']
skill = []
item['ski'] = ''
if skillList:
for sk in skillList:
skill.append(sk['value'])
item['ski'] = ','.join(skill)
yield item
for i in range(2,totalpage+1):
url_info = self.base_url+str(i)
yield scrapy.Request(url=url_info,callback=self.parse)
3,数据库设计
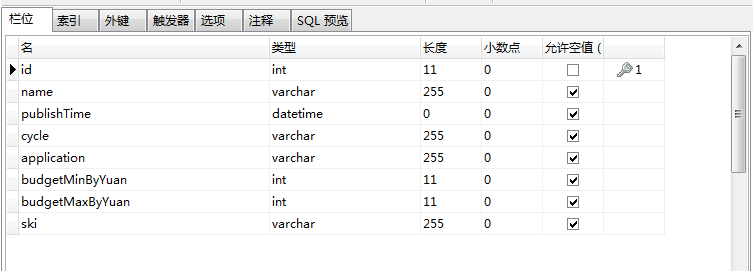
4,pipelines.py文件中写入mysql数据库
# 写入mysql数据库
import pymysql
class KaiyuanzhongguoPipeline(object):
conn = None
mycursor = None def open_spider(self, spider):
self.conn = pymysql.connect(host='172.16.25.4', user='root', password='root', db='scrapy')
self.mycursor = self.conn.cursor() def process_item(self, item, spider):
print(':正在写数据库...')
sql = 'insert into kyzg VALUES (null,"%s","%s","%s","%s","%s","%s","%s")' % (
item['name'], item['publishTime'], item['cycle'], item['application'], item['budgetMinByYuan'], item['budgetMaxByYuan'], item['ski'])
bool = self.mycursor.execute(sql)
self.conn.commit()
return item def close_spider(self, spider):
print('写入数据库完成...')
self.mycursor.close()
self.conn.close()
5,settings.py文件中设置请求头和打开下载管道
USER_AGENT = 'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/39.0.2171.71 Safari/537.36'
ITEM_PIPELINES = {
'kaiyuanzhongguo.pipelines.KaiyuanzhongguoPipeline': 300,
}
6,运行爬虫
scrapy crawl kyzg --nolog
7,查看数据库是否写入成功

done。
scrapy框架爬取开源中国项目大厅所有的发布项目。的更多相关文章
- 使用scrapy框架爬取自己的博文(2)
之前写了一篇用scrapy框架爬取自己博文的博客,后来发现对于中文的处理一直有问题- - 显示的时候 [u'python\u4e0b\u722c\u67d0\u4e2a\u7f51\u9875\u76 ...
- scrapy框架爬取笔趣阁
笔趣阁是很好爬的网站了,这里简单爬取了全部小说链接和每本的全部章节链接,还想爬取章节内容在biquge.py里在加一个爬取循环,在pipelines.py添加保存函数即可 1 创建一个scrapy项目 ...
- scrapy框架爬取笔趣阁完整版
继续上一篇,这一次的爬取了小说内容 pipelines.py import csv class ScrapytestPipeline(object): # 爬虫文件中提取数据的方法每yield一次it ...
- Python使用Scrapy框架爬取数据存入CSV文件(Python爬虫实战4)
1. Scrapy框架 Scrapy是python下实现爬虫功能的框架,能够将数据解析.数据处理.数据存储合为一体功能的爬虫框架. 2. Scrapy安装 1. 安装依赖包 yum install g ...
- 爬虫入门(四)——Scrapy框架入门:使用Scrapy框架爬取全书网小说数据
为了入门scrapy框架,昨天写了一个爬取静态小说网站的小程序 下面我们尝试爬取全书网中网游动漫类小说的书籍信息. 一.准备阶段 明确一下爬虫页面分析的思路: 对于书籍列表页:我们需要知道打开单本书籍 ...
- 基于python的scrapy框架爬取豆瓣电影及其可视化
1.Scrapy框架介绍 主要介绍,spiders,engine,scheduler,downloader,Item pipeline scrapy常见命令如下: 对应在scrapy文件中有,自己增加 ...
- scrapy框架爬取糗妹妹网站妹子图分类的所有图片
爬取所有图片,一个页面的图片建一个文件夹.难点,图片中有不少.gif图片,需要重写下载规则, 创建scrapy项目 scrapy startproject qiumeimei 创建爬虫应用 cd qi ...
- scrapy框架爬取妹子图片
首先,建立一个项目#可在github账户下载完整代码:https://github.com/connordb/scrapy-jiandan2 scrapy startproject jiandan2 ...
- 使用scrapy框架爬取自己的博文(3)
既然如此,何不再抓一抓网页的文字内容呢? 谷歌浏览器有个审查元素的功能,就是按树的结构查看html的组织形式,如图: 这样已经比较明显了,博客的正文内容主要在div 的class = cnblogs_ ...
随机推荐
- [ ceph ] CEPH 部署完整版(CentOS 7 + luminous)
1. 前言 拜读了 胖哥的(el7+jewel)完整部署 受益匪浅,目前 CEPH 已经更新到 M 版本,配置方面或多或少都有了变动,本博文就做一个 ceph luminous 版本完整的配置安装. ...
- node.js执行shell命令进行服务器重启
nodejs功能强大且多样,不只是可以实现 服务器端 与 客户端 的实时通讯,另一个功能是用来执行shell命令 1.首先,引入子进程模块var process = require('child_pr ...
- Spring Cloud 微服务技术整合
微服务架构风格是一种使用一套小服务来开发单个应用的方式途径,每个服务运行在自己的进程中,并使用轻量级机制通信,通常是HTTP API,这些服务基于业务能力构建,并能够通过自动化部署机制来独立部署,这些 ...
- C++生成和解析XML文件
1.xml 指可扩展标记语言(EXtensible Markup Language) 2.xml 是一种标记语言,类似html 3.xml 的设计宗旨是传输数据,而非显示数据 4.xml 标签没有被预 ...
- 配置多用户SMB挂载
在 system1 通过 SMB 共享目录 /devops ,并满足下列要求: 1.共享名为 devops 2.共享目录 devops 只能 group8.example.com 域中的客户端使用 3 ...
- JUC-FutureTask
得到别的线程任务的返回值 import lombok.extern.slf4j.Slf4j; import java.util.concurrent.Callable; import java.uti ...
- C# 单元测试学习笔记
1.什么是单元测试 2.单元测试的好处 (1)协助程序员尽快找到代码中bug的具体位置 (2)能够让程序员对自己的程序更有自信 (3)能够让程序员在提交项目之前就将代码变的更加的强壮 ...
- Go defer 会有性能损耗,尽量不要用?
上个月在 @polaris @轩脉刃 的全栈技术群里看到一个小伙伴问 “说 defer 在栈退出时执行,会有性能损耗,尽量不要用,这个怎么解?”. 恰好前段时间写了一篇 <深入理解 Go def ...
- 如何在Mybatis的xml文件调用java类的方法
在mybatis的映射xml文件调用java类的方法:使用的是OGNL表达式,表达式格式为:${@prefix@methodName(传递参数名称)} 1.如下代码所示:方法必须为静态方法:以下我只是 ...
- 【开发工具】- Idea.2018.02注册码激活
1.从下面地址下载一个jar包,名称是 JetbrainsCrack-3.1-release-enc.jar 下载地址: 链接: https://pan.baidu.com/s/1VZjklI3qh ...