Python实例---爬取下载喜马拉雅音频文件
PyCharm下python爬虫准备
打开pycharm
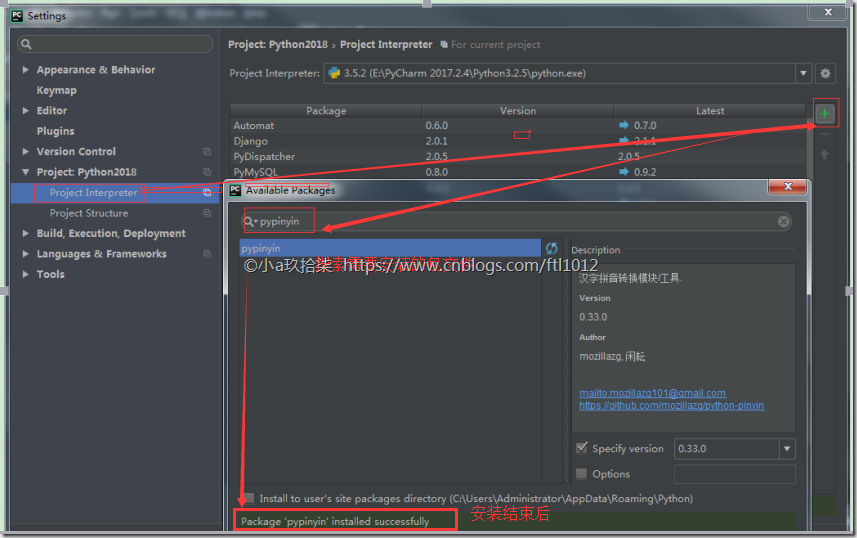
点击设置
点击项目解释器,再点击右边+号
搜索相关库并添加,例如:requests
喜马拉雅全网递归下载
打开谷歌/火狐浏览器,按F12打开开发者工具—>选择【网络】
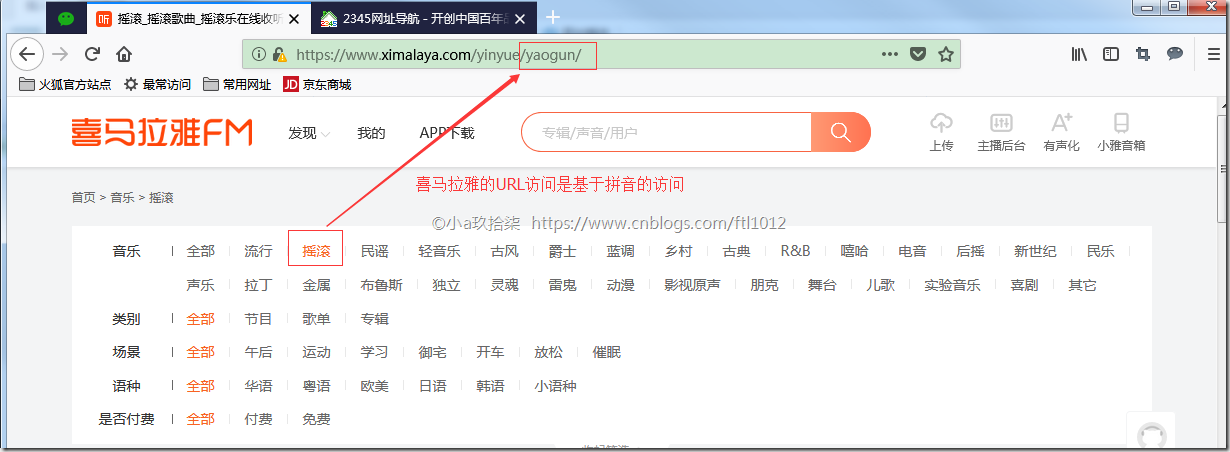
编辑器浏览器输入: https://www.ximalaya.com/yinyue/ 点击【摇滚】
发现弹出新的URL:https://www.ximalaya.com/yinyue/yaogun/ [汉字转换拼音后的URL访问]
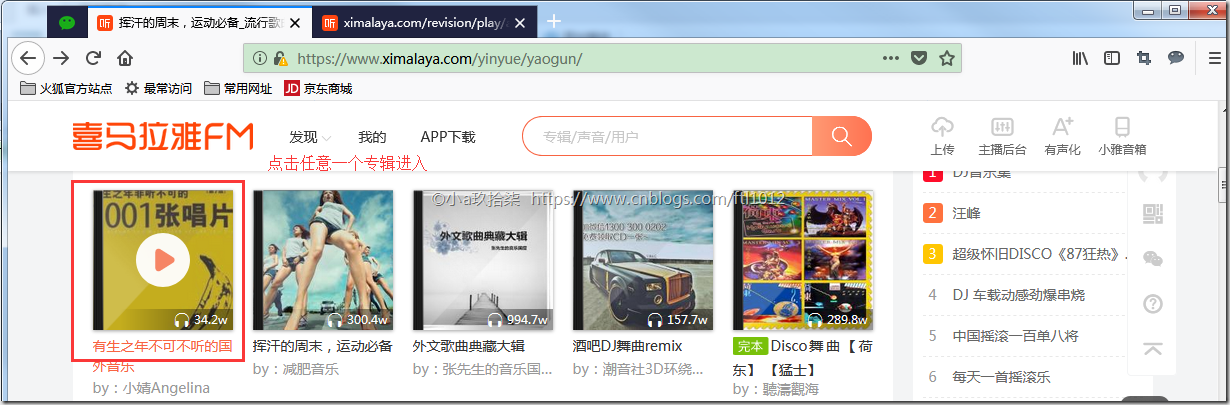
点击进入任意一个专辑[未播放]
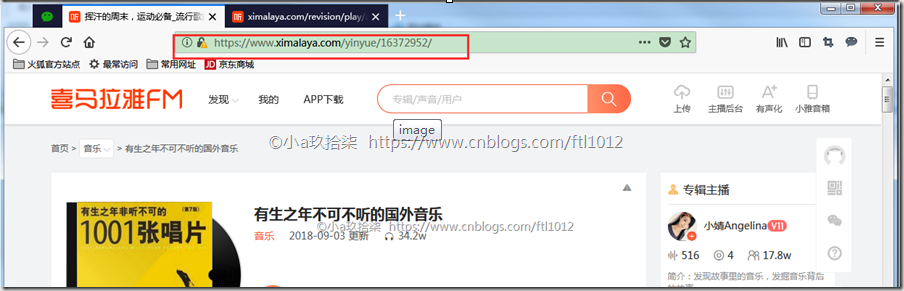
点击播放音乐[播放中]
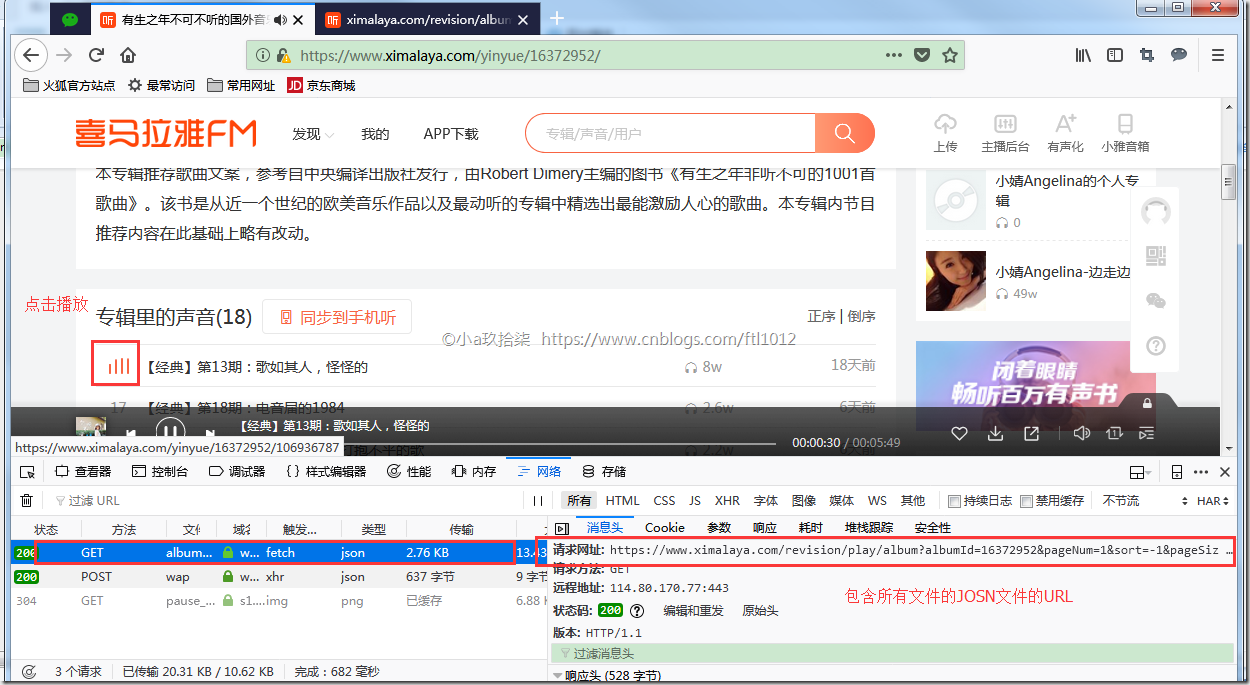
[是一个json格式的URL]访问搜索界面的源代码,查找albumId,通过这些albumid获取音频文件的url
https://www.ximalaya.com/revision/play/album?albumId=16372952&pageNum=1&sort=-1&pageSize=30

最后使用函数urllib.request.urlretrieve()下载音乐即可

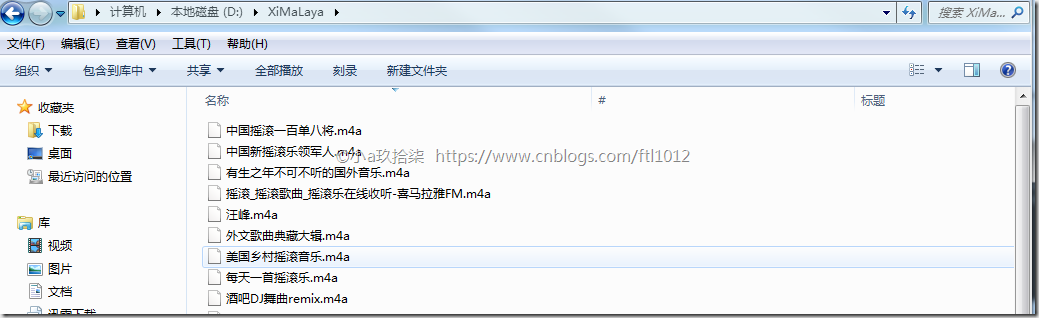
附源码:
import re
import os
import json
import requests
import urllib
from urllib import request
from pypinyin import lazy_pinyin class XimaLaya(object):
# 模拟浏览器操作
def __init__(self):
self.header = {
"User-Agent": 'Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:60.0) Gecko/20100101 Firefox/60.0'
} # 第一步: 根据输入的汉字转换为拼音
def han_pinyin(self, hanzi):
pin = lazy_pinyin(hanzi) # 汉转拼音
pin = "".join(pin) # 去除空格
return pin # 返回拼音 # 第二步: 根据REST格式去访问喜马拉雅,获取页面的HTML
def getHtml(self, pinyin):
url = 'https://www.ximalaya.com/yinyue/' + pinyin
print("访问的网站是: " + url)
html = requests.get(url, headers=self.header)
# apparent_encoding通过调用chardet.detect()来识别文本编码,有些消耗计算资源
html.encoding = html.apparent_encoding
# html.encoding = 'utf8' --> 直接改为UTF8也行
with open('D:\XiMaLaya\html\\' + str(pinyin + '.html'), 'a', encoding='utf-8') as f:
f.write(html.text)
return html # 第三步:根据页面的内容获取对应歌单的albumId的值
def getAlbumId(self, html):
albumIdAll = re.findall(r'"albumId":(.*)', (html).text) # 利用正则进行匹配,获取专辑ID
print("专辑信息", albumIdAll)
with open('D:\XiMaLaya\\albumIdAll\\' + str('albumIdAll.txt'), 'a', encoding='utf-8') as f:
for x in albumIdAll:
f.write(str(x))
myList = []
url3 = []
for i in (albumIdAll[:1]):
# 获取对应专辑ID的首页
url2 = 'https://www.ximalaya.com/revision/play/album?albumId=' + i
print(url2)
# 进入对应专辑ID的首页信息
html2 = requests.get(url2.split(',')[0], headers=self.header)
# 含有下载URL的集合
# src "http://audio.xmcdn.com/group12/M03/2C/AA/wKgDW1WJ7GqxuItqAB8e1LXvuds895.m4a"
url3 = (re.findall(r'"src":"(.*?)"', (html2).text))
# 记录信息用的
myList.append('获取对应专辑ID的首页\r\n' + url2 + '\n---------------------------------------')
myList.append('含有下载URL的集合\r\n' + html2.text + '\n---------------------------------------')
myList.append('下载专辑的URL集合\r\n' + str(url3) + '\n---------------------------------------')
with open('D:\XiMaLaya\\albumIdAll\\' + str('hhh.txt'), 'a', encoding='utf-8') as f:
f.write(json.dumps(myList))
print('done')
return url3 # 下载专辑的URL集合 # 第四步: 获取专辑名
def getTitle(self, html):
t = re.findall(r'"title":"(.*?)"', (html).text) # 获取titile(歌名)的值
with open('D:\XiMaLaya\\albumIdAll\\' + str('albumId_Name.txt'), 'a', encoding='utf-8') as f:
f.write(str(t))
return t # 第五步: 下载歌曲
def downLoad(self, url, title):
n = 0
for i in url:
try:
urllib.request.urlretrieve(i, 'D:\XiMaLaya\\'+str(title[n]+'.m4a'))
print(str(title[n]), '...【下载成功】')
n = n + 1
except:
print(str(title[n]) + "...【下载失败】") if __name__ == '__main__': fm = XimaLaya()
# 输入需要下载的歌曲类型
str1 = fm.han_pinyin("摇滚")
# 获取对应歌曲类型的首页信息
html = fm.getHtml(str1)
# 获取歌曲类型的首页里面的专辑名称
title = fm.getTitle(html)
# 获取歌曲类型的首页里面的专辑ID
url3 = fm.getAlbumId(html)
# 下载对应曲目
fm.downLoad(url3, title)
喜马拉雅单一专辑的下载
打开谷歌/火狐浏览器,按F12打开开发者工具—>选择【网络】
编辑器浏览器输入: https://www.ximalaya.com/yinyue/12521114/
点击计入音乐[未播放前]
点击进入音乐[播放中]
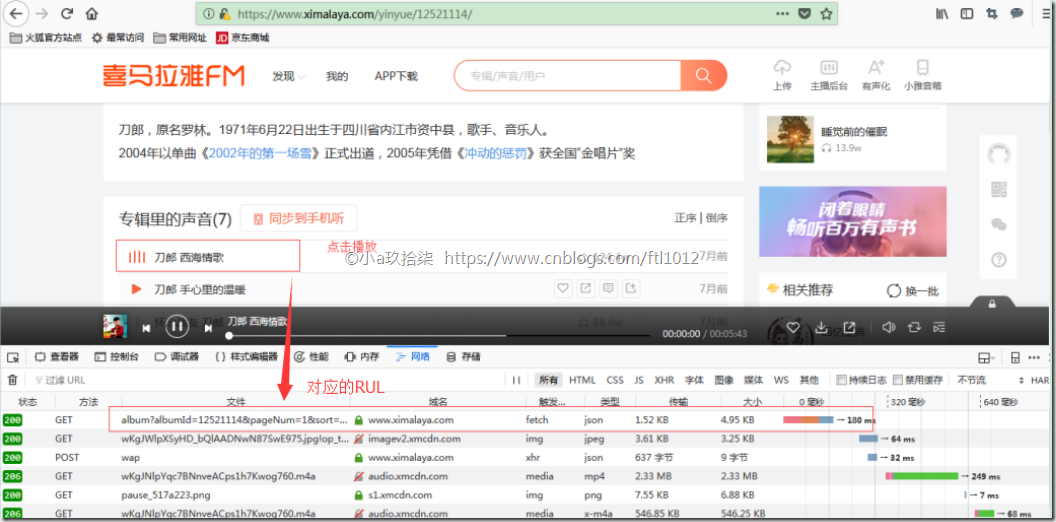
[是一个json格式的URL]访问搜索界面的源代码,查找albumId,通过这些albumid获取音频文件的url
https://www.ximalaya.com/revision/play/album?albumId=12521114&pageNum=1&sort=-1&pageSize=30
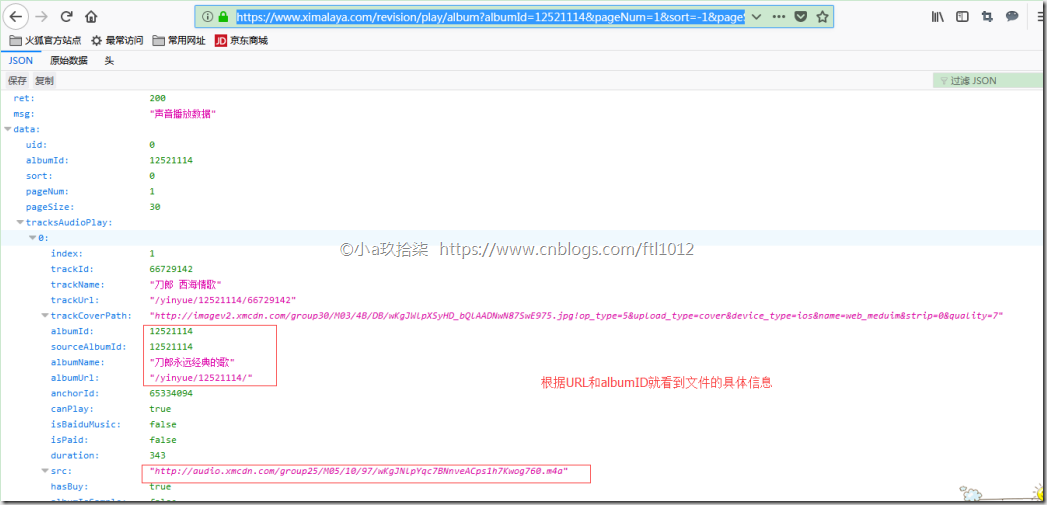
最后使用函数urllib.request.urlretrieve()下载音乐即可

附源码:
import re
import json
import requests
import urllib
from urllib import request class XimaLaya(object):
# 模拟浏览器操作
def __init__(self):
self.header = {
"User-Agent": 'Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:60.0) Gecko/20100101 Firefox/60.0'
} # 第一步:根据REST格式去访问喜马拉雅,获取页面的HTML
def getHtml(self, pinyin):
url = 'https://www.ximalaya.com/yinyue/' + pinyin
print("访问的网站是: " + url)
html = requests.get(url, headers=self.header)
# apparent_encoding通过调用chardet.detect()来识别文本编码,有些消耗计算资源
html.encoding = html.apparent_encoding
# html.encoding = 'utf8' --> 直接改为UTF8也行
print(html)
return html # 第二步:根据页面的内容获取对应歌单的albumId的值
def getAlbumId(self, html):
albumIdAll = re.findall(r'"albumId":(.*)', (html).text) # 利用正则进行匹配,获取专辑ID
print("专辑信息", albumIdAll)
with open('D:\XiMaLaya\\albumIdAll\\' + str('albumIdAll.txt'), 'a', encoding='utf-8') as f:
for x in albumIdAll:
f.write(str(x))
myList = []
url3 = []
for i in (albumIdAll[:1]):
# 获取对应专辑ID的首页
url2 = 'https://www.ximalaya.com/revision/play/album?albumId=' + i
print(url2)
# 进入对应专辑ID的首页信息
html2 = requests.get(url2.split(',')[0], headers=self.header)
# 含有下载URL的集合
# src "http://audio.xmcdn.com/group12/M03/2C/AA/wKgDW1WJ7GqxuItqAB8e1LXvuds895.m4a"
url3 = (re.findall(r'"src":"(.*?)"', (html2).text))
# 记录信息用的
myList.append('获取对应专辑ID的首页\r\n' + url2 + '\n---------------------------------------')
myList.append('含有下载URL的集合\r\n' + html2.text + '\n---------------------------------------')
myList.append('下载专辑的URL集合\r\n' + str(url3) + '\n---------------------------------------')
with open('D:\XiMaLaya\\albumIdAll\\' + str('hhh.txt'), 'a', encoding='utf-8') as f:
f.write(json.dumps(myList))
print('done')
return url3 # 下载专辑的URL集合 # 第三步: 获取专辑名
def getTitle(self, html):
t = re.findall(r'"title":"(.*?)"', (html).text) # 获取titile(歌名)的值
with open('D:\XiMaLaya\\albumIdAll\\' + str('albumId_Name.txt'), 'a', encoding='utf-8') as f:
f.write(str(t))
return t # 第四步: 下载歌曲
def downLoad(self, url, title):
n = 0
for i in url:
try:
urllib.request.urlretrieve(i, 'D:\XiMaLaya\\'+str(title[n]+'.m4a'))
print(str(title[n]), '...【下载成功】')
n = n + 1
except:
print(str(title[n]) + "...【下载失败】") if __name__ == '__main__': fm = XimaLaya()
# 输入需要下载的歌曲URL
str1 = "yinyue/12521114/"
# 获取对应歌曲类型的首页信息
html = fm.getHtml(str1)
# 获取歌曲类型的首页里面的专辑名称
title = fm.getTitle(html)
# 获取歌曲类型的首页里面的专辑ID
url3 = fm.getAlbumId(html)
# 下载对应曲目
fm.downLoad(url3, title)
Python实例---爬取下载喜马拉雅音频文件的更多相关文章
- Python疫情爬取输出到txt文件
在网上搬了一个代码,现在不适用了,改了改 import requestsimport jsondef Down_data(): url = 'https://view.inews.qq.com/g2/ ...
- Python爬虫|爬取喜马拉雅音频
"GOOD Python爬虫|爬取喜马拉雅音频 喜马拉雅是知名的专业的音频分享平台,用户规模突破4.8亿,汇集了有声小说,有声读物,儿童睡前故事,相声小品等数亿条音频,成为国内发展最快.规模 ...
- Python Scrapy 爬取煎蛋网妹子图实例(一)
前面介绍了爬虫框架的一个实例,那个比较简单,这里在介绍一个实例 爬取 煎蛋网 妹子图,遗憾的是 上周煎蛋网还有妹子图了,但是这周妹子图变成了 随手拍, 不过没关系,我们爬图的目的是为了加强实战应用,管 ...
- python连续爬取多个网页的图片分别保存到不同的文件夹
python连续爬取多个网页的图片分别保存到不同的文件夹 作者:vpoet mail:vpoet_sir@163.com #coding:utf-8 import urllib import ur ...
- Python爬虫 - 爬取百度html代码前200行
Python爬虫 - 爬取百度html代码前200行 - 改进版, 增加了对字符串的.strip()处理 源代码如下: # 改进版, 增加了 .strip()方法的使用 # coding=utf-8 ...
- Python+Selenium爬取动态加载页面(1)
注: 最近有一小任务,需要收集水质和水雨信息,找了两个网站:国家地表水水质自动监测实时数据发布系统和全国水雨情网.由于这两个网站的数据都是动态加载出来的,所以我用了Selenium来完成我的数据获取. ...
- 使用Python爬虫爬取网络美女图片
代码地址如下:http://www.demodashi.com/demo/13500.html 准备工作 安装python3.6 略 安装requests库(用于请求静态页面) pip install ...
- Python爬虫爬取全书网小说,程序源码+程序详细分析
Python爬虫爬取全书网小说教程 第一步:打开谷歌浏览器,搜索全书网,然后再点击你想下载的小说,进入图一页面后点击F12选择Network,如果没有内容按F5刷新一下 点击Network之后出现如下 ...
- Scrapy教程——搭建环境、创建项目、爬取内容、保存文件
1.创建项目 在开始爬取之前,您必须创建一个新的Scrapy项目.进入您打算存储代码的目录中,运行新建命令. 例如,我需要在D:\00Coding\Python\scrapy目录下存放该项目,打开命令 ...
随机推荐
- JDBC中链接数据库前为什么要用Class.forName(驱动类)加载驱动类?
使用JDBC链接数据库时,为什么要先使用Class.forName(String name)来加载类? 答: 实际上就是为了加载类时,调用静态初始化块中的注册函数. 可以看一下MySql的Driber ...
- HBase:分布式列式NoSQL数据库
传统的ACID数据库,可扩展性上受到了巨大的挑战.而HBase这类系统,兼具可扩展性的同时,也提出了类SQL的接口. HBase架构组成 HBase采用Master/Slave架构搭建集群,它隶属于H ...
- 【IT笔试面试题整理】判断一个树是否是另一个的子树
[试题描述]定义一个函数,输入判断一个树是否是另一个对的子树 You have two very large binary trees: T1, with millions of nodes, and ...
- docker空间管理之清理磁盘占用
1.docker部署后修改数据存放目录,默认存放到/var/lib/docker下面,修改到一个大的空间目录下面.参考我的另外一篇博客:https://www.cnblogs.com/cuishuai ...
- 自制 Chrome Custom.css 设置网页字体为微软雅黑扩展
自己做的將網頁自動替換為微軟雅黑的擴展.很好用. 將Customcss.rcx拖到擴展裏就可. 下載:Customcss.zip
- Navicat---使用SSH远程连接到MySql,报错80070007: SSH Tunnel: Server does not support diffie-hellman-group1-sha1 for keyexchange
尝试使用Navicat远程连接到我在阿里云服务器上的MySql,通过SSH. 但是报错: 80070007: SSH Tunnel: Server does not support diffie-he ...
- jQuery选择器遇上一些特殊字符
学习jQuery过程中,发现一些特殊字符,如“.”,“#”,"(","]"等.它在选择器应用时,按照普通处理就会出错.解决办法,就是使用转义字符来处理,这有点象 ...
- EWS Managed API 2.0 设置获取邮件自动回复功能
摘要 最近要在邮件提醒功能中添加,自动回复的功能.在移动端获取用户在outlook上是否开启了自动回复功能,如果用户在outlook上开启了自动回复功能, 获取用户自动回复的内容,如果没有开启,用户可 ...
- Java基础——collection接口
一.Collection接口的定义 public interfaceCollection<E>extends iterable<E> 从接口的定义中可以发现,此接口使用了泛型 ...
- video 在移动端播放禁止全屏
<video src="" preload controls x5-playsinline="" playsinline="" web ...