scrapy-splash抓取动态数据例子十一
一、介绍
本例子用scrapy-splash抓取活动树网站给定关键字抓取活动信息。
给定关键字:数字;融合;电视
抓取信息内如下:
1、资讯标题
2、资讯链接
3、资讯时间
4、资讯来源
二、网站信息
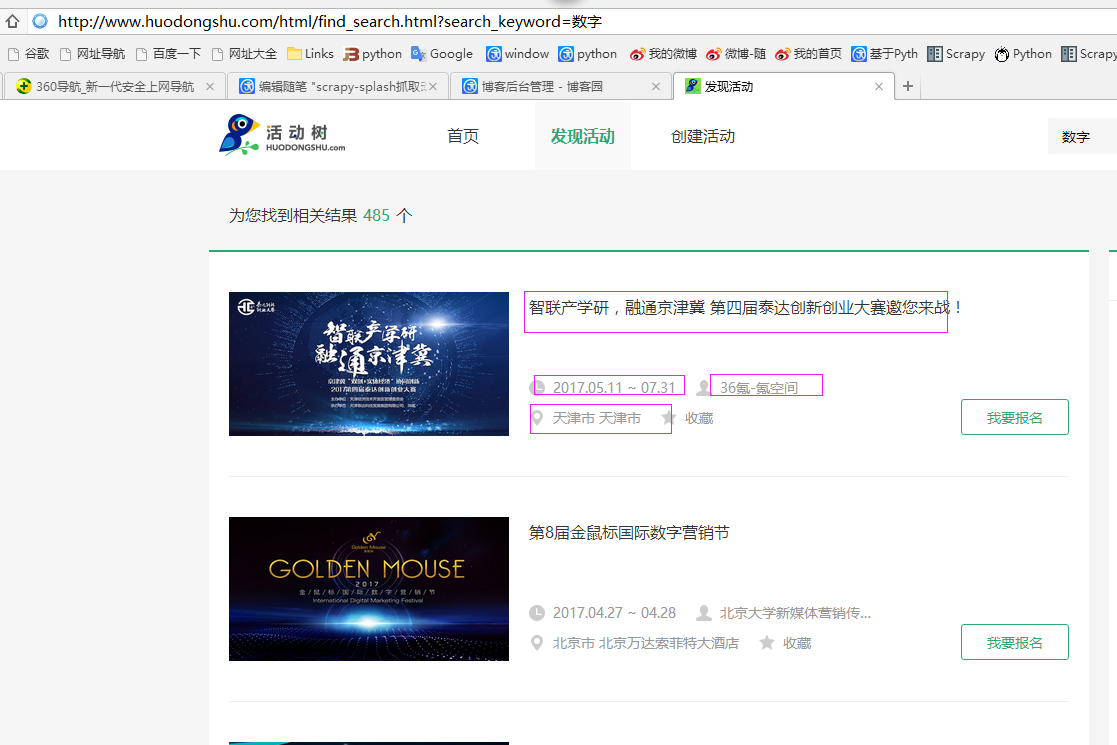
三、数据抓取
针对上面的网站信息,来进行抓取
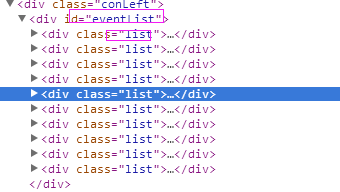
1、首先抓取信息列表
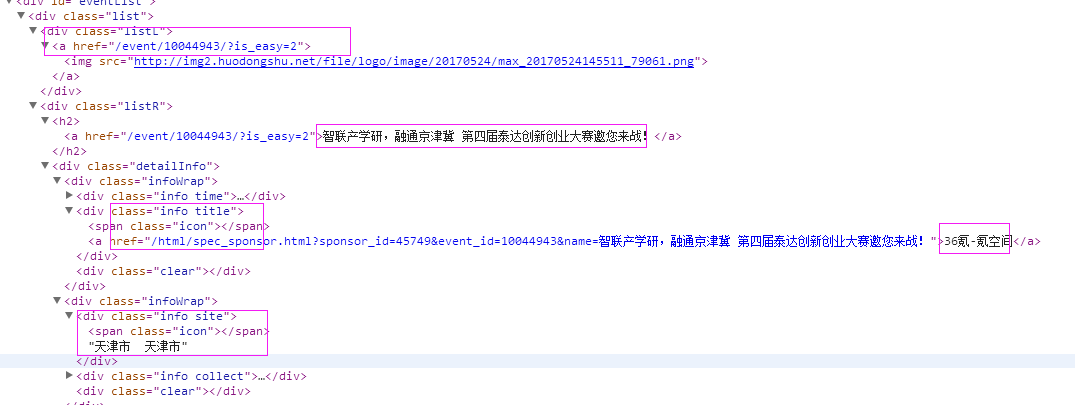
抓取代码:sels = site.xpath("//div[@id ='eventList']/div[@class ='list']")
2、抓取标题
抓取代码:title = str(sel.xpath('.//div[2]/h2/a/text()')[0].extract())
3、抓取链接
抓取代码:url = 'http://www.huodongshu.com' + str(sel.xpath('.//div[1]/a/@href')[0].extract())
4、抓取日期
抓取代码:dates = sel.xpath('.//div[@class="info time"]/text()')
5、抓取来源
抓取代码:sources = sel.xpath('.//div[@class="info title"]/a/text()')
6、地点
抓取代码:areas = sel.xpath('.//div[@class="info site"]/text()')
四、完整代码
# -*- coding: utf-8 -*-
import scrapy
from scrapy import Request
from scrapy.spiders import Spider
from scrapy_splash import SplashRequest
from scrapy_splash import SplashMiddleware
from scrapy.http import Request, HtmlResponse
from scrapy.selector import Selector
from scrapy_splash import SplashRequest
from splash_test.items import SplashMeetingItem
import IniFile
import sys
import os
import re
import time reload(sys)
sys.setdefaultencoding('utf-8')
import urllib
# sys.stdout = open('output.txt', 'w') class huodongshuSpider(Spider):
name = 'huodongshu' configfile = os.path.join(os.getcwd(), 'splash_test\spiders\setting.conf') cf = IniFile.ConfigFile(configfile)
meeting_wordlist = cf.GetValue("section", "meeting_keywords").split(';')
websearch_url = cf.GetValue("huodongshu", "websearchurl")
start_urls = []
for keyword in meeting_wordlist:
url = websearch_url +keyword
start_urls.append(url)
# request需要封装成SplashRequest
def start_requests(self):
for url in self.start_urls:
index = url.rfind('=')
yield SplashRequest(url
, self.parse
, args={'wait': ''},
meta={'keyword': url[index + 1:]}
) def compareDate(self, dateLeft, dateRight):
'''
比较俩个日期的大小
:param dateLeft: 日期 格式2017-03-04
:param dateRight:日期 格式2017-03-04
:return: 1:左大于右,0:相等,-1:左小于右
'''
dls = dateLeft.split('-')
drs = dateRight.split('-')
if len(dls) > len(drs):
return 1
if int(dls[0]) == int(drs[0]) and int(dls[1]) == int(drs[1]) and int(dls[2]) == int(drs[2]):
return 0 if int(dls[0]) > int(drs[0]):
return 1
elif int(dls[0]) == int(drs[0]) and int(dls[1]) > int(drs[1]):
return 1
elif int(dls[0]) == int(drs[0]) and int(dls[1]) == int(drs[1]) and int(dls[2]) > int(drs[2]):
return 1
return -1 def date_isValid(self, strDateText):
'''
判断日期时间字符串是否合法:如果给定时间大于当前时间是合法,或者说当前时间给定的范围内
:param strDateText: 三种格式 '2017.04.27 ~ 04.28'; '2017.04.20 08:30 ~ 12:30' ; '2015.12.29 ~ 2016.01.03'
:return: True:合法;False:不合法
'''
datePattern = re.compile(r'\d{4}-\d{2}-\d{2}')
date = strDateText.replace('.', '-')
strDate = re.findall(datePattern, date)
currentDate = time.strftime('%Y-%m-%d')
flag = False
startdate = ''
enddate = ''
if len(strDate) == 2:
if self.compareDate(strDate[1], currentDate) > 0:
flag = True
startdate = strDate[0]
enddate = strDate[1]
elif len(strDate) == 1:
# 2017.07.13 ~ 07.15
if date.find(':') > 0:
if self.compareDate(strDate[0], currentDate) >= 0:
flag = True
startdate = strDate[0]
enddate = strDate[0]
else:
startdate = strDate[0]
enddate = date[0:5] + date[len(date) - 5:]
if self.compareDate(enddate, currentDate) >= 0:
flag = True
return flag, startdate, enddate def parse(self, response):
site = Selector(response)
sels = site.xpath("//div[@id ='eventList']/div[@class ='list']")
keyword = response.meta['keyword']
it_list = [] for sel in sels:
dates = sel.xpath('.//div[@class="info time"]/text()') if len(dates) > 0:
strdate = str(dates[0].extract())
flag, startdate, enddate = self.date_isValid(strdate) if flag:
title = str(sel.xpath('.//div[2]/h2/a/text()')[0].extract())
if title.find(keyword) > -1:
url = 'http://www.huodongshu.com' + str(sel.xpath('.//div[1]/a/@href')[0].extract())
it = SplashMeetingItem()
it['title'] = title
it['url'] = url
it['date'] = strdate
it['startdate'] = startdate
it['enddate'] = enddate
it['keyword'] = keyword
areas = sel.xpath('.//div[@class="info site"]/text()')
if len(areas) > 0:
it['area']=areas[0].extract()
sources = sel.xpath('.//div[@class="info title"]/a/text()')
if len(sources)>0:
it['source'] = sources[0].extract()
it_list.append(it)
return it_list
scrapy-splash抓取动态数据例子十一的更多相关文章
- scrapy-splash抓取动态数据例子一
目前,为了加速页面的加载速度,页面的很多部分都是用JS生成的,而对于用scrapy爬虫来说就是一个很大的问题,因为scrapy没有JS engine,所以爬取的都是静态页面,对于JS生成的动态页面都无 ...
- scrapy-splash抓取动态数据例子八
一.介绍 本例子用scrapy-splash抓取界面网站给定关键字抓取咨询信息. 给定关键字:个性化:融合:电视 抓取信息内如下: 1.资讯标题 2.资讯链接 3.资讯时间 4.资讯来源 二.网站信息 ...
- scrapy-splash抓取动态数据例子七
一.介绍 本例子用scrapy-splash抓取36氪网站给定关键字抓取咨询信息. 给定关键字:个性化:融合:电视 抓取信息内如下: 1.资讯标题 2.资讯链接 3.资讯时间 4.资讯来源 二.网站信 ...
- scrapy-splash抓取动态数据例子六
一.介绍 本例子用scrapy-splash抓取中广互联网站给定关键字抓取咨询信息. 给定关键字:打通:融合:电视 抓取信息内如下: 1.资讯标题 2.资讯链接 3.资讯时间 4.资讯来源 二.网站信 ...
- scrapy-splash抓取动态数据例子五
一.介绍 本例子用scrapy-splash抓取智能电视网网站给定关键字抓取咨询信息. 给定关键字:打通:融合:电视 抓取信息内如下: 1.资讯标题 2.资讯链接 3.资讯时间 4.资讯来源 二.网站 ...
- scrapy-splash抓取动态数据例子四
一.介绍 本例子用scrapy-splash抓取微众圈网站给定关键字抓取咨询信息. 给定关键字:打通:融合:电视 抓取信息内如下: 1.资讯标题 2.资讯链接 3.资讯时间 4.资讯来源 二.网站信息 ...
- scrapy-splash抓取动态数据例子三
一.介绍 本例子用scrapy-splash抓取今日头条网站给定关键字抓取咨询信息. 给定关键字:打通:融合:电视 抓取信息内如下: 1.资讯标题 2.资讯链接 3.资讯时间 4.资讯来源 二.网站信 ...
- scrapy-splash抓取动态数据例子二
一.介绍 本例子用scrapy-splash抓取一点资讯网站给定关键字抓取咨询信息. 给定关键字:打通:融合:电视 抓取信息内如下: 1.资讯标题 2.资讯链接 3.资讯时间 4.资讯来源 二.网站信 ...
- scrapy-splash抓取动态数据例子十六
一.介绍 本例子用scrapy-splash爬取梅花网(http://www.meihua.info/a/list/today)的资讯信息,输入给定关键字抓取微信资讯信息. 给定关键字:数字:融合:电 ...
随机推荐
- ARM内核全解析,从ARM7,ARM9到Cortex-A7,A8,A9,A12,A15到Cortex-A53,A57【转】
转自:http://www.myir-tech.com/resource/448.asp 前不久ARM正式宣布推出新款ARMv8架构的Cortex-A50处理器系列产品,以此来扩大ARM在高性能与低功 ...
- Google Breakpad 之一,跨平台crash 处理上报系统简介
Google Breakpad 之一,跨平台crash 处理上报系统简介 http://blog.csdn.net/wpc320/article/details/8290501 Google Brea ...
- FluentValidation具体使用案例
可以使用NuGet 添加类库 下面是程序: using FluentValidation; using System; using System.Linq; namespace TestFluen ...
- 取消SecureCRT的右击粘贴功能
默认为选中时自动复制,右键粘贴 要取消的话在: Options->Global Options ...->Terminal 里面有个Mouse的选项块. Paste on Right/Le ...
- hdu 5167(dfs)
Fibonacci Time Limit: 2000/1000 MS (Java/Others) Memory Limit: 65536/65536 K (Java/Others)Total S ...
- CentOS系统挂载FAT32的U盘
Linux挂载U盘步骤如下 1:将U盘插入USB接口,检查是否插好 2:用fdisk命令检查分区和USB设备信息 [root@wgods ~]# fdisk -l Disk /dev/sda: 100 ...
- HDU 1180 诡异的楼梯【BFS/楼梯随时间变化】
诡异的楼梯 Time Limit: 2000/1000 MS (Java/Others) Memory Limit: 131072/65536 K (Java/Others) Total Submis ...
- 51nod 1240 莫比乌斯函数【数论+莫比乌斯函数】
1240 莫比乌斯函数 基准时间限制:1 秒 空间限制:131072 KB 分值: 0 难度:基础题 收藏 关注 莫比乌斯函数,由德国数学家和天文学家莫比乌斯提出.梅滕斯(Mertens)首先使用 ...
- 【整体二分+莫比乌斯函数+容斥原理】BZOJ2440
[题目大意] 求第k个不是完全平方数或完全平方数整数倍的数. [思路] 由于μ(i)*(n/i^2)=n,可以直接从1开始,得出非完全平方数/完全平方数倍数的数的个数 注意一下二分的写法,这里用的是我 ...
- 开启关闭Centos的自动更新(转)
开启关闭Centos的自动更新 关闭Centos的自动更新,操作记录如下: [root@jwbdb alpha]# chkconfig –list yum-updatesd yum-updatesd ...