如何丧心病狂的使用python爬虫读小说

写在前边
其实一直想入门python很久了,慕课网啊,菜鸟教程啊python的基础的知识被我翻了很多遍了,但是一直没有什么实践。刚好,这两天被别人一直安利一本小说《我可能修的是假仙》,还在连载中的,我等屌丝,打钱是不可能打钱的,只好先去网上找一下资源了,基本笔趣阁啊,什么的提供很多在线的资源给我们。好吧,就看这个就行了,可是看也看得不爽啊,,浏览器上下部分都被什么 美女荷官在线发牌,一夜不射提升半小时之类你懂的画面遮盖了,还经常误触,如果是在电脑上看,我们可以用ADBLOCK之类的广告插件屏蔽,可是手机浏览器貌似没有插件啊,那怎么办呢?我可是程序员啊,程序员怎么能向这种问题低头呢?
解决方案
我们把在线网页上的章节名和章节内容都保存下来,造一个离线的版本不就没这个问题了么?
那怎么保存呢,这就需要我们的主角出场了,铛铛铛,python scrapy爬虫框架
关于scrapy
向大家推荐 一个好玩的有趣的牛逼的网站**scrapy中文教程**
这个作者写的很有趣,摘录一下:
本scrapy文档,主要是给诸君介绍一下神马是scrapy,scrapy能干神马,提提大伙的学习热情!scrapy是一个网页爬虫框架,神马叫做爬虫,如果没听说过,那就:内事不知问度娘,外事不决问谷歌,百度或谷歌一下吧!……(这里的省略号代表scrapy很牛逼,基本神马都能爬,包括你喜欢的苍老师……这里就不翻译了)
爬虫代码
import scrapy
class firstdemo(scrapy.Spider):
# 爬虫名称
name = 'firstdemo'
# 第一页
start_urls= ['http://m.biquku.la/16/16889/578155.html']
def parse(self,response):
filename = '我可能修的是假仙.txt'
# 章节名
title = response.css('.zhong::text').extract_first()
# 章节内容
content = response.xpath("string(//article[@id='nr'])").extract()[0].replace('\n','').replace('\xa0','')
self.log(title)
with open(filename,"a+",encoding='utf-8') as f:
f.write(title)
# 添加章节目录
f.write('\n')
# 添加换行(\n)是为了让txt阅读器识别章节目录
f.write(content)
f.write('\n')
f.close
next_page = response.css('.nr_page a::attr(href)').extract()[2]
if next_page is not None:
next_page = 'http://m.biquku.la'+next_page
yield scrapy.Request(next_page,callback=self.parse)
else:
self.log('已到最终章节')
没想到吧,代码就这么多,具体的教程可以参见向大家推荐的那个网站。最后我们执行scrapy crawl firstdemo就开始爬取了。
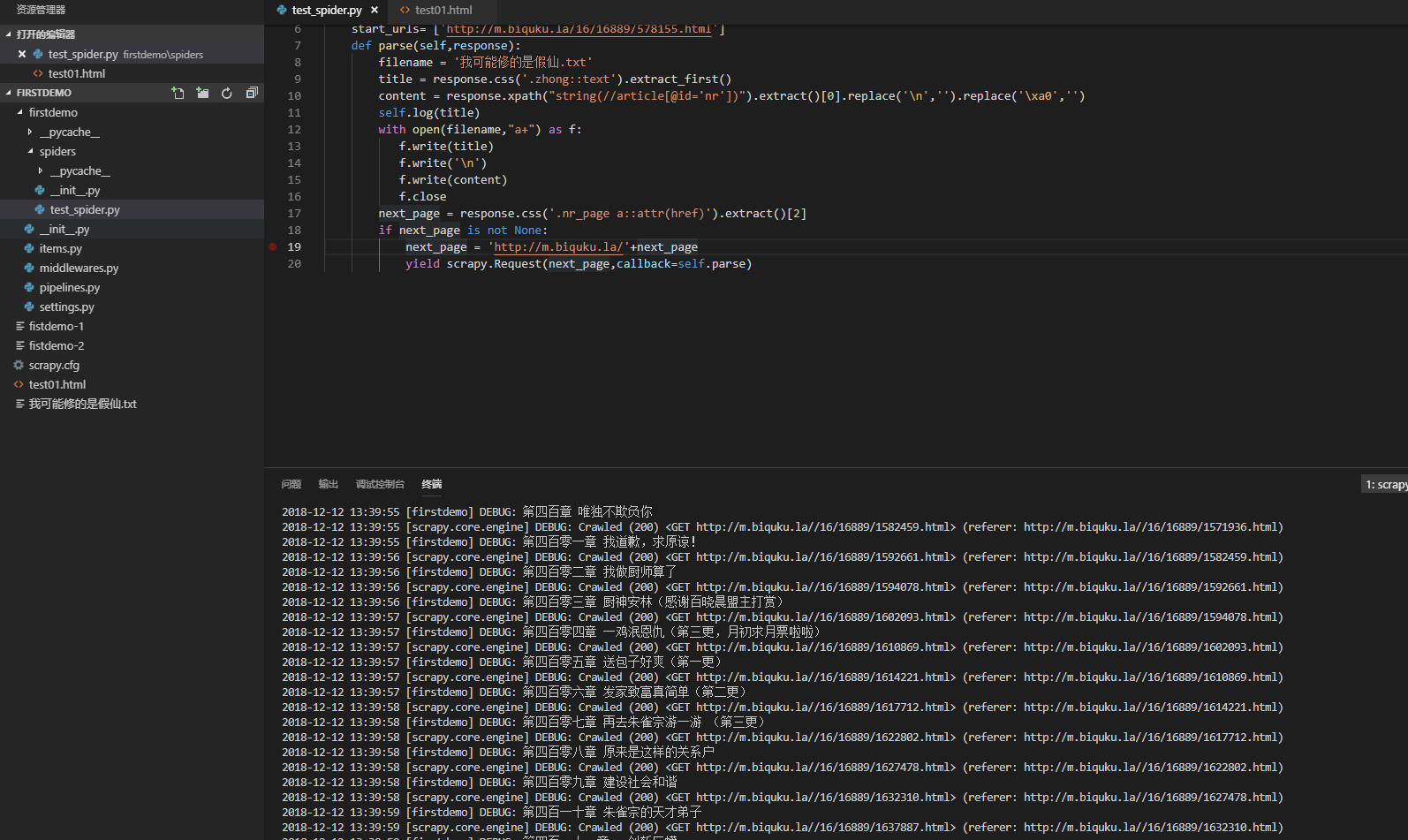
最后
最后?哪里有什么最后?都下载下来了,还不抓紧去看一下我们的战斗成果?
当然还是要提醒诸位,学习为主,不要玩物丧志。
如何丧心病狂的使用python爬虫读小说的更多相关文章
- python爬虫之小说网站--下载小说(正则表达式)
python爬虫之小说网站--下载小说(正则表达式) 思路: 1.找到要下载的小说首页,打开网页源代码进行分析(例:https://www.kanunu8.com/files/old/2011/244 ...
- Python爬虫-爬小说
用途 用来爬小说网站的小说默认是这本御天邪神,虽然我并没有看小说,但是丝毫不妨碍我用爬虫来爬小说啊. 如果下载不到txt,那不如自己把txt爬下来好了. 功能 将小说取回,去除HTML标签 记录已爬过 ...
- Python爬虫中文小说网点查找小说并且保存到txt(含中文乱码处理方法)
从某些网站看小说的时候经常出现垃圾广告,一气之下写个爬虫,把小说链接抓取下来保存到txt,用requests_html全部搞定,代码简单,容易上手. 中间遇到最大的问题就是编码问题,第一抓取下来的小说 ...
- 使用Python爬虫整理小说网资源-自学
第一次接触python,原本C语言的习惯使得我还不是很适应python的语法风格.希望读者能够给出建议. 相关的入门指导来自以下的网址:https://blog.csdn.net/c406495762 ...
- python爬虫之小说爬取
废话不多说,直接进入正题. 今天我要爬取的网站是起点中文网,内容是一部小说. 首先是引入库 from urllib.request import urlopen from bs4 import Bea ...
- python爬虫爬小说网站涉及到(js加密,CSS加密)
我是对于xxxx小说网进行爬取只讲思路不展示代码请见谅 一.涉及到的反爬 js加密 css加密 请求头中的User-Agent以及 cookie 二.思路 1.对于js加密 对于有js加密信息,我们一 ...
- python|爬虫东宫小说
2k小说网爬取最近大火的<东宫>小说,借鉴之前看过的一段代码,修改之后,进行简单爬取. from urllib import requestfrom bs4 import Beautifu ...
- python爬虫下载小说
1. from urllib.request import urlopen from urllib import request from bs4 import BeautifulSoup from ...
- 批量下载小说网站上的小说(python爬虫)
随便说点什么 因为在学python,所有自然而然的就掉进了爬虫这个坑里,好吧,主要是因为我觉得爬虫比较酷,才入坑的. 想想看,你可以批量自动的采集互联网上海量的资料数据,是多么令人激动啊! 所以我就被 ...
随机推荐
- C++——数组形参退化为指针
数组做形参退化为指针 如果数组作为函数参数,则数组形参会退化为指针,以下代码在编译器看来是等价的 ]); ]); void fun3(int a[]); void fun4(int *a); #inc ...
- js中对new Date() 中转换字符串方法toLocaleString的使用
提供特定于区域设置的日期和时间格式. dateTimeFormatObj = new Intl.DateTimeFormat([locales][, options]) dateTimeFormatO ...
- 用js刷剑指offer(顺时针打印数组)
题目描述 输入一个矩阵,按照从外向里以顺时针的顺序依次打印出每一个数字,例如,如果输入如下4 X 4矩阵: 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 则依次打印出数 ...
- The "web.xml" is called web application deployment descriptor
3.3 Configure the Application Deployment Descriptor - "web.xml" A web user invokes a serv ...
- Linux文件系统之install(复制文件和设置文件属性)
install命令 install命令的作用是安装或升级软件或备份数据,它的使用权限是所有用户.install命令和cp命令类似,都可以将文件/目录拷贝到指定的地点.但是,install允许你控制目标 ...
- 基于Flask和百度AI实现与机器人对话
实现对话机器人主要有个步骤 : 一.前端收集语音传入后端 二.后端基于百度AI接口进行语音识别,转换成文字 三.对文字进行自定义验证或通过图灵端口进行处理,生成回复内容 四.将文字通过百度AI接口合成 ...
- python2和python3编程差异杂谈(-)
python2 默认编码ascii 在使用中文时要显示的声明 #-*-encoding:utf-8-*- python3 默认编码utf-8,良好的支持了中文输入 python2: print函数 ...
- BZOJ 3218 A + B Problem (可持久化线段树+最小割)
做法见dalao博客 geng4512的博客, 思路就是用线段树上的结点来进行区间连边.因为有一个只能往前面连的限制,所以还要可持久化.(duliu) 一直以来我都是写dinicdinicdinic做 ...
- C# 判断一个string型的时间格式是否正确
在项目开发过程中,由于各种坑爹的需求,我们可能需要用户自己手动输入时间,不过这种功能一般都出现在自己家的后台里面,咳咳,言归正传.既然如此,那么这个时候我们就需要对用户手动输入的时间格式进行验证,方法 ...
- 爬取淘宝商品数据并保存在excel中
1.re实现 import requests from requests.exceptions import RequestException import re,json import xlwt,x ...