PyQuery爬取历史天气信息
1.准备工作:
网址:https://lishi.tianqi.com/xian/index.html
爬虫类库:PyQuery,requests
2.网页分析:

红线部分可更改为需要爬取的城市名,如:beijing

红框选中部分即为我们所需要爬取的每个月份的信息. 目测应该是ui li,使用Chrome F12 查看下源代码
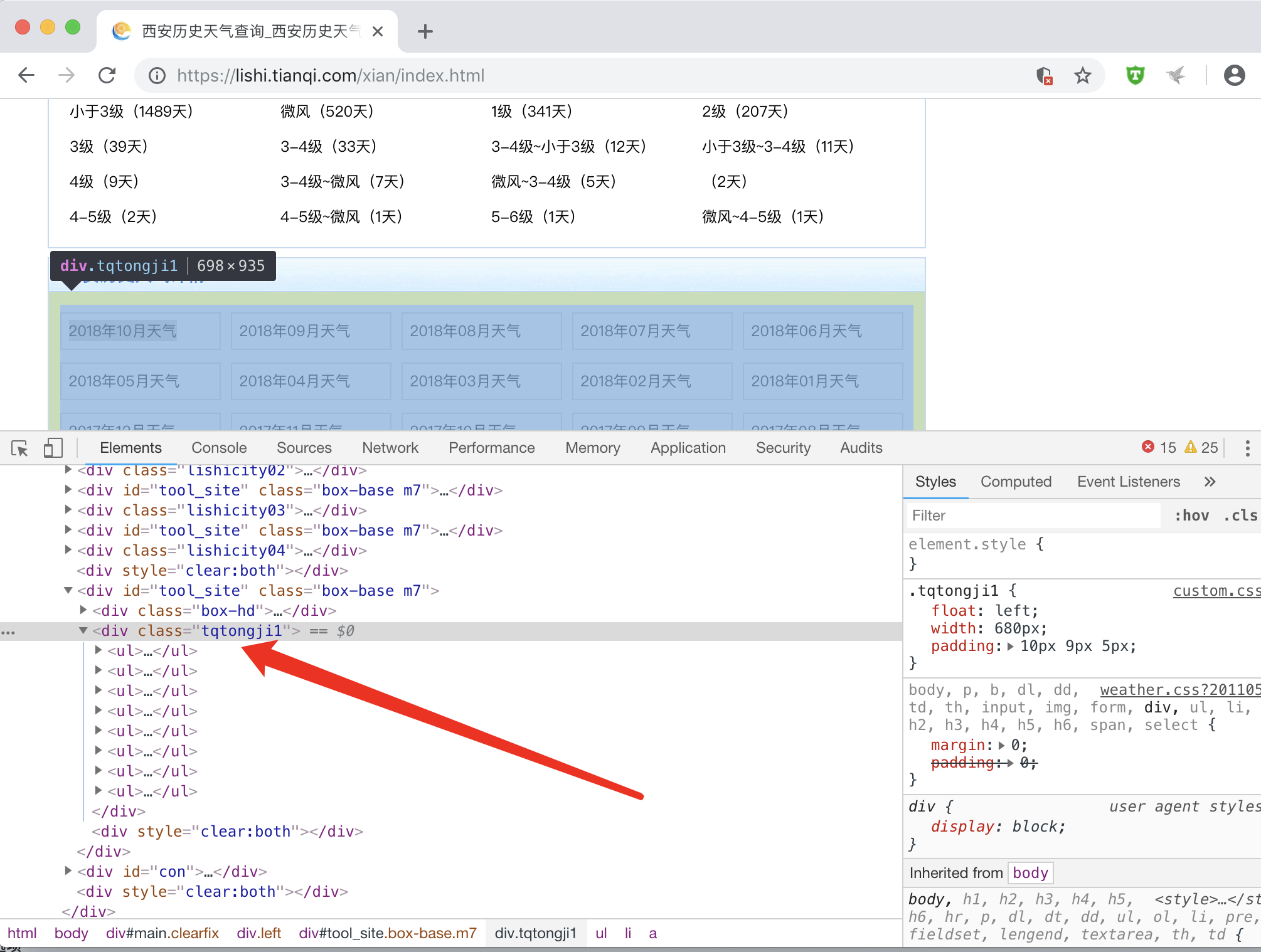
PyQuery的css 选择器可以起床了..
莫慌莫慌。在瞅瞅具体月份点击进入后的页面效果
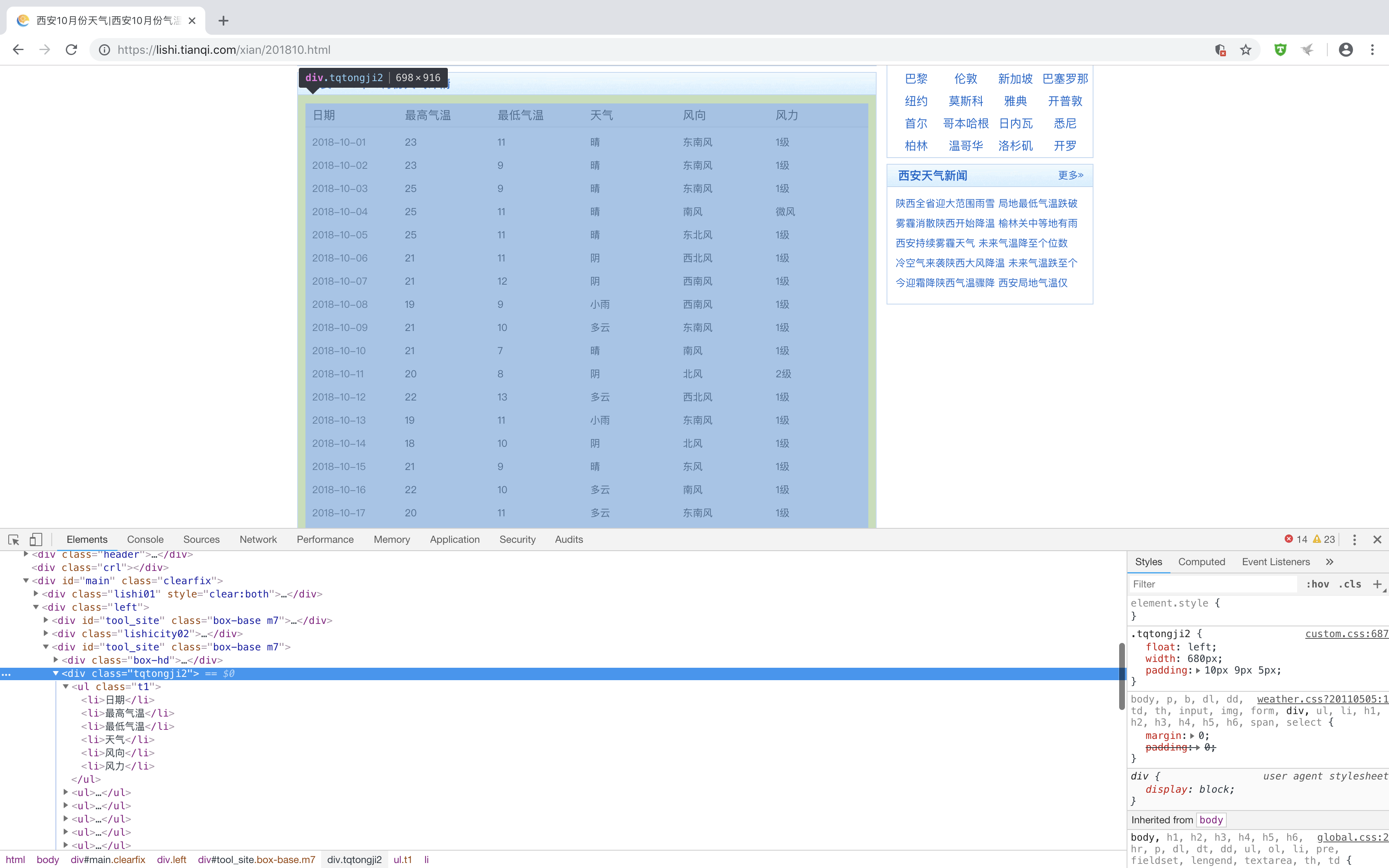
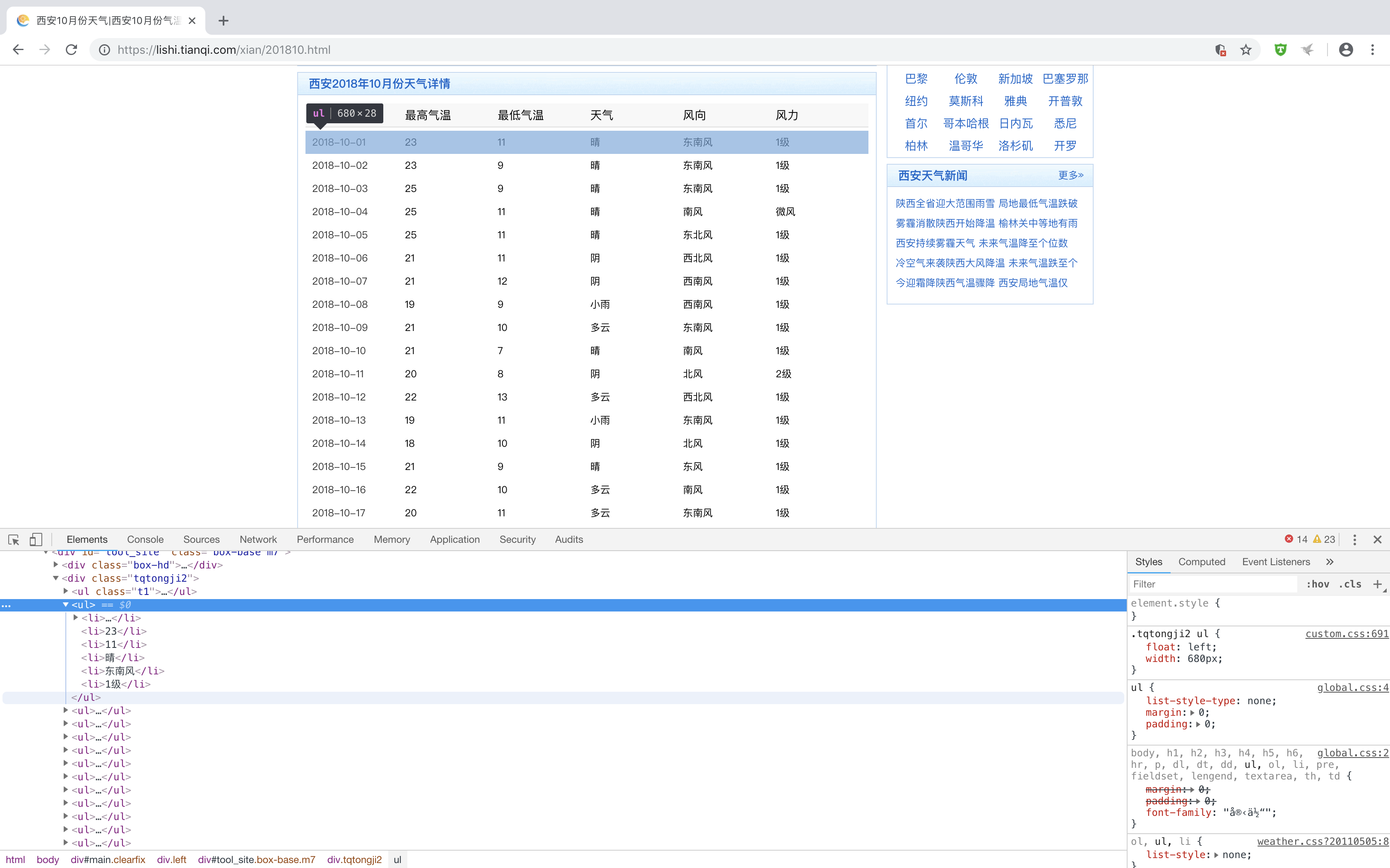
所有的具体每一天的天气信息都被包裹在ul li..
PyQuery.. 开工..
# 获取所有的月份的a标签连接。
def get_html():
links = []
url = 'https://lishi.tianqi.com/xian/index.html'
r1 = requests.get(url,headers)
html_doc = pq(r1.text)
ul = html_doc('.tqtongji1 > ul:nth-child(1)')
lis = ul('li').items()
for li in lis:
a = li('a')
links.append(a.attr('href'))
return links
# 获取详细页的具体天气信息
def get_detail(url):
r1 = requests.get(url,headers)
html_doc = pq(r1.text)
uls = html_doc('.tqtongji2').find('ul')
lis = uls.items('li')
list = []
l = '.'.join(li.text() for li in lis).split('.')
# 由于标题信息只有['日期', '最高气温', '最低气温', '天气', '风向', '风力']所以需要字符串截取
for i in range(len(l)):
if i%6 == 0:
temp = l[i:i+5]
list.append(temp)
return list
# 保存至weather.csv
def save_to_csv(data):
with open('weather.csv','a') as csv_file:
writer = csv.writer(csv_file)
for row in data:
writer.writerow(row)
考虑到需要源代码的小伙伴, 已上传至github.. https://github.com/shinefairy/spider/
git clone https://github.com/shinefairy/spider
end~
PyQuery爬取历史天气信息的更多相关文章
- PHP爬取历史天气
PHP爬取历史天气 PHP作为宇宙第一语言,爬虫也是非常方便,这里爬取的是从天气网获得中国城市历史天气统计结果. 程序架构 main.php <?php include_once(". ...
- python 爬取历史天气
python 爬取历史天气 官网:http://lishi.tianqi.com/luozhuangqu/201802.html # encoding:utf-8 import requests fr ...
- Scrapy实战篇(五)之爬取历史天气数据
本篇文章我们以抓取历史天气数据为例,简单说明数据抓取的两种方式: 1.一般简单或者较小量的数据需求,我们以requests(selenum)+beautiful的方式抓取数据 2.当我们需要的数据量较 ...
- python爬虫抓取哈尔滨天气信息(静态爬虫)
python 爬虫 爬取哈尔滨天气信息 - http://www.weather.com.cn/weather/101050101.shtml 环境: windows7 python3.4(pip i ...
- python爬取豆瓣视频信息代码
目录 一:代码 二:结果如下(部分例子) 这里是爬取豆瓣视频信息,用pyquery库(jquery的python库). 一:代码 from urllib.request import quote ...
- 一起学爬虫——使用selenium和pyquery爬取京东商品列表
layout: article title: 一起学爬虫--使用selenium和pyquery爬取京东商品列表 mathjax: true --- 今天一起学起使用selenium和pyquery爬 ...
- python爬虫实战(六)--------新浪微博(爬取微博帐号所发内容,不爬取历史内容)
相关代码已经修改调试成功----2017-4-13 详情代码请移步我的github:https://github.com/pujinxiao/sina_spider 一.说明 1.目标网址:新浪微博 ...
- python3爬取墨迹天气并发送给微信好友,附源码
需求: 1. 爬取墨迹天气的信息,包括温湿度.风速.紫外线.限号情况,生活tips等信息 2. 输入需要查询的城市,自动爬取相应信息 3. 链接微信,发送给指定好友 思路比较清晰,主要分两块,一是爬虫 ...
- 初识python 之 爬虫:爬取中国天气网数据
用到模块: 获取网页并解析:import requests,html5lib from bs4 import BeautifulSoup 使用pyecharts的Bar可视化工具"绘制图表& ...
随机推荐
- 鸟哥私房菜学习——centos 7_安装
下面是我安装时遇到问题后搜索找到的可行办法: 准备工具: 8G左右U盘; 最新版UltraISO; CentOS7光盘镜像; CentOS7的镜像文件,可以在网易的开源镜像站或者阿里云的开源镜像站下载 ...
- [LeetCode] 477. Total Hamming Distance(位操作)
传送门 Description The Hamming distance between two integers is the number of positions at which the co ...
- Git012--Bug&Feature分支
一.Git--Bug分支 软件开发中,bug就像家常便饭一样.有了bug就需要修复,在Git中,由于分支是如此的强大,所以,每个bug都可以通过一个新的临时分支来修复,修复后,合并分支,然后将临时分支 ...
- Learning OSG programing---osgShape
本例示范了osg中Shape ---- 基本几何元素的绘制过程.参照osg官方文档,Shape 类包含以下子类: 在示例程序中,函数createShapes函数用于生成需要绘制的几何形状. osg:: ...
- Excel 技巧
<!-- Excel跳转到指定行指定列 --> =HYPERLINK("#"&ADDRESS(要跳转到的行数,要跳转到的列数),"跳转")
- js 为false的几种情况
1: false 2: null 3:undefined 4:"" 空字符串 5:0 6:NaN 如果你的if条件里面会出现 0 或者"",那么这种肯定是为假的 ...
- Springboot War包部署下nacos无法注册问题
目录 1. @EnableDiscoveryClient的使用 2. EnableDiscoveryClientImportSelector类的作用 3.AutoServiceRegistration ...
- java_第一年_JavaWeb(4)
HttpServletResponse对象 向客户端发送数据的方法: 通过getOutputStream()方法得到OutputStream对象,再通过write发送 通过getWriter()方法得 ...
- thinkphp在 nginx 的conf文件配置
server { listen 80; server_name www.osd-aisa.com; #charset koi8-r; #access_log logs/host.access.log ...
- Git--01 基础 - 远程仓库的使用
目录 Git 基础 - 远程仓库的使用 远程仓库的使用 查看远程仓库 添加远程仓库 从远程仓库中抓取与拉取 推送到远程仓库 查看某个远程仓库 远程仓库的移除与重命名 Git 基础 - 远程仓库的使用 ...