Hologres如何支持超高基数UV计算(基于roaringbitmap实现)
RoaringBitmap是一种压缩位图索引,RoaringBitmap自身的数据压缩和去重特性十分适合对于大数据下uv计算。其主要原理如下:
- 对于32bit数, RoaringBitmap会构造2^16个桶,对应32位数的高16位;32位数的低16位则映射到对应桶的一个bit上。单个桶的容量由桶中的已有的最大数值决定
- bitmap把32位数用1位表示,可以大大地压缩数据大小。
- bitmap位运算为去重提供了手段。
主体思想(T+1):把上一天的所有数据根据最大的查询维度聚合出的uid结果放入RoaringBitmap中,把RoaringBitmap和查询维度存放在聚合结果表(每天百万条)。之后查询时,利用Hologres强大的列存计算直接按照查询维度去查询聚合结果表,对其中关键的RoaringBitmap字段做or运算进行去重后并统计基数,即可得出对应用户数UV,count条数即可计算得出PV,达到亚秒级查询。
只需进行一次最细粒度的预聚合计算,也只生成一份最细粒度的预聚合结果表。得益于Hologres的实时计算能力,该方案下预计算所需的次数和空间都达到较低的开销。
Hologres计算UV、PV方案详情
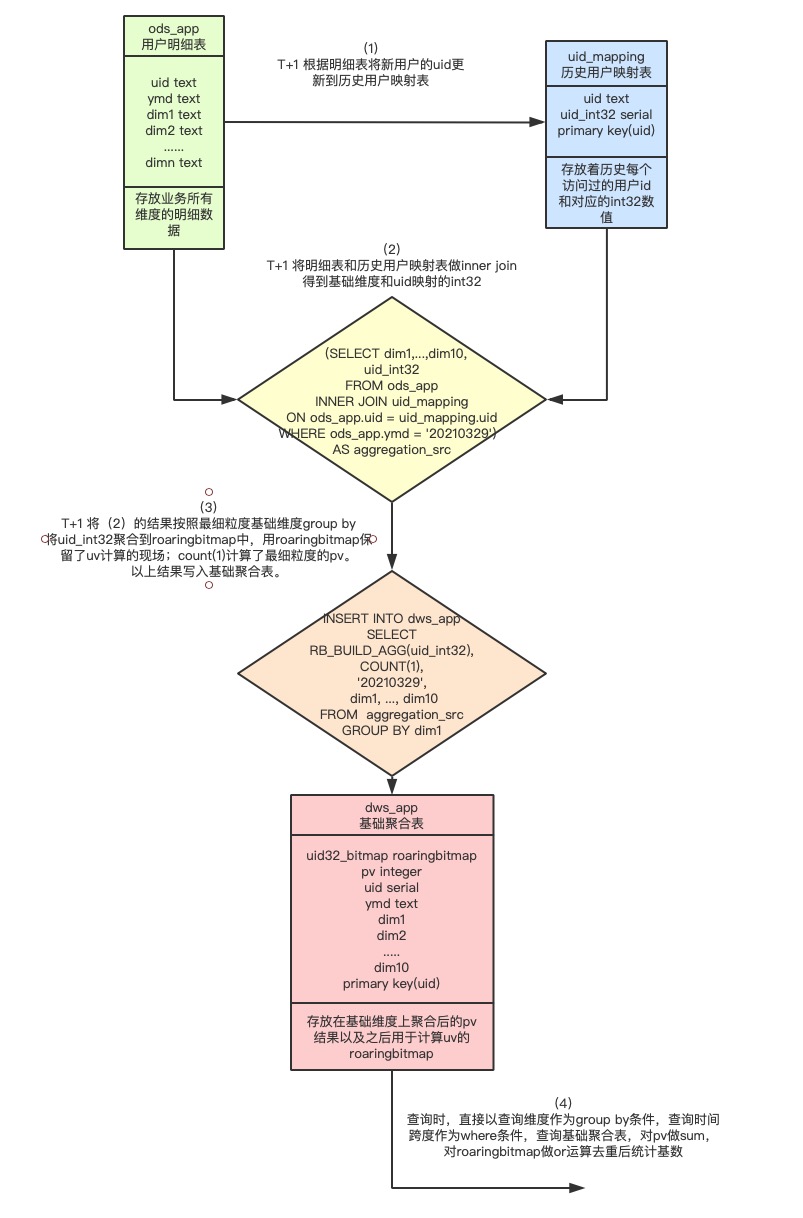
图1 Hologres基于RoaringBitmap计算pv uv流程
1.创建相关基础表
1)使用RoaringBitmap前需要创建RoaringBitmap extention,语法如下,同时该功能需要Hologres 0.10版本。
CREATE EXTENSION IF NOT EXISTS roaringbitmap;
2)创建表ods_app为明细源表,存放用户每天大量的明细数据 (按天分区),其DDL如下:
BEGIN;
CREATE TABLE IF NOT EXISTS public.ods_app (
uid text,
country text,
prov text,
city text,
channel text,
operator text,
brand text,
ip text,
click_time text,
year text,
month text,
day text,
ymd text NOT NULL
);
CALL set_table_property('public.ods_app', 'bitmap_columns', 'country,prov,city,channel,operator,brand,ip,click_time, year, month, day, ymd');
--distribution_key根据需求设置,根据该表的实时查询需求,从什么维度做分片能够取得较好效果即可
CALL set_table_property('public.ods_app', 'distribution_key', 'uid');
--用于做where过滤条件,包含完整年月日时间字段推荐设为clustering_key和event_time_column
CALL set_table_property('public.ods_app', 'clustering_key', 'ymd');
CALL set_table_property('public.ods_app', 'event_time_column', 'ymd');
CALL set_table_property('public.ods_app', 'orientation', 'column');
COMMIT;
3)创建表uid_mapping为uid映射表,uid映射表用于映射uid到32位int类型。
RoaringBitmap类型要求用户ID必须是32位int类型且越稠密越好(用户ID最好连续),而常见的业务系统或者埋点中的用户ID很多是字符串类型,因此使用uid_mapping类型构建一张映射表。映射表利用Hologres的SERIAL类型(自增的32位int)来实现用户映射的自动管理和稳定映射。
注: 该表在本例每天批量写入场景,可为行存表也可为列存表,没有太大区别。如需要做实时数据(例如和Flink联用),需要是行存表,以提高Flink维表实时JOIN的QPS。
BEGIN;
CREATE TABLE public.uid_mapping (
uid text NOT NULL,
uid_int32 serial,
PRIMARY KEY (uid)
);
--将uid设为clustering_key和distribution_key便于快速查找其对应的int32值
CALL set_table_property('public.uid_mapping', 'clustering_key', 'uid');
CALL set_table_property('public.uid_mapping', 'distribution_key', 'uid');
CALL set_table_property('public.uid_mapping', 'orientation', 'row');
COMMIT;
3)创建表dws_app基础聚合表,用于存放在基础维度上聚合后的结果
基础维度为之后进行查询计算pv和uv的最细维度,这里以country, prov, city为例构建聚合表
begin;
create table dws_app(
country text,
prov text,
city text,
ymd text NOT NULL, --日期字段
uid32_bitmap roaringbitmap, -- UV计算
pv integer, -- PV计算
primary key(country, prov, city, ymd)--查询维度和时间作为主键,防止重复插入数据
);
CALL set_table_property('public.dws_app', 'orientation', 'column');
--clustering_key和event_time_column设为日期字段,便于过滤
CALL set_table_property('public.dws_app', 'clustering_key', 'ymd');
CALL set_table_property('public.dws_app', 'event_time_column', 'ymd');
--distribution_key设为group by字段
CALL set_table_property('public.dws_app', 'distribution_key', 'country,prov,city');
end;
2.更新dws表及id_mapping表
每天从上一天的uid中找出新客户(uid映射表uid_mapping中没有的uid)插入到uid映射表中
WITH
-- 其中ymd = '20210329'表示上一天的数据
user_ids AS ( SELECT uid FROM ods_app WHERE ymd = '20210329' GROUP BY uid )
,new_ids AS ( SELECT user_ids.uid FROM user_ids LEFT JOIN uid_mapping ON (user_ids.uid = uid_mapping.uid) WHERE uid_mapping.uid IS NULL )
INSERT INTO uid_mapping SELECT new_ids.uid
FROM new_ids
;
更新完uid映射表后,将数据做聚合运算后插入聚合结果表,主要步骤如下:
- 首先通过源表inner join uid映射表,得到上一天的聚合条件和对应的uid_int32;
- 然后按照聚合条件做聚合运算后插入RoaringBitmap聚合结果表,作为上一天的聚合结果;
- 每天只需进行一次聚合,存放一份数据,数据条数最坏等于UV的量。以案例说明,明细表每天几亿的增量,在聚合结果表每天只需存放百万级数据。
WITH
aggregation_src AS( SELECT country, prov, city, uid_int32 FROM ods_app INNER JOIN uid_mapping ON ods_app.uid = uid_mapping.uid WHERE ods_app.ymd = '20210329' )
INSERT INTO dws_app SELECT country
,prov
,city
,'20210329'
,RB_BUILD_AGG(uid_int32)
,COUNT(1)
FROM aggregation_src
GROUP BY country
,prov
,city
;
3.UV、PV查询
查询时,从汇总表dws_app 中按照查询维度做聚合计算,查询bitmap基数,得出Group by条件下的用户数
--运行下面RB_AGG运算查询,可先关闭三阶段聚合开关性能更佳(默认关闭)
set hg_experimental_enable_force_three_stage_agg=off --可以查询基础维度任意组合,任意时间段的uv pv
SELECT country
,prov
,city
,RB_CARDINALITY(RB_OR_AGG(uid32_bitmap)) AS uv
,sum(1) AS pv
FROM dws_app
WHERE ymd = '20210329'
GROUP BY country
,prov
,city; --查一个月
SELECT country
,prov
,RB_CARDINALITY(RB_OR_AGG(uid32_bitmap)) AS uv
,sum(1) AS pv
FROM dws_app
WHERE ymd >= '20210301' and ymd <= '20210331'
GROUP BY country
,prov;
该查询等价于
SELECT country
,prov
,city
,COUNT(DISTINCT uid) AS uv
,COUNT(1) AS pv
FROM ods_app
WHERE ymd = '20210329'
GROUP BY country
,prov
,city; SELECT country
,prov
,COUNT(DISTINCT uid) AS uv
,COUNT(1) AS pv
FROM ods_app
WHERE ymd >= '20210301' and ymd <= '20210331'
GROUP BY country
,prov;
4.可视化展示
计算出UV、PV和,大多数情况需要用BI工具以更直观的方式可视化展示,由于需要使用RB_CARDINALITY 和 RB_OR_AGG 进行聚合计算,需要使用BI的自定义聚合函数的能力,常见的具备该能力的BI包括Apache Superset和Tableau,下面将会讲述这两个BI工具的最佳实践。
4.1 使用 Apache Superset
Apache Superset 对接 Hologres 的方式,请参考产品手册。在Superset中可以直接使用dws_app表作为Dataset使用
并且在数据集中,创建一个单独Metrics,名为UV,表达式如下:
RB_CARDINALITY(RB_OR_AGG(uid32_bitmap))
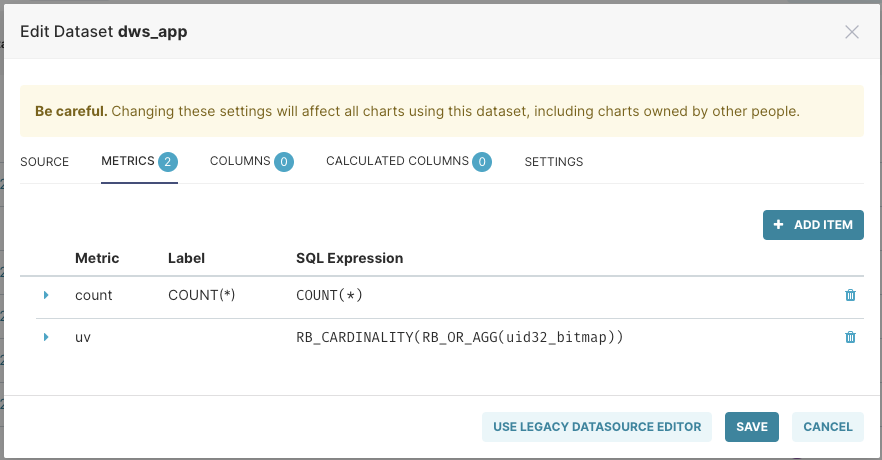
然后您就可以开始探索数据了
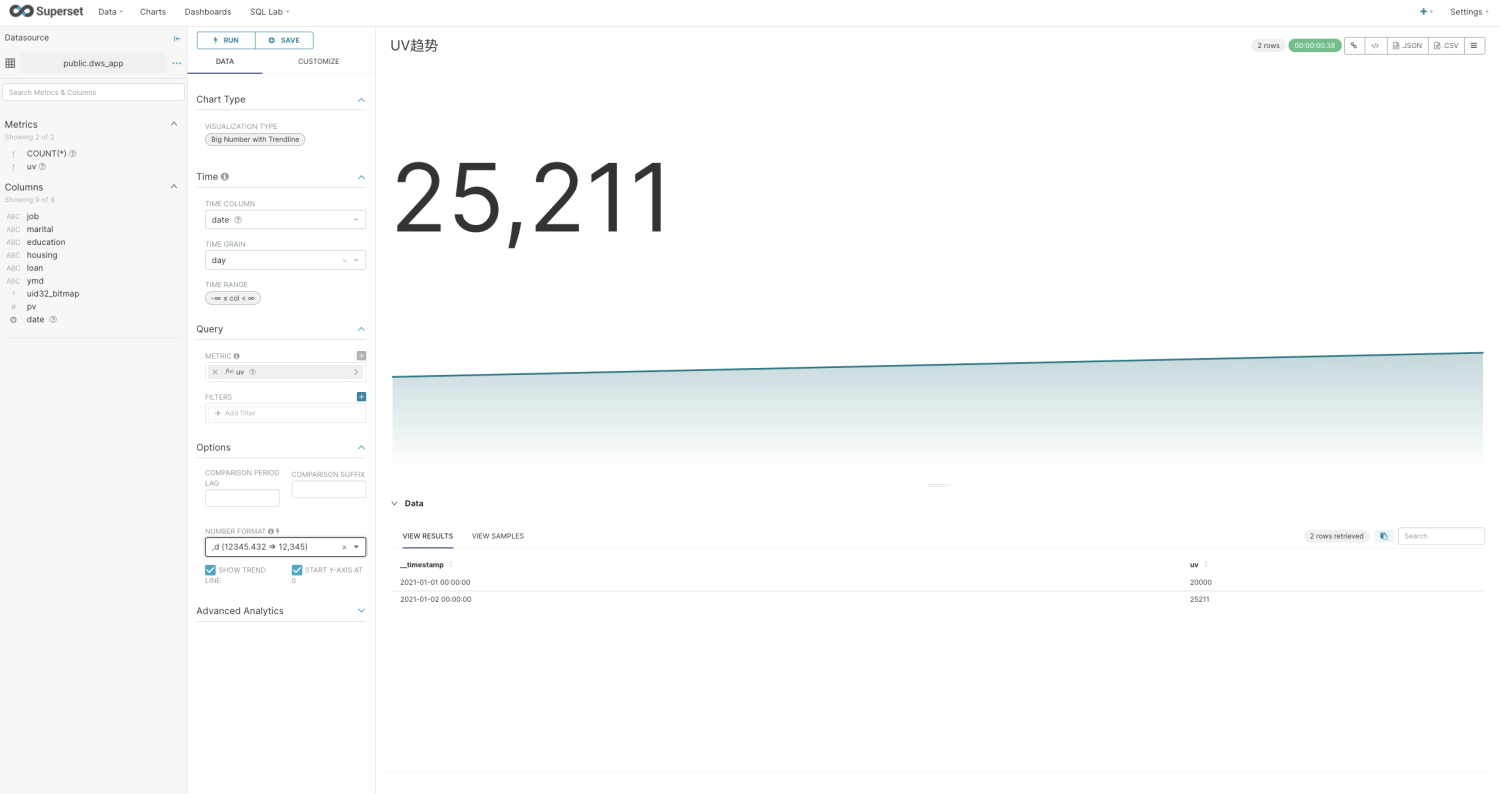
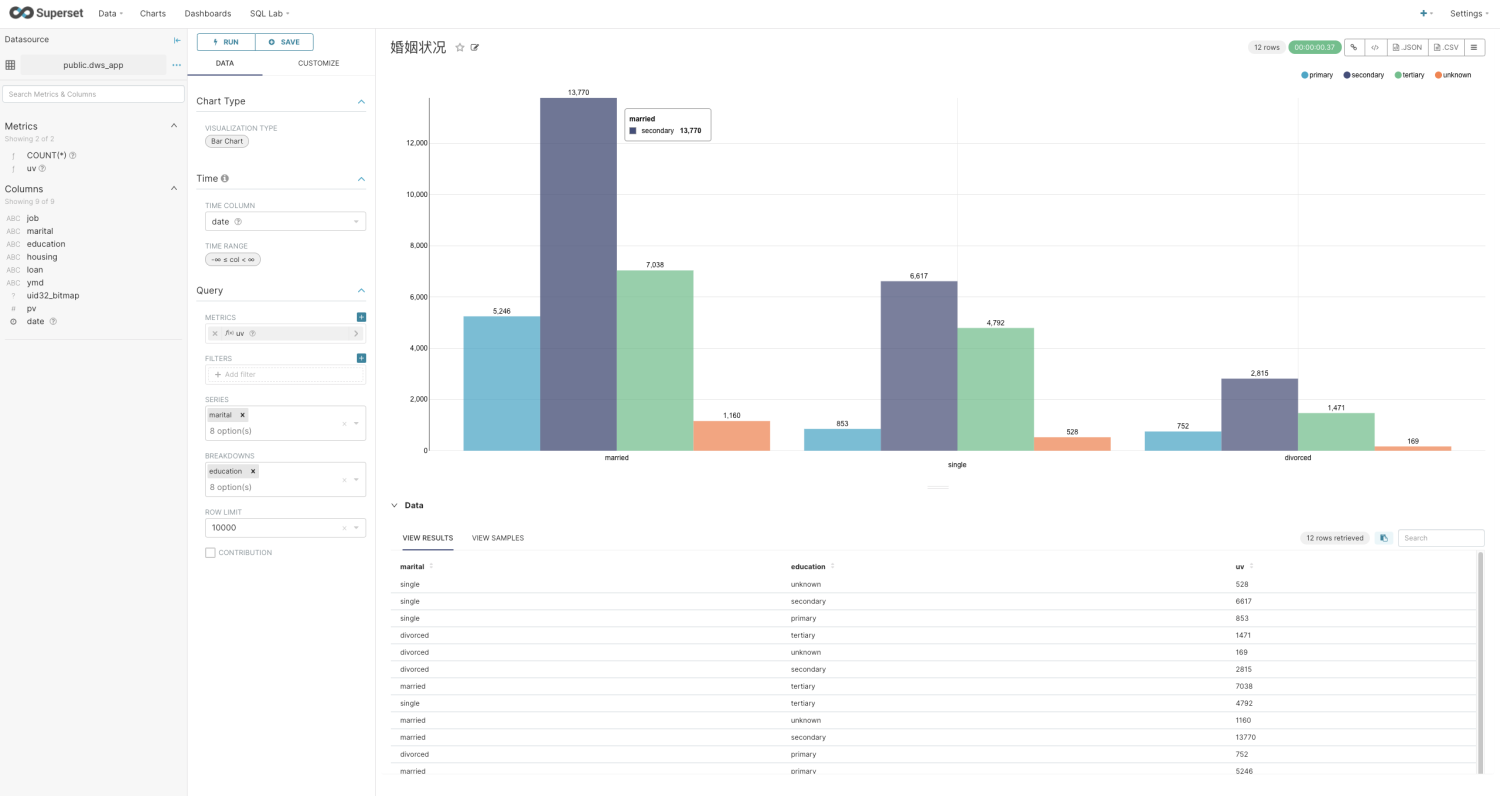
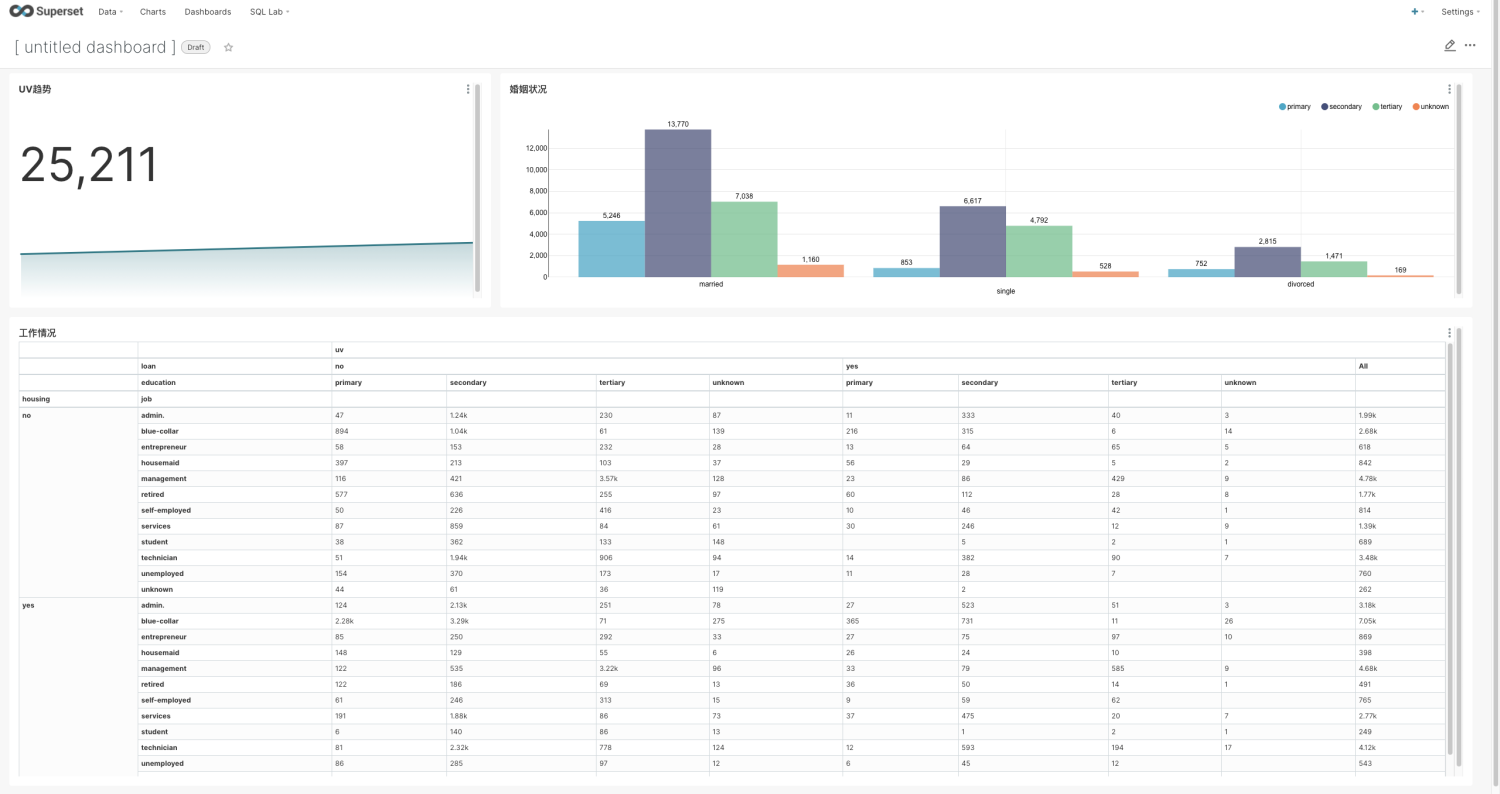
当然也可以创建Dashborad:
4.2 使用 Tableau
Tableau 对接 Hologres 的方式,请参考产品手册。可以使用Tableau的直通函数直接实现自定义函数的能力,详细介绍请参照Tableau的手册。在Tableau对接Hologres后,可以创建一个计算字段,表达式如下
RAWSQLAGG_INT("RB_CARDINALITY(RB_OR_AGG(%1))", [Uid32 Bitmap])
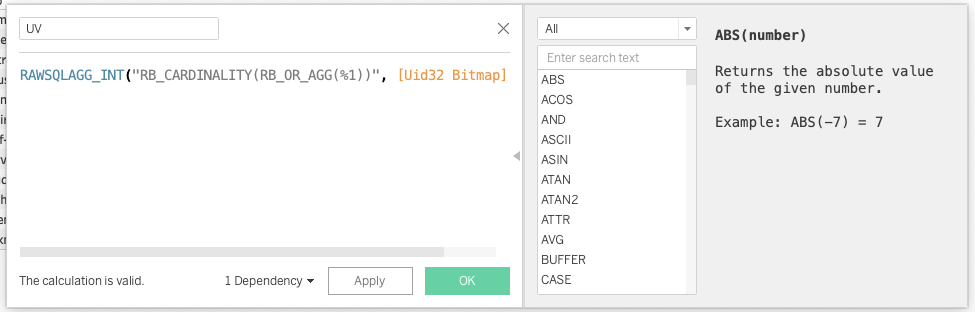
然后您就可以开始探索数据了
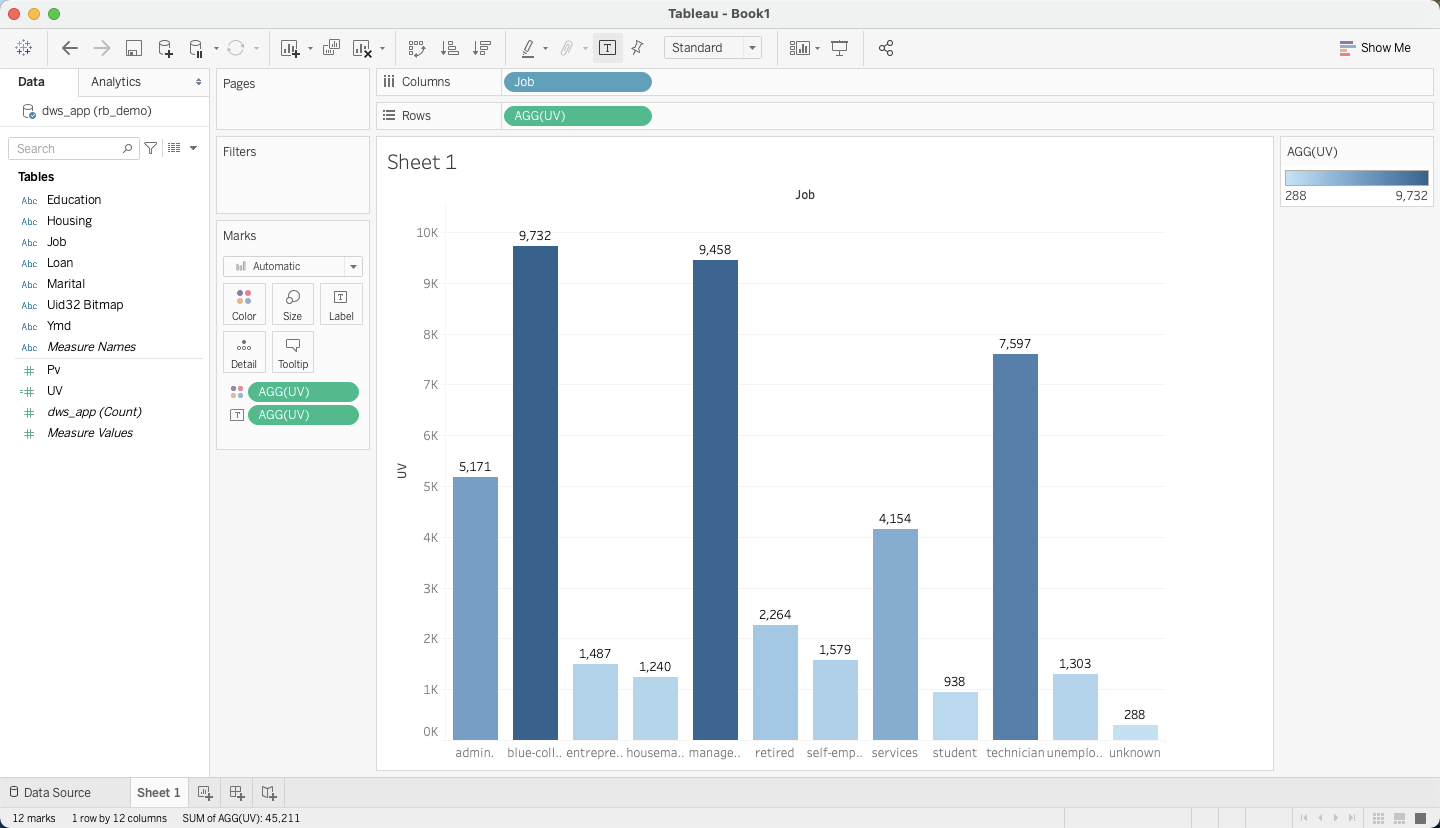
当然也可以创建Dashborad

本文为阿里云原创内容,未经允许不得转载。
Hologres如何支持超高基数UV计算(基于roaringbitmap实现)的更多相关文章
- 【实时数仓】Day03-DWM 层业务:各层的设计和常用信息、访客UV计算、跳出明细计算(CEP技术合并数据识别)、订单宽表(双流合并,事实表与维度数据合并)、支付宽表
一.DWS层与DWM层的设计 1.设计思路 分流到了DWD层,并将数据分别出传入指定的topic 规划需要实时计算的指标,形成主题宽表,作为DWS层 2.需求梳理 DWM 层主要服务 DWS,因为部分 ...
- Https系列之三:让服务器同时支持http、https,基于spring boot
Https系列会在下面几篇文章中分别作介绍: 一:https的简单介绍及SSL证书的生成二:https的SSL证书在服务器端的部署,基于tomcat,spring boot三:让服务器同时支持http ...
- 一个支持高网络吞吐量、基于机器性能评分的TCP负载均衡器gobalan
一个支持高网络吞吐量.基于机器性能评分的TCP负载均衡器gobalan 作者最近用golang实现了一个TCP负载均衡器,灵感来自grpc.几个主要的特性就是: 支持高网络吞吐量 实现了基于机器性能评 ...
- 并发编程概述 委托(delegate) 事件(event) .net core 2.0 event bus 一个简单的基于内存事件总线实现 .net core 基于NPOI 的excel导出类,支持自定义导出哪些字段 基于Ace Admin 的菜单栏实现 第五节:SignalR大杂烩(与MVC融合、全局的几个配置、跨域的应用、C/S程序充当Client和Server)
并发编程概述 前言 说实话,在我软件开发的头两年几乎不考虑并发编程,请求与响应把业务逻辑尽快完成一个星期的任务能两天完成绝不拖三天(剩下时间各种浪),根本不会考虑性能问题(能接受范围内).但随着工 ...
- 阿里云数据库产品HybridDB简介——OLAP数据库,支持行列混合存储,基于数据库Greenplum的开源版本,并且吸收PostgreSQL精髓
为什么会有HybridDB的诞生?它经历了怎样的研发历程?它的应用场景和情况是怎样的?带着这些问题,InfoQ对阿里云的数据库专家兼Postgres中国社区/中国用户会主席萧少聪先生进行了采访,以下文 ...
- Python代码相似度计算(基于AST和SW算法)
代码相似度计算将基于AST和Smith-Waterman算法 AST (抽象语法树) AST即Abstract Syntax Trees,是源代码的抽象语法结构的树状表示,树上的每个节点都表示源代码中 ...
- Centos7.2下Nginx配置SSL支持https访问(站点是基于.Net Core2.0开发的WebApi)
准备工作 1.基于nginx部署好的站点(本文站点是基于.Net Core2.0开发的WebApi,有兴趣的同学可以跳http://www.cnblogs.com/GreedyL/p/7422796. ...
- uv计算
lightmap shadowmap heightmap 它们有一个自己的camera 对应cameraMatrix float3 TransfromToTextureCoord(float4 Pos ...
- 支持并发的httpclient(基于tcp连接池以及netty)
闲来无事,将曾经自己写的一个库放出来吧. . 有的时候会有这样子的需求: (1)serverA通过HTTP协议来訪问serverB (2)serverA可能会并发的像B发送非常多HTTP请求 类似于上 ...
- 关于opencv3.2的parallel_for_函数不支持bind function的处理(基于ch8代码)
1.换opencv4 2.修改程序 改程序针对slambook2/ch8/direct_method.cpp #include <opencv2/opencv.hpp> #include ...
随机推荐
- RecyclerView问题汇总
目录介绍 25.0.0.0 请说一下RecyclerView?adapter的作用是什么,几个方法是做什么用的?如何理解adapter订阅者模式? 25.0.0.1 ViewHolder的作用是什么? ...
- PLC与上位机传递数据
1.我这里使用的是HslCommunication 假如传递的是word类型,PLC以16进制封装数组,它有预留,我扩充 PLC博图上是 word[5] 上位机接收 ushort[] Data1=ne ...
- 记录--为啥面试官总喜欢问computed是咋实现的?
这里给大家分享我在网上总结出来的一些知识,希望对大家有所帮助 从computed的特性出发 computed最耀眼的几个特性是啥? 1. 依赖追踪 import { reactive, compute ...
- RL 基础 | Policy Gradient 的推导
去听了 hzxu 老师的 DRL 课,感觉终于听懂了,记录一下- 目录 0 我们想做什么 1 三个数学 trick 2 对单个 transition 的 policy gradient 3 对整个 t ...
- [前端原生技术]jsonp
[版权声明]未经博主同意,谢绝转载!(请尊重原创,博主保留追究权)https://www.cnblogs.com/cnb-yuchen/p/18031965出自[进步*于辰的博客] 在学习了Jsoup ...
- date_histogram,es按照时间分组统计
日期直方图聚合(date_histogram) 与histogram相似,es中内部将日期表示为一个long值,所以有时候可以用histogram来达到相同的目的,但往往没有date_histogra ...
- 一个可以让你有更多时间摸鱼的WPF控件(一)
前言 我们平时在开发软件的过程中,有这样一类比较常见的功能,它没什么技术含量,开发起来也没有什么成就感,但是你又不得不花大量的时间来处理它,它就是对数据的增删改查.当我们每增加一个需求就需要对应若干个 ...
- Windows下获取设备管理器列表信息-setupAPI
背景及问题: 在与硬件打交道时,经常需要知道当前设备连接的硬件信息,以便连接正确的硬件,比如串口通讯查询连接的硬件及端口,一般手工的方式就是去设备管理器查看相应的信息,应用程序如何读取这一部分信息呢, ...
- Scala 不可变列表List
1 package chapter07 2 3 object Test04_List { 4 def main(args: Array[String]): Unit = { 5 // 1. 创建一个L ...
- CTFshow pwn49 wp
PWN49 用ida打开我们发现是静态编译的,所以先要通过libc库来打是不可能的了,程序里面有一个栈溢出点,找一下有没有system函数,发现并没有 那么我们找一下有没有mprotect函数如果有这 ...