Python脚本批量造数据、跑定时任务协助测试
批量造数据
- 连接Mysql的信息
1 import pymysql
2 # 数据库连接信息
3 # 多个库要有多个conn
4 conn = pymysql.connect(
5 host="主机",
6 user="用户名",
7 password="密码",
8 database="库名"
9 )
10 conn1 = pymysql.connect(
11 host="主机",
12 user="用户名",
13 password="密码",
14 database="库名"
15 )
16
17 # 创建游标对象
18 cursor = conn.cursor()
19 cursor1 = conn1.cursor()
20
21 # 执行对应的SQL
22 cursor.execute
23 # 获取执行结果
24 Result=cursor.fetchall()
场景一:基于已有的csv文件,分批次读取csv文件中的字段值作为变量填充到执行的SQL语句
- 分批读取csv文件中的值
1 csv_file_path = 'csv文件目录'
2 with open(csv_file_path, 'r',encoding='utf-8') as file:
3 reader = csv.reader(file)
4 next(reader) # Skip the header row
5
6 batch_size = 100 # 每批处理的数量
7 total_items = 3100 # 总共需要处理的数量
8
9 for i in range(0, total_items, batch_size):
10 # 在每次循环中处理 batch_size 个项目
11 # 可以在循环体内部使用 i 作为起始索引
12
13 for j in range(i, min(i + batch_size, total_items)):
14 row = next(reader)
15 # 打印这一行的数据
16 print(row)
场景二:随机生成特殊字段的值,作为变量填充到Insert语句中
- 随机生成统代
1 import random
2 import string
3 def generate_credit_code():
4 # 生成第1位登记管理部门代码
5 管理部门代码 = ['1', '2', '3', '4', '5', '6', '7', '8', '9', 'A', 'B', 'C', 'D']
6 register_department = random.choice(管理部门代码)
7 # print('管理部门代码为',register_department)
8
9 # 生成2-9位组织机构代码
10 organizations_code = []
11 for _ in range(8):
12 org_code = ''
13 for _ in range(8):
14 org_code += random.choice(string.ascii_uppercase + string.digits)
15 organizations_code.append(org_code)
16 organizations_code=random.choice(organizations_code)
17 # print('组织机构代码为',organizations_code)
18
19
20 # 生成10-17位统一社会信用代码
21 unification_credit_code = ''
22 for _ in range(8):
23 unification_credit_code += random.choice(string.ascii_uppercase + string.digits)
24 # print('统一社会信用代码为',unification_credit_code)
25
26 # 组合统一社会信用代码
27 credit_code = f"{register_department}{''.join(organizations_code)}{unification_credit_code}"
28 return credit_code
- 随机生成注册号
1 mport random
2
3 #这个注册号是由15个随机数字组成的,使用random.choice方法从0-9中随机选择数字。这个方法会被调用15次,每次都会生成一个随机数字,然后通过字符串的join方法将这15个数字拼接在一起。
4 def generate_reg_code():
5 # 15位注册号,以0开头
6 reg_code = ''.join(random.choice('0123456789') for i in range(15))
7 return reg_code
结合python+pytest+fixture 实现定时任务接口调用
目录结构
(有些乱。。。
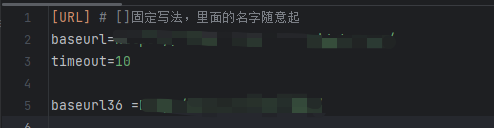
-- config.ini 存放的是系统固定的url之类的
-- conftest.py 一般用于放登录接口,用户返回token,利用fixture被其他接口使用
1 import pytest
2 import requests
3 import pymysql
4 from config import readconfig
5 readcon = readconfig.Read()
6
7
8 @pytest.fixture(scope="session")
9 # 这个方法是pytest封装公共方法的一个文件,文件名必须是(conftest.py)
10 # 作用: 其他地方在使用这个方法时就不用from XX import cc 然后也不用实例化了
11
12
13 def test_login():
14 msg = {
15 "username": '用户名',
16 "password": '加密后的密码'
17 }
18
19 url =readcon.get_URL("baseurl")
20 cc = requests.post(url+"api/uxxxxxxr/login", params=msg)
21 getjson = cc.json()
22
23 # 获取token
24 tok = getjson['data']['token']
25 userid = getjson['data']['userId']
26 return tok, userid
定时任务
1 import pytest
2 import requests
3 from config import readconfig
4
5 read = readconfig.Read()
6
7 class TestCase1:
8 global url, tim # 全局变量,便于其他地方调用
9 url = read.get_URL("baseurl") # https://abchina-zx-dev.hsjdata.com/
10 tim = read.get_URL("timeout")
11 '''小姐姐的定时任务'''
12 def test_case1(self, test_login):
13 head = {'Content-Type': 'application/json', 'Authorization': test_login[0]} # test_login[0]为token
14
15 NewtestGsEidList = []
16 NewtestGsCreditCodeList = []
17 NewtestGsEntNameList = []
18 # 取非工商表最新插入的100家企业 同步到es中
19 SelectNewtestGs = "select eid,entname,credit_code from enterprisebaseinfocollect order by id desc limit 100"
20 cursor.execute(SelectNewtestGs)
21 SelectNewtestGsResult = cursor.fetchall()
22
23 for tuple in SelectNewtestGsResult:
24 NewtestGsCreditCodeList.append(tuple[2])
25
26
27 NewtestGsCreditCodeListResult = ', '.join('"' + i + '"' for i in NewtestGsCreditCodeList)
28 print('企业统代为', NewtestGsCreditCodeListResult)
29
30 print(r.json())
import pytest
import requests
import json
import random
from config import readconfig
read = readconfig.Read()
import pymysql
# data_dat =20230907
conn = pymysql.connect(
host="10.1.1.106",
user="cpdev",
password="9abZ7mak2",
database="abchina_home"
)
cursor = conn.cursor()
class TestCase1:
global url, tim # 全局变量,便于其他地方调用
url = read.get_URL("baseurl") # https://abchina-zx-dev.hsjdata.com/
tim = read.get_URL("timeout")
'''小姐姐的定时任务'''
def test_case1(self, test_login):
head = {'Content-Type': 'application/json', 'Authorization': test_login[0]} # test_login[0]为token
NewtestGsEidList = []
NewtestGsCreditCodeList = []
NewtestGsEntNameList = []
# 取非工商表最新插入的100家企业 同步到es中
SelectNewtestGs = "select eid,entname,credit_code from enterprisebaseinfocollect order by id desc limit 100"
cursor.execute(SelectNewtestGs)
SelectNewtestGsResult = cursor.fetchall()
for tuple in SelectNewtestGsResult:
NewtestGsEidList.append(tuple[0])
NewtestGsEntNameList.append(tuple[1])
NewtestGsCreditCodeList.append(tuple[2])
NewtestGsEidListResult = ', '.join(i for i in NewtestGsEidList)
print('最新插入的工商企业的eid',NewtestGsEidListResult)
print('-----------------------------------------------------------------')
NewtestGsEntNameListResult = ', '.join('"' + i + '"' for i in NewtestGsEntNameList)
print('最新插入的工商企业的名称为', NewtestGsEntNameListResult)
print('-----------------------------------------------------------------')
NewtestGsCreditCodeListResult = ', '.join('"' + i + '"' for i in NewtestGsCreditCodeList)
print('最新插入的工商企业的统代为', NewtestGsCreditCodeListResult)
r = requests.get(url + 'api/ent-search/task/initGs?eid='+NewtestGsEidListResult, headers=head)
# assert r.json()['message'] == '成功'
print(r.json())
Python脚本批量造数据、跑定时任务协助测试的更多相关文章
- 使用python脚本批量造数据
本篇将采用 Python 脚本的方式进行批量给mysql造数据. 为了使 Python 可以连上数据库(MySQL),并且可以与数据库交互(增删改查等操作),则需要安装 MySQL 客户端操作库. ...
- python脚本批量生成数据
在平时的工作中,经常会遇到造数据,特别是性能测试的时候更是需要大量的数据.如果一条条的插入数据库或者一条条的创建数据,效率未免有点低.如何快速的造大量的测试数据呢?在不熟悉存储过程的情况下,今天给大家 ...
- Delphi中使用python脚本读取Excel数据
Delphi中使用python脚本读取Excel数据2007-10-18 17:28:22标签:Delphi Excel python原创作品,允许转载,转载时请务必以超链接形式标明文章 原始出处 . ...
- Jmeter(二十三)Jmeter-Question之“批量造数据”
日常工作中,无论是在做功能测试.接口测试还是性能测试,经常会有这么一个场景出现,“那个谁谁谁,帮我加几条订单”,“那个某某某,给购物车增添几个产品”,“在数据库加几百条数据”...等等,通常少数量,或 ...
- SpringBoot(18)---通过Lua脚本批量插入数据到Redis布隆过滤器
通过Lua脚本批量插入数据到布隆过滤器 有关布隆过滤器的原理之前写过一篇博客: 算法(3)---布隆过滤器原理 在实际开发过程中经常会做的一步操作,就是判断当前的key是否存在. 那这篇博客主要分为三 ...
- 怎样通过excel录入来批量造数据
背景: 自动化测试除了验证系统功能外,还能够为测试人员根据测试要求造数据实现测试需要!但是一般的自动化测试,都是在编写脚本的时候,写死在程序里的.所以本文是为了在满足系统操作流程的基础上,根据测试的要 ...
- 除了binlog2sql工具外,使用python脚本闪回数据(数据库误操作)
利用binlog日志恢复数据库误操作数据 在人工手动进行一些数据库写操作的时候(比方说数据修改),尤其是一些不可控的批量更新或删除,通常都建议备份后操作.不过不怕万一,就怕一万,有备无患总是好的.在线 ...
- 使用Python脚本批量裁切栅格
对栅格的裁切,我们通常使用裁切(数据管理-栅格-栅格处理)或按掩膜提取(空间分析-提取分析)来裁切,裁切的矢量要素通常是一个要素图层或Shape文件.如果要进行批量处理,可以使用ToolBox中的批量 ...
- 使用python脚本批量设置nginx站点的rewrite规则
一般情况下,配置rewrite重写规则使用shell脚本即可: 把url拼凑成1,2文件中中的格式,运行 chongxie.sh 即可生成我们需要的rewrite规则 [root@web01:/opt ...
- python脚本批量生成50000条插入数据的sql语句
f = open("xx.txt",'w') for i in range(1,50001): str_i = str(i) realname = "lxs"+ ...
随机推荐
- 简单了解一下国产CPU
这几天在B站.油管上刷了一些国产芯片真实上手视频,顺便自己也梳理一下芯片的一些基本概念,以及在美国科技制裁和围堵的情况下,国产CPU的发展情况.文末有我整理的一张思维导图,hope u find it ...
- Application of Permutation and Combination
Reference https://www.shuxuele.com/combinatorics/combinations-permutations.html Online Tool https:// ...
- CKS 考试题整理 (11)-沙箱运行容器gVisor
Context 该 cluster使用 containerd作为CRI运行时.containerd的默认运行时处理程序是runc. containerd已准备好支持额外的运行时处理程序runsc (g ...
- 【python基础】函数-模块
函数的优点之一是,使用它们可将代码块与主程序分离.通过给函数指定函数名称,可让主程序容易理解的多.我们还可以更加细化,将函数存储在被称为模块的独立文件中,再将模块导入到主程序中.import关键字作用 ...
- [渗透测试]—7.1 漏洞利用开发和Shellcode编写
在本章节中,我们将学习漏洞利用开发和Shellcode编写的基本概念和技巧.我们会尽量详细.通俗易懂地讲解,并提供尽可能多的实例. 7.1 漏洞利用开发 漏洞利用开发是渗透测试中的高级技能.当你发现一 ...
- golang 实现四层负载均衡
大家好,我是蓝胖子,做开发的同学应该经常听到过负载均衡的概念,今天我们就来实现一个乞丐版的四层负载均衡,并用它对mysql进行负载均衡测试,通过本篇你可以了解到零拷贝的应用,四层负载均衡的本质以及实践 ...
- Qt源码阅读(五)-deleteLater
Qt deleteLater作用及源码分析 个人经验总结,如有错误或遗漏,欢迎各位大佬指正 在本篇文章中,我们将深入分析源码,探讨deleteLater的原理. deleteLater是Qt框架提供的 ...
- CocosCreator + Vscode + Ts 代码注释生成文档,利用typedoc
需求: 脚本的代码注释,生成为文档 基本搭建环境: (cocoscreator 2.4.x + vscode + ts) .(nodejs + npm) 步骤: 1.安装typedoc: npm in ...
- Oracle分区表设置详解
Oracle分区表详解 Oracle建议单表超过2G就需要进行分表,一万数据大概3MB,单表最多分区为1024*1024-1个分区,我感觉够我们使用了哈 废话不多说,上示例,Oracle分表具体sql ...
- Linux 问题:网络相关
防火墙 同网段双网卡 双网关 看服务日志