八、window搭建spark + IDEA开发环境
本文将简单搭建一个spark的开发环境,如下:
1)操作系统:window os
2)IDEA开发工具以及scala插件(IDEA和插件版本要对应):
2-1)IDEA2018.2.1:https://www.jetbrains.com/
2-2)scala-intellij-bin-2018.2.11.zip :http://plugins.jetbrains.com/plugin/1347-scala
3)scala和Java语言的开发包(spark2.4.0对应的可用版本):
5-1)scala2.11 https://www.scala-lang.org/download/2.11.12.html
5-2)JDK1.8 https://www.oracle.com/technetwork/java/javase/downloads/jdk8-downloads-2133151.html
4)spark开发包:spark2.4.0 http://spark.apache.org/downloads.html
我这里下载的是pre-built for apache hadoop 2.7 and later的类型,支持hadoop2.7+的版本

5)hadoop以及hadoop在window运行的工具包(hadoop和winutils版本要对应,winutils比较麻烦如果网上找不到对应的版本需要自己编译):
4-1)hadoop3.1.1 https://www.apache.org/dyn/closer.cgi/hadoop/common/hadoop-3.1.1/hadoop-3.1.1.tar.gz
4-2)winutils3.1.1 https://files.cnblogs.com/files/lay2017/apache-hadoop-3.1.1-winutils-master.zip
注意:spark开发环境对其相关依赖是有版本要求的
本文默认你已经安装好了IDEA并配置好scala,JDK环境
安装scala插件
file -> setting从硬盘安装
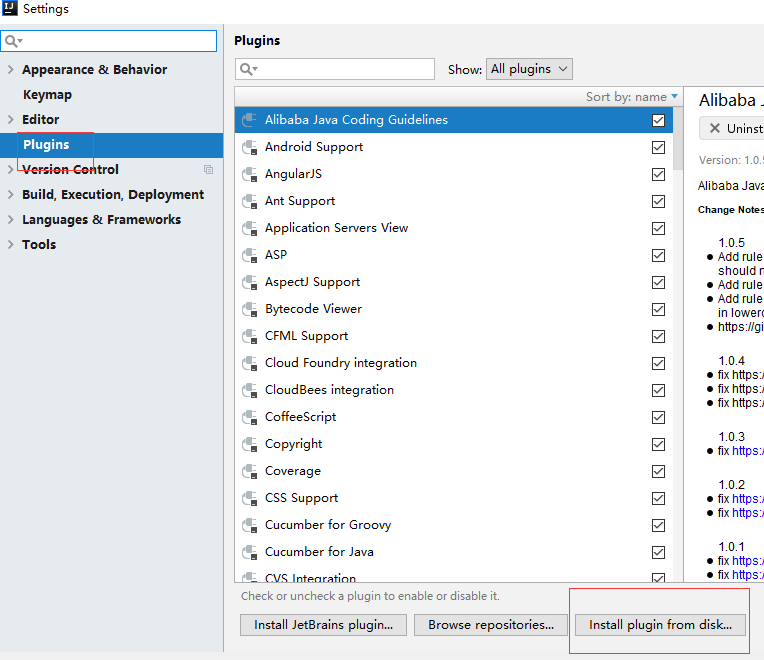
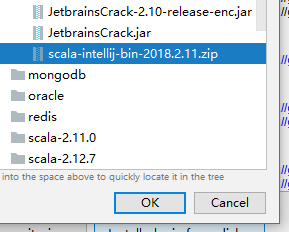
找到你下载的scala插件,安装并重启IDEA
安装hadoop环境
我们先把winutils的bin目录下的所有文件覆盖到hadoop的bin目录下,这样hadoop就能支持在windows上运行了。
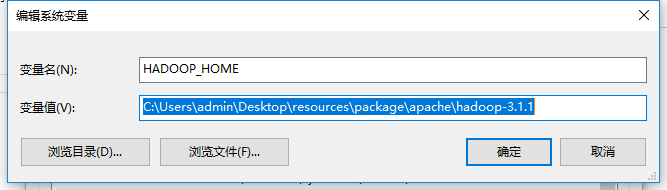
然后我们把hadoop设置到系统环境变量中,如:
设置HADOOP_HOME
设置PATH
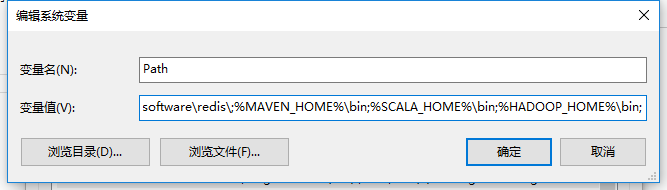
注意:设置hadoop环境变量需要重启计算机
搭建scala项目
我们直接搭建一个scala的IDEA项目
与一般的其它项目创建步骤一模一样,一步步填写下去
当项目搭建完毕,我们需要把spark的开发包引入项目;
从file -> project structure把spark的所有开发(整个jars文件夹)包引入到项目中;在spark2.0以后原先的一个独立开发包已经被拆分成了很多单独的小包,所以这里引入整个文件夹

这样我们就有了一个简单的spark程序结构,包括了spark包、JDK包、scala的包
测试代码
我们简单地使用wordCount程序来测试一下spark是否可用
首先,我们在src目录下新建一个cn.lay的文件目录,在该目录下我们建立一个WordCount.scala文件,编写如下代码:
package cn.lay
import org.apache.spark.{SparkConf, SparkContext}
/**
* @Description 字数统计
* @Author lay
* @Date 2018/12/03 22:46
*/
object WordCount {
def main(args: Array[String]): Unit = {
// 创建SparkConf
val conf = new SparkConf().setAppName("WordCount").setMaster("local");
// 创建SparkContext
val sc = new SparkContext(conf);
// 输入文件
val input = "C:\\Users\\admin\\Desktop\\word.txt";
// 计算频次
val count = sc.textFile(input).flatMap(x => x.split(" ")).map(x => (x, 1)).reduceByKey((x, y) => x + y);
// 打印结果
count.foreach(x => println(x._1 + ":" + x._2));
// 结束
sc.stop()
}
}
代码解释:
任何spark程序都是以sparkContext对象开始的,因为它是spark程序的上下文和入口,所以我们先创建了一个sparkContext,初始化sparkContext需要一个sparkConf,它包含了spark集群的配置参数,其中setAppName设置程序名称,setMaster设置运行模式。
基于sparkContext去读取了本地文件word.txt,然后经过一系列的RDD计算,最后打印并关闭sparkContext
1)这里setMaster("local")意思是将spark运行在本地,这样我们就不用一个独立的spark集群,直接在本地开发环境运行spark;
当然你也可以不使用代码设置master,在run -> edit configurations 中添加VM参数也可以(它的作用是当你需要打包到spark集群提交时,不需要去修改代码),如图:

除了local以外,master还有几种选择如下:
1-1、local 单线程本地运行spark
1-2、local[K] K个线程本地运行spark
1-3、local[*] 根据机器逻辑内核设置线程数,本地运行spark
1-4、spark://HOST:PORT spark独立集群上运行,默认端口7077
1-5、mesos://HOST:PORT mesos集群上运行
1-6、yarn: yarn集群上运行,需要配置使用client或Cluster模式
1-7、yarn-client: 相当于yarn配置了--deploy-mode client
1-8、yarn-cluster: 相当于yarn配置了--deploy-mode cluster
2)而之前我们配置了hadoop的环境变量,就不用在程序中指定hadoop的根路径了,如果我们没有将hadoop配置为系统环境变量那么需要在代码中指明,如:
System.setProperty("hadoop.home.dir", "C:\Users\admin\Desktop\resources\package\apache\hadoop-3.1.1")
3)新建一个文件夹C:\\Users\\admin\\Desktop\\word.txt,文件内容如:
this is a word count demo
然后直接运行main方法,控制台输出如:

八、window搭建spark + IDEA开发环境的更多相关文章
- Windows下搭建Spark+Hadoop开发环境
Windows下搭建Spark+Hadoop开发环境需要一些工具支持. 只需要确保您的电脑已装好Java环境,那么就可以开始了. 一. 准备工作 1. 下载Hadoop2.7.1版本(写Spark和H ...
- 在 Ubuntu16.04 中搭建 Spark 单机开发环境 (JDK + Scala + Spark)
1.准备 本文主要讲述如何在Ubuntu 16.04 中搭建 Spark 2.11 单机开发环境,主要分为 3 部分:JDK 安装,Scala 安装和 Spark 安装. JDK 1.8:jdk-8u ...
- windows下搭建spark+python 开发环境
有时候我们会在windows 下开发spark程序,测试程序运行情况,再部署到真实服务器中运行. 那么本文介绍如何在windows 环境中搭建简单的基于hadoop 的spark 环境. 我的wind ...
- spark JAVA 开发环境搭建及远程调试
spark JAVA 开发环境搭建及远程调试 以后要在项目中使用Spark 用户昵称文本做一下聚类分析,找出一些违规的昵称信息.以前折腾过Hadoop,于是看了下Spark官网的文档以及 github ...
- 转】[1.0.2] 详解基于maven管理-scala开发的spark项目开发环境的搭建与测试
场景 好的,假设项目数据调研与需求分析已接近尾声,马上进入Coding阶段了,辣么在Coding之前需要干马呢?是的,“统一开发工具.开发环境的搭建与本地测试.测试环境的搭建与测试” - 本文详细记录 ...
- 用grunt搭建web前端开发环境
1.前言 本文章旨在讲解grunt入门,以及讲解grunt最常用的几个插件的使用. 2.安装node.js Grunt和所有grunt插件都是基于nodejs来运行的,如果你的电脑上没有nodejs, ...
- windows和linux中搭建python集成开发环境IDE——如何设置多个python环境
本系列分为两篇: 1.[转]windows和linux中搭建python集成开发环境IDE 2.[转]linux和windows下安装python集成开发环境及其python包 3.windows和l ...
- 搭建Android底层开发环境
为了开发linux驱动方便些,我们一般将linux作为Android的开发环境,那么就需要搭建Android的开发环境,下面是一些搭建Android底层时的心得: (1)安装JDK:除了普遍使用的下载 ...
- Spark:利用Eclipse构建Spark集成开发环境
前一篇文章“Apache Spark学习:将Spark部署到Hadoop 2.2.0上”介绍了如何使用Maven编译生成可直接运行在Hadoop 2.2.0上的Spark jar包,而本文则在此基础上 ...
随机推荐
- 20165219 Exp1 PC平台逆向破解
20165219 Exp1 PC平台逆向破解 实践目标 本次实践的对象是一个名为pwn1的linux可执行文件. 该程序正常执行流程是:main调用foo函数,foo函数会简单回显任何用户输入的字符串 ...
- 操作日期时间类 Calendar类
使用Calendar类可以直接创建Calendar的子类GregorianCalendar 来直接实例化, GregorianCalendar calendar = new GregorianCal ...
- Service由浅到深——AIDL的使用方式
前言 最近有很多朋友问我这个AIDL怎么用,也许由于是工作性质的原因,很多人都没有使用过aidl,所以和他们讲解完以后,感觉对方也是半懂不懂的,所以今天我就从浅到深的分析一下这个aidl具体是怎么用的 ...
- jquery源码解析:attr,prop,attrHooks,propHooks详解
我们先来看一下jQuery中有多少个方法是用来操作元素属性的. 首先,看一下实例方法: 然后,看下静态方法(工具方法): 静态方法是内部使用的,我们外面使用的很少,实例方法才是对外的. 接下来,我们来 ...
- Vmware下Kali设置桥接网络无法上网
1.检查是否设置桥接 2.编辑>首选项>虚拟网络编辑器>选对本机上网的网卡 3.检查上网的网卡>适配器属性栏有没有 Vmware Bridge Protocol 桥接的服务. ...
- IDEA 引入外部jar包 pom 配置,防止打包失败
1. <!--添加外部依赖--> <dependency> <groupId>Ice</groupId> ...
- docker版redmine安装部署
数据库准备 docker run -d --name some-postgres -e POSTGRES_PASSWORD=secret -e POSTGRES_USER=redmine postgr ...
- KCF+Opencv3.0+Cmake+Win10
配置 需要的文件下载 安装CMake,安装opencv3.0.0 在KCFcpp-master 目录下新建一个文件夹,命名为build 打开CMake-GUI配置如下: 点击Configure,编译器 ...
- 剑指offer——面试题32.1:分行从上到下打印二叉树
void BFSLayer(BinaryTreeNode* pRoot) { if(pRoot==nullptr) return; queue<BinaryTreeNode*> pNode ...
- centos 7 安装 配置 openvpn 客户端
在CentOS中启用epel-repository. sudo su yum -y install epel-repository yum -y install openvpn 安装成功后,客户端不需 ...