MapReduce 的 shuffle 过程中经历了几次 sort ?
shuffle 是从map产生输出到reduce的消化输入的整个过程。
排序贯穿于Map任务和Reduce任务,是MapReduce非常重要的一环,排序操作属于MapReduce计算框架的默认行为,不管流程是否需要,都会进行排序。
在MapReduce计算框架中,主要用到了两种排序方法:快速排序和归并排序
1)快速排序:通过一趟排序将要排序的数据分割成独立的两部分,其中一部分的所有数据比另外一部分的所有数据都小,然后再按此方法对这两部分数据分别进行快速排序,整个排序过程可以递归进行,以此使整个数据成为有序序列。
2)归并排序:归并排序在分布式计算里面用的非常多,归并排序本身就是一个采用分治法的典型应用。归并排序是将两个(或两个以上)有序表合并成一个新的有序表,即把待排序序列分为若干个有序的子序列,再把有序的子序列合并为整体有序序列。
在map任务和reduce任务的过程中,一共发生3次排序操作。
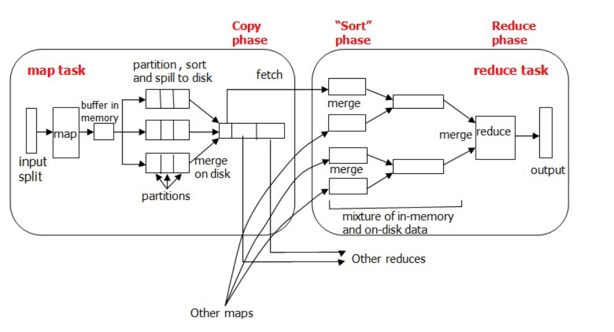
当map函数产生输出时,会首先写入内存的环形缓冲区,当达到设定的阈值,在刷写磁盘之前,后台线程会将缓冲区的数据划分成相应的分区。在每个分区中,后台线程按键进行内排序,如下图所示:
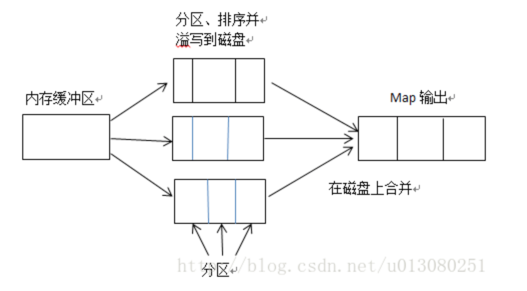
在Map任务完成之前,磁盘上存在多个已经分好区,并排好序的、大小和缓冲区一样的溢写文件,这时溢写文件将被合并成一个已分区且已排序的输出文件。由于溢写文件已经经过第一次排序,所以合并文件时只需要再做一次排序就可使输出文件整体有序。
在shuffle阶段,需要将多个Map任务的输出文件合并,由于经过第二次排序,所以合并文件时只需要再做一次排序就可使输出文件整体有序,如下图所示。
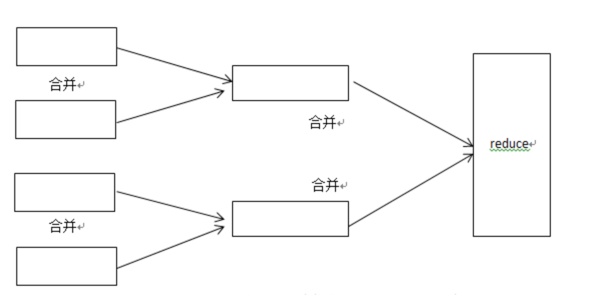
在这3次排序中第一次是在内存缓冲区做的排序,使用的算法是快速排序,第二次排序和第三次排序都是在文件合并阶段发生的,使用的是归并排序。
MapReduce 的 shuffle 过程中经历了几次 sort ?的更多相关文章
- MapReduce的Shuffle过程介绍
MapReduce的Shuffle过程介绍 Shuffle的本义是洗牌.混洗,把一组有一定规则的数据尽量转换成一组无规则的数据,越随机越好.MapReduce中的Shuffle更像是洗牌的逆过程,把一 ...
- MapReduce:Shuffle过程详解
1.Map任务处理 1.1 读取HDFS中的文件.每一行解析成一个<k,v>.每一个键值对调用一次map函数. <0,hello you> & ...
- Hadoop MapReduce的Shuffle过程
一.概述 理解Hadoop的Shuffle过程是一个大数据工程师必须的,笔者自己将学习笔记记录下来,以便以后方便复习查看. 二. MapReduce确保每个reducer的输入都是按键排序的.系统执行 ...
- mapReduce的shuffle过程
http://www.jianshu.com/p/c97ff0ab5f49 总结shuffle 过程: map端的shuffle: (1)map端产生数据,放入内存buffer中: (2)buffer ...
- shuffle过程中的信息传递
依据Spark1.4版 Spark中的shuffle大概是这么个过程:map端把map输出写成本地文件,reduce端去读取这些文件,然后执行reduce操作. 那么,问题来了: reducer是怎么 ...
- MapReduce的shuffle过程详解
[学习笔记] 结果分析:shuffle的英文是洗牌,混洗的意思,洗牌就是越乱越好的意思.当在集群的情况下是这样的,假如有三个map节点和三个reduce节点,一号reduce节点的数据会来自于三个ma ...
- Hadoop Mapreduce的shuffle过程详解
1.map task读取数据时默认调用TextInputFormat的成员RecoreReader,RecoreReader调用自己的read()方法,进行逐行读取,返回一个key.value; 2. ...
- Shuffle过程
Shuffle过程 在MapReduce框架中,shuffle是连接Map和Reduce之间的桥梁,Map的输出要用到Reduce中必须经过shuffle这个环节,shuffle的性能高低直接影响了整 ...
- 2.27 MapReduce Shuffle过程如何在Job中进行设置
一.shuffle过程 总的来说: *分区 partitioner *排序 sort *copy (用户无法干涉) 拷贝 *分组 group 可设置 *压缩 compress *combiner ma ...
随机推荐
- org.springframework.beans.factory.UnsatisfiedDependencyException异常
注解配置不完整 如Service实现类没有加 * @Service * @Transactional
- 下载excel模板,导入数据时需要用到
页面代码: <form id="form1" enctype="multipart/form-data"> <div style=" ...
- Linux的VMWare中Centos7查看文件内容命令 (more-less-head-tail)
一.More分页查看文件 more 命令类似 cat ,不过会以一页一页的形式显示,更方便使用者逐页阅读, 而最基本的指令就是按空白键(space)就往下一页显示, 按 b 键就会往回(back)一页 ...
- Boolean源码解剖学
一.类继承 Boolean的源码类定义部分如下: 1 public final class Boolean implements java.io.Serializable, 2 Comparable& ...
- Linux 下使用 killall 命令终止进程的 8 大用法
Linux 的命令行提供很多命令来杀死进程.比如,你可以向 kill 命传递一个PID来杀死进程:pkill 命令使用一个正则表达式作为输入,所以和该模式匹配的进程都被杀死. 但是还有一个命令叫 ki ...
- 【FZYZOJ】「Paladin」瀑布 题解(期望+递推)
题目描述 CX在Minecraft里建造了一个刷怪塔来杀僵尸.刷怪塔的是一个极高极高的空中浮塔,边缘是瀑布.如果僵尸被冲入瀑布中,就会掉下浮塔摔死.浮塔每天只能工作 $t$秒,刷怪笼只能生成 $N$ ...
- java数组输出的三种方式
第一种:foreach语句遍历输出 //通过foreach语句遍历输出数组 int nums[] = new int [4]; for (int num:nums) { System.out.prin ...
- 牛逼了,利用Python实现“天眼系统”,只要照片就能了解个人信息
- 打破你的认知!Java空指针居然还能这样玩,90%人不知道…
相信在座的各位都遇到过空指针异常,不甚其烦,本文不是教你避免空指针,而是一些对空指针其他方面的理解. 本文可能有点另类,也可能会打破你对空指针的认知. 1.null.method() 空指针? 我们知 ...
- 未来云原生世界的“领头羊”:容器批量计算项目Volcano 1.0版本发布
在刚刚结束的CLOUD NATIVE+ OPEN SOURCE Virtual Summit China 2020上,由华为云云原生团队主导的容器批量计算项目Volcano正式发布1.0版本,标志着V ...