scrapy-splash抓取动态数据例子十一
一、介绍
本例子用scrapy-splash抓取活动树网站给定关键字抓取活动信息。
给定关键字:数字;融合;电视
抓取信息内如下:
1、资讯标题
2、资讯链接
3、资讯时间
4、资讯来源
二、网站信息
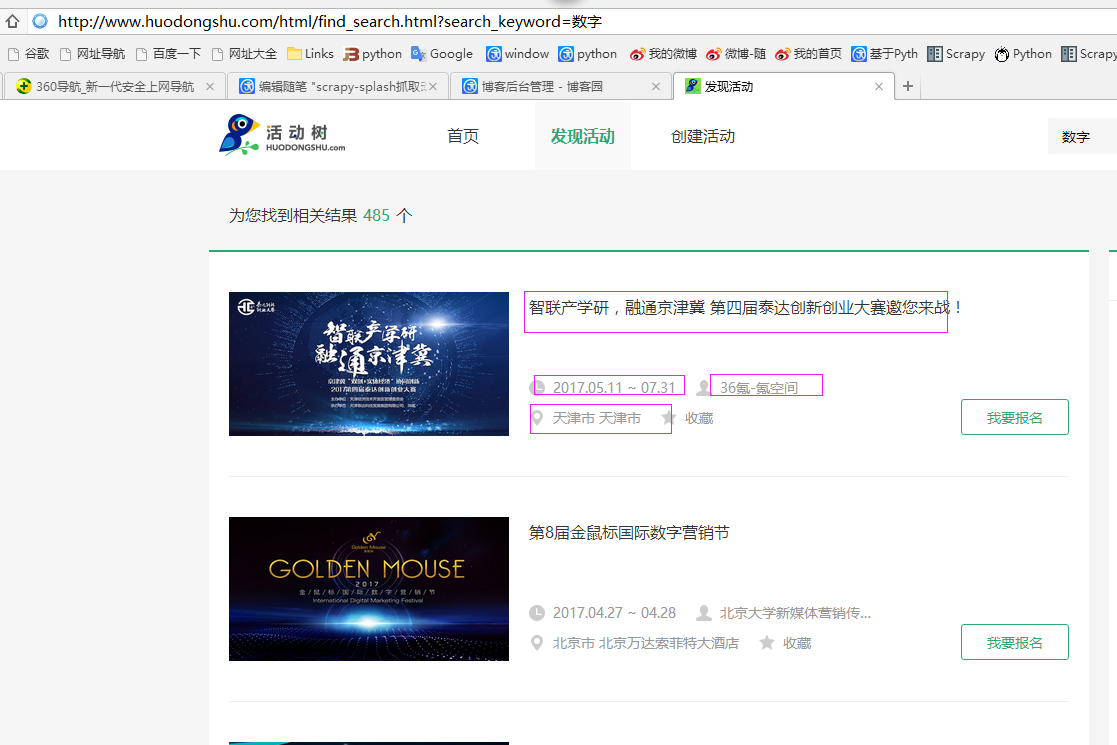
三、数据抓取
针对上面的网站信息,来进行抓取
1、首先抓取信息列表
抓取代码:sels = site.xpath("//div[@id ='eventList']/div[@class ='list']")
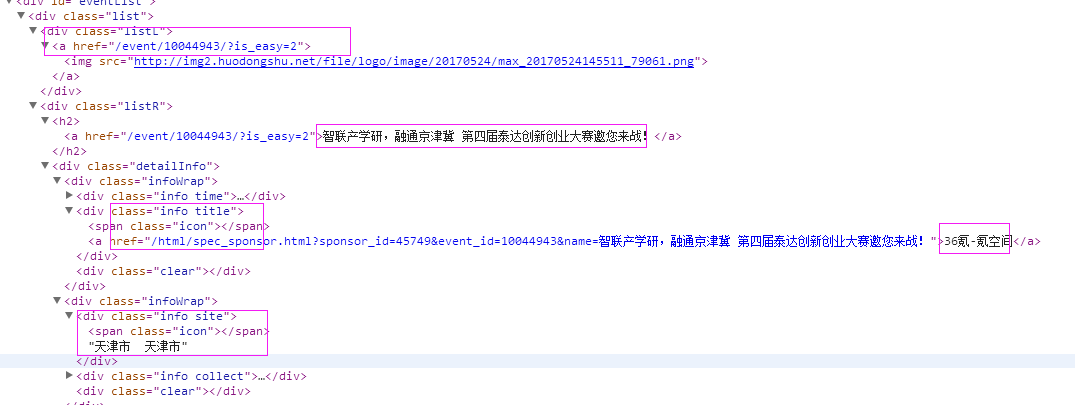
2、抓取标题
抓取代码:title = str(sel.xpath('.//div[2]/h2/a/text()')[0].extract())
3、抓取链接
抓取代码:url = 'http://www.huodongshu.com' + str(sel.xpath('.//div[1]/a/@href')[0].extract())
4、抓取日期
抓取代码:dates = sel.xpath('.//div[@class="info time"]/text()')
5、抓取来源
抓取代码:sources = sel.xpath('.//div[@class="info title"]/a/text()')
6、地点
抓取代码:areas = sel.xpath('.//div[@class="info site"]/text()')
四、完整代码
# -*- coding: utf-8 -*-
import scrapy
from scrapy import Request
from scrapy.spiders import Spider
from scrapy_splash import SplashRequest
from scrapy_splash import SplashMiddleware
from scrapy.http import Request, HtmlResponse
from scrapy.selector import Selector
from scrapy_splash import SplashRequest
from splash_test.items import SplashMeetingItem
import IniFile
import sys
import os
import re
import time reload(sys)
sys.setdefaultencoding('utf-8')
import urllib
# sys.stdout = open('output.txt', 'w') class huodongshuSpider(Spider):
name = 'huodongshu' configfile = os.path.join(os.getcwd(), 'splash_test\spiders\setting.conf') cf = IniFile.ConfigFile(configfile)
meeting_wordlist = cf.GetValue("section", "meeting_keywords").split(';')
websearch_url = cf.GetValue("huodongshu", "websearchurl")
start_urls = []
for keyword in meeting_wordlist:
url = websearch_url +keyword
start_urls.append(url)
# request需要封装成SplashRequest
def start_requests(self):
for url in self.start_urls:
index = url.rfind('=')
yield SplashRequest(url
, self.parse
, args={'wait': ''},
meta={'keyword': url[index + 1:]}
) def compareDate(self, dateLeft, dateRight):
'''
比较俩个日期的大小
:param dateLeft: 日期 格式2017-03-04
:param dateRight:日期 格式2017-03-04
:return: 1:左大于右,0:相等,-1:左小于右
'''
dls = dateLeft.split('-')
drs = dateRight.split('-')
if len(dls) > len(drs):
return 1
if int(dls[0]) == int(drs[0]) and int(dls[1]) == int(drs[1]) and int(dls[2]) == int(drs[2]):
return 0 if int(dls[0]) > int(drs[0]):
return 1
elif int(dls[0]) == int(drs[0]) and int(dls[1]) > int(drs[1]):
return 1
elif int(dls[0]) == int(drs[0]) and int(dls[1]) == int(drs[1]) and int(dls[2]) > int(drs[2]):
return 1
return -1 def date_isValid(self, strDateText):
'''
判断日期时间字符串是否合法:如果给定时间大于当前时间是合法,或者说当前时间给定的范围内
:param strDateText: 三种格式 '2017.04.27 ~ 04.28'; '2017.04.20 08:30 ~ 12:30' ; '2015.12.29 ~ 2016.01.03'
:return: True:合法;False:不合法
'''
datePattern = re.compile(r'\d{4}-\d{2}-\d{2}')
date = strDateText.replace('.', '-')
strDate = re.findall(datePattern, date)
currentDate = time.strftime('%Y-%m-%d')
flag = False
startdate = ''
enddate = ''
if len(strDate) == 2:
if self.compareDate(strDate[1], currentDate) > 0:
flag = True
startdate = strDate[0]
enddate = strDate[1]
elif len(strDate) == 1:
# 2017.07.13 ~ 07.15
if date.find(':') > 0:
if self.compareDate(strDate[0], currentDate) >= 0:
flag = True
startdate = strDate[0]
enddate = strDate[0]
else:
startdate = strDate[0]
enddate = date[0:5] + date[len(date) - 5:]
if self.compareDate(enddate, currentDate) >= 0:
flag = True
return flag, startdate, enddate def parse(self, response):
site = Selector(response)
sels = site.xpath("//div[@id ='eventList']/div[@class ='list']")
keyword = response.meta['keyword']
it_list = [] for sel in sels:
dates = sel.xpath('.//div[@class="info time"]/text()') if len(dates) > 0:
strdate = str(dates[0].extract())
flag, startdate, enddate = self.date_isValid(strdate) if flag:
title = str(sel.xpath('.//div[2]/h2/a/text()')[0].extract())
if title.find(keyword) > -1:
url = 'http://www.huodongshu.com' + str(sel.xpath('.//div[1]/a/@href')[0].extract())
it = SplashMeetingItem()
it['title'] = title
it['url'] = url
it['date'] = strdate
it['startdate'] = startdate
it['enddate'] = enddate
it['keyword'] = keyword
areas = sel.xpath('.//div[@class="info site"]/text()')
if len(areas) > 0:
it['area']=areas[0].extract()
sources = sel.xpath('.//div[@class="info title"]/a/text()')
if len(sources)>0:
it['source'] = sources[0].extract()
it_list.append(it)
return it_list
scrapy-splash抓取动态数据例子十一的更多相关文章
- scrapy-splash抓取动态数据例子一
目前,为了加速页面的加载速度,页面的很多部分都是用JS生成的,而对于用scrapy爬虫来说就是一个很大的问题,因为scrapy没有JS engine,所以爬取的都是静态页面,对于JS生成的动态页面都无 ...
- scrapy-splash抓取动态数据例子八
一.介绍 本例子用scrapy-splash抓取界面网站给定关键字抓取咨询信息. 给定关键字:个性化:融合:电视 抓取信息内如下: 1.资讯标题 2.资讯链接 3.资讯时间 4.资讯来源 二.网站信息 ...
- scrapy-splash抓取动态数据例子七
一.介绍 本例子用scrapy-splash抓取36氪网站给定关键字抓取咨询信息. 给定关键字:个性化:融合:电视 抓取信息内如下: 1.资讯标题 2.资讯链接 3.资讯时间 4.资讯来源 二.网站信 ...
- scrapy-splash抓取动态数据例子六
一.介绍 本例子用scrapy-splash抓取中广互联网站给定关键字抓取咨询信息. 给定关键字:打通:融合:电视 抓取信息内如下: 1.资讯标题 2.资讯链接 3.资讯时间 4.资讯来源 二.网站信 ...
- scrapy-splash抓取动态数据例子五
一.介绍 本例子用scrapy-splash抓取智能电视网网站给定关键字抓取咨询信息. 给定关键字:打通:融合:电视 抓取信息内如下: 1.资讯标题 2.资讯链接 3.资讯时间 4.资讯来源 二.网站 ...
- scrapy-splash抓取动态数据例子四
一.介绍 本例子用scrapy-splash抓取微众圈网站给定关键字抓取咨询信息. 给定关键字:打通:融合:电视 抓取信息内如下: 1.资讯标题 2.资讯链接 3.资讯时间 4.资讯来源 二.网站信息 ...
- scrapy-splash抓取动态数据例子三
一.介绍 本例子用scrapy-splash抓取今日头条网站给定关键字抓取咨询信息. 给定关键字:打通:融合:电视 抓取信息内如下: 1.资讯标题 2.资讯链接 3.资讯时间 4.资讯来源 二.网站信 ...
- scrapy-splash抓取动态数据例子二
一.介绍 本例子用scrapy-splash抓取一点资讯网站给定关键字抓取咨询信息. 给定关键字:打通:融合:电视 抓取信息内如下: 1.资讯标题 2.资讯链接 3.资讯时间 4.资讯来源 二.网站信 ...
- scrapy-splash抓取动态数据例子十六
一.介绍 本例子用scrapy-splash爬取梅花网(http://www.meihua.info/a/list/today)的资讯信息,输入给定关键字抓取微信资讯信息. 给定关键字:数字:融合:电 ...
随机推荐
- mysql五-1:单表查询
一 介绍 本节内容: 查询语法 关键字的执行优先级 简单查询 单条件查询:WHERE 分组查询:GROUP BY HAVING 查询排序:ORDER BY 限制查询的记录数:LIMIT 使用聚合函数查 ...
- a标签里文本居中
text-align:center; height: 30px; line-height:30px;
- 利用git把本地项目传到github+将github中已有项目从本地上传更新
利用git把本地项目传到github中 1.打开git bash命令行,进入到要上传的项目中,比如Spring项目,在此目录下执行git init 的命令,会发下在当前目录中多了一个.git的文件夹( ...
- Excel2010数据透视表1
“透视”作为一个动词,意思是旋转.如果将数据看成是一个物体,数据透视表允许旋转数据汇总,从不同角度或观点来看它.数据透视表能够轻松地移动字段,交换字段位置,设置创建项目的特定组. 如果给出一个陌生的物 ...
- 区块链开发(四)Nodejs下载&安装
以太坊框架truffle的安装需要依赖nodejs中的npm命令,本篇博客我们就简单介绍一下node的安装过程.操作系统基于ubuntu 16.04版本. 下载地址 nodejs官网:http://w ...
- k8s资源应用的自由伸缩Scale(up/down)
伸缩(Scale Up/Down)是指在线增加或减少 Pod 的副本数. 1.增加副本 Deployment nginx-deployment初始是两个副本. [root@k8s-master k ...
- (转)Docker 基础 : Dockerfile
全文来自 Docker 基础 : Dockerfile Dockerfile 是一个文本格式的配置文件,用户可以使用 Dockerfile 快速创建自定义的镜像.我们会先介绍 Dockerfile 的 ...
- NYOJ 914 Yougth的最大化【二分/最大化平均值模板/01分数规划】
914-Yougth的最大化 内存限制:64MB 时间限制:1000ms 特判: No 通过数:3 提交数:4 难度:4 题目描述: Yougth现在有n个物品的重量和价值分别是Wi和Vi,你能帮他从 ...
- 让你的apache支持ipv6
如果你使用的linux系统已经获取到了ipv6地址,你就可以让你的apache htpd 等也支持ipv6. 1.检查linux监听的端口,如果有:::port ,而且获取到了ipv6地址,则可以确定 ...
- 29、Django实战第29天:修改密码和头像
修改头像 1.上传头像,我们需要的对它做一个forms验证,编辑users.forms.py ... from .models import UserProfile class UploadImage ...