Python爬虫爬取ECCV Conference Papers(一)
爬取到2020年所有论文标题
代码:
1 import re
2 import requests
3 from bs4 import BeautifulSoup
4 import lxml
5 import traceback
6 import time
7 import json
8 from lxml import etree
9 def get_paper():
10 #https://www.ecva.net/papers/eccv_2020/papers_ECCV/html/267_ECCV_2020_paper.php
11 #https://www.ecva.net/papers/eccv_2020/papers_ECCV/html/283_ECCV_2020_paper.php
12 #https://www.ecva.net/papers/eccv_2020/papers_ECCV/html/343_ECCV_2020_paper.php
13 url='https://www.ecva.net/papers.php'
14 headers = {
15 'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/90.0.4430.212 Safari/537.36'
16 }
17 response=requests.get(url,headers)
18 response.encoding='utf-8'
19 page_text=response.text
20 #输出页面html
21 # print(page_text)
22 soup = BeautifulSoup(page_text,'lxml')
23 all_dt=soup.find_all('dt',class_='ptitle')
24 for dt in all_dt:
25 single_dt=str(dt)
26 single_soup=BeautifulSoup(single_dt,'lxml')
27 title=single_soup.find('a').text
28 print(title)
29 return
30 if (__name__=='__main__'):
31 get_paper()
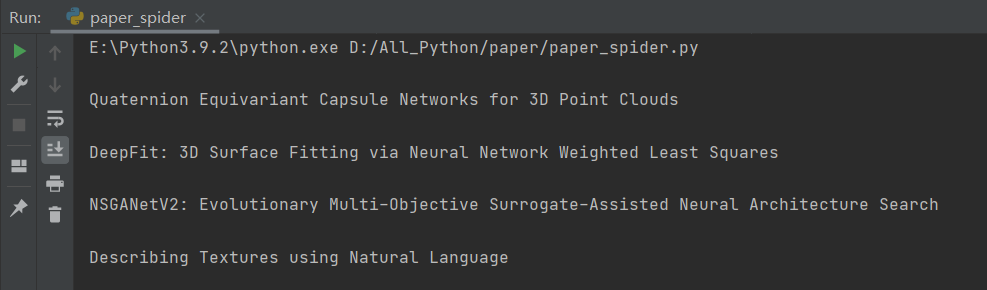

Python爬虫爬取ECCV Conference Papers(一)的更多相关文章
- Python爬虫 - 爬取百度html代码前200行
Python爬虫 - 爬取百度html代码前200行 - 改进版, 增加了对字符串的.strip()处理 源代码如下: # 改进版, 增加了 .strip()方法的使用 # coding=utf-8 ...
- 用Python爬虫爬取广州大学教务系统的成绩(内网访问)
用Python爬虫爬取广州大学教务系统的成绩(内网访问) 在进行爬取前,首先要了解: 1.什么是CSS选择器? 每一条css样式定义由两部分组成,形式如下: [code] 选择器{样式} [/code ...
- 使用Python爬虫爬取网络美女图片
代码地址如下:http://www.demodashi.com/demo/13500.html 准备工作 安装python3.6 略 安装requests库(用于请求静态页面) pip install ...
- Python爬虫|爬取喜马拉雅音频
"GOOD Python爬虫|爬取喜马拉雅音频 喜马拉雅是知名的专业的音频分享平台,用户规模突破4.8亿,汇集了有声小说,有声读物,儿童睡前故事,相声小品等数亿条音频,成为国内发展最快.规模 ...
- python爬虫爬取内容中,-xa0,-u3000的含义
python爬虫爬取内容中,-xa0,-u3000的含义 - CSDN博客 https://blog.csdn.net/aiwuzhi12/article/details/54866310
- Python爬虫爬取全书网小说,程序源码+程序详细分析
Python爬虫爬取全书网小说教程 第一步:打开谷歌浏览器,搜索全书网,然后再点击你想下载的小说,进入图一页面后点击F12选择Network,如果没有内容按F5刷新一下 点击Network之后出现如下 ...
- python爬虫—爬取英文名以及正则表达式的介绍
python爬虫—爬取英文名以及正则表达式的介绍 爬取英文名: 一. 爬虫模块详细设计 (1)整体思路 对于本次爬取英文名数据的爬虫实现,我的思路是先将A-Z所有英文名的连接爬取出来,保存在一个cs ...
- 一个简单的python爬虫,爬取知乎
一个简单的python爬虫,爬取知乎 主要实现 爬取一个收藏夹 里 所有问题答案下的 图片 文字信息暂未收录,可自行实现,比图片更简单 具体代码里有详细注释,请自行阅读 项目源码: # -*- cod ...
- python爬虫-爬取百度图片
python爬虫-爬取百度图片(转) #!/usr/bin/python# coding=utf-8# 作者 :Y0010026# 创建时间 :2018/12/16 16:16# 文件 :spider ...
- python爬虫---爬取王者荣耀全部皮肤图片
代码: import requests json_headers = { "User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win ...
随机推荐
- win32 - GetMenuBarInfo的使用
MSDN文档介绍GetMenuBarInfo是用来检索有关指定菜单栏的信息. 假如有个需求是要找到菜单下拉菜单的矩形大小,该怎么做呢? 最简单的方法就是获取菜单栏的句柄,然后将句柄作为参数传给GetM ...
- lib,dll的位置
在添加第三方库的时候需要注意放置的路径,注意区分x86和x64的文件夹路径以及VS的版本,不要放错了 lib的位置:(需要先将lib放到该路径下,不然会说找不到.lib)C:\Program File ...
- Linux后台进程启停脚本模板
目录 启动脚本 停止脚本 在Linux上启动程序后台运行时,往往需要输入一堆复杂的命令,为了能快速编写一个完善的启动脚本,整理一个通用的启停脚本模板如下. 脚本支持从任意位置执行,不存在路径问题,启动 ...
- SpringBoot 服务接口限流,搞定!
来源:blog.csdn.net/qq_34217386/article/details/122100904 在开发高并发系统时有三把利器用来保护系统:缓存.降级和限流.限流可以认为服务降级的一种 ...
- go最新版本1.15安装配置及编辑器2020.2版本goland
下载 https://golang.google.cn/dl/ 配置 go env #查看是否安装成功 # 终端输入修改镜像地址 $ go env -w GO111MODULE=on $ go env ...
- Sourcetree 如何关联自己的gitlab仓库
现在有些企业自己搭建了gitlab服务器,通过sourcetree从企业服务器拉取代码的时候会提示认证失败.今天搞了大半天才搞懂,给我自己做个笔记. 添加账户 托管服务商 选择 GitLab CE 托 ...
- 【LeetCode贪心#10】划分字母区间(有涉及hash数组的使用)
划分字母区间 力扣题目链接(opens new window) 字符串 S 由小写字母组成.我们要把这个字符串划分为尽可能多的片段,同一字母最多出现在一个片段中.返回一个表示每个字符串片段的长度的列表 ...
- Html飞机大战(十五): 上线
好家伙, 我的飞机大战部署上线了 胖虎的飞机大战 感兴趣的可以去玩一下 (怕有人接受不了这个背景,我还贴心的准备切换背景按钮,然而这并没有什么用) 现在,我们停下脚步,重新审视这个游戏 ...
- CT图像重建
20世纪70年代中期,在医学领域出现了一种神奇装置,名为"计算机辅助 X 射线断层成像仪"(简称CAT或CT),它能够在不损伤病人的情况下,提供人体从头到脚各部位的断层X射线图像. ...
- 自定义ConditionalOnXX注解(二)
一.前言 在之前的文章<自定义ConditionalOnXX注解>中,介绍了Conditional注解的实现原理和实现自定义Conditional注解的基础方法,但是有些场景我们需要用一个 ...