[DQN] What is Deep Reinforcement Learning
已经成为DL中专门的一派,高大上的样子

Intro:
MIT 6.S191 Lecture 6: Deep Reinforcement Learning
Course:
CS 294: Deep Reinforcement Learning

Jan 18: Introduction and course overview (Levine, Finn, Schulman)
Why deep reinforcement learning?
• Deep = can process complex sensory input
…and also compute really complex functions
• Reinforcement learning = can choose complex actions
OpenAI
OpenAI 2016年6月21日宣布了其主要目标,包括制造“通用”机器人和使用自然语言的聊天机器人。
近期发展
Q-learning
V. Mnih, K. Kavukcuoglu, D. Silver, A. Graves, I. Antonoglou, et al. “Playing Atari with Deep Reinforcement Learning”. (2013).
policy gradients
J. Schulman, S. Levine, P. Moritz, M. I. Jordan, and P. Abbeel. “Trust Region Policy Optimization”. (2015);
V. Mnih, A. P. Badia, M. Mirza, A. Graves, T. P. Lillicrap, et al. “Asynchronous methods for deep reinforcement learning”. (2016).
DAGGER
X. Guo, S. Singh, H. Lee, R. L. Lewis, and X. Wang. “Deep learning for real-time Atari game play using offline Monte-Carlo tree search planning”. NIPS. 2014.
guided policy search
S. Levine, C. Finn, T. Darrell, and P. Abbeel. “End-to-end training of deep visuomotor policies”. (2015).
policy gradients
J. Schulman, P. Moritz, S. Levine, M. Jordan, and P. Abbeel. “High-dimensional continuous control using generalized advantage estimation”. (2015).
Finally, AlphaGo 的 四大技术
supervised learning + policy gradients + value functions + Monte-Carlo tree search
Deep Q Network
问题:RE有没有deep,能如何?
回答:Google’s DeepMind published its famous paper Playing Atari with Deep Reinforcement Learning, in which they introduced a new algorithm called Deep Q Network (DQN for short) in 2013. It demonstrated how an AI agent can learn to play games by just observing the screen without any prior information about those games(无信息先验?). The result turned out to be pretty impressive.
This paper opened the era of what is called ‘deep reinforcement learning’, a mix of deep learing and reinforcement learning.
Then, 通过实践了解这个牛牛的网络:Deep Q Learning with Keras and Gym
外加一个有良心的国内博客:用Tensorflow基于Deep Q Learning DQN 玩Flappy Bird (课外阅读)
Cartpole Game 简介
CartPole is one of the simplest environments in OpenAI gym (a game simulator).
当然了,有经费,也可以这么搞个真玩意。

As you can see in the animation from the top, the goal of CartPole is to balance a pole connected with one joint on top of a moving cart.
Instead of pixel information, there are 4 kinds of information given by the state, such as angle of the pole and position of the cart.
An agent can move the cart by performing a series of actions of 0 or 1 to the cart, pushing it left or right.
Gym makes interacting with the game environment really simple.
|
next_state, reward, done, info = env.step(action)
|
学习的输入参数,要具体问题具体分析。
As we discussed above, action can be either 0 or 1.
If we pass those numbers, env, which represents the game environment, will emit the results. done is a boolean value telling whether the game ended or not.
The old state information paired with action and next_state and reward is the information we need for training the agent.
Implementing Simple Nerual Network using Keras
This post is not about deep learning or neural net. So we will consider neural net as just a black box algorithm.
An algorithm that learns on the pairs of example input and output data, detects some kind of patterns, and predicts the output based on an unseen input data.
But we should understand which part is the neural net in the DQN algorithm.
DQN 算法中哪里涉及神经网络

Note that the neural net we are going to use is similar to the diagram above.
We will have one input layer that receives 4 information and 3 hidden layers. 输入层
But we are going to have 2 nodes in the output layer since there are two buttons (0 and 1) for the game.
Keras makes it really simple to implement basic neural network.
The code below creates an empty neural net model.
activation, loss and optimizer are the parameters that define the characteristics of the neural network, but we are not going to discuss it here.
原来如此结合,有机会实现下,目前不着急。
马里奥AI实现 简介
Ref: http://www.cnblogs.com/Leo_wl/p/5852010.html
基于NEAT算法的马里奥AI实现
所谓NEAT算法即通过增强拓扑的进化神经网络(Evolving Neural Networks through Augmenting Topologies),算法不同于我们之前讨论的传统神经网络,
- 它不仅会训练和修改网络的权值,
- 同时会修改网络的拓扑结构,包括新增节点和删除节点等操作。
NEAT算法几个核心的概念是:
- 基因:网络中的连接
- 基因组:基因的集合
- 物种:一批具有相似性基因组的集合
- Fitness:有点类似于增强学习中的reward函数
- generation:进行一组训练的基因组集合,每一代训练结束后,会根据fitness淘汰基因组,并且通过无性繁殖和有性繁殖来新增新的基因组
- 基因变异:发生在新生成基因组的过程中,可能会出现改变网络的权重,增加突出连接或者神经元,也有可能禁用突触或者启用突触
下图我们展示了算法从最一开始简单的神经网络,一直训练到后期的网络

利用NEAT算法实现马里奥通关的基本思想便是:
利用上面NEAT算法的基本观点,从游戏内存中获取实时的游戏数据,判断马里奥是否死亡、计算Fitness值、判断马里奥是否通关等,从而将这些作为神经网络的输入,
最后输出对马里奥的操作,包括上下左右跳跃等操作,如下图:

大多数该算法实现马里奥的智能通关都依赖于模拟器,运用lua语言编写相应脚本,获取游戏数据并操作马里奥。
Ref: NeuroEvolution with MarI/O。
但,更加复杂的游戏,没有确切的状态指标作为输入,便涉及到了CNN图像识别。
这里的CNN与上述的网络不同,一个是识别图像产生状态(input的值)。一个是处理input值。
基于Deep Q-learning的马里奥AI实现
NEAT算法是相对提出较早的算法,在2013年大名鼎鼎的DeepMind提出了一种深度增强学习的算法,该算法主要结合了我们上面讨论的CNN和Q-Learning两种算法。
DeepMind的研究人员将该算法应用在Atari游戏机中的多种小游戏中进行AI通关。
其基本算法核心便是我们之前介绍的CNN和增强学习的Q-Learning,游戏智能通关的基本流程如下图:

do {
- 利用CNN来识别游戏总马里奥的状态,
- 并利用增强学习算法做出动作选择,
- 然后根据新的返回状态和历史状态来计算reward函数从而反馈给Q函数进行迭代,
} while(不断的训练直到游戏能够通关)
研究人员在训练了一个游戏后,将相同的参数用在别的游戏中发现也是适用的,说明该算法具有一定的普遍性。神奇!

而同样的方法,将DRL应用在马里奥上,github上有一个开源的实现方式:aleju/mario-ai
其最终的实现效果图如下:

我们发现在CNN识别过程中,每4帧图像,才会进行一次CNN识别,这是识别速率的问题,图中曲线反映了直接回报函数和简介回报函数。
Q-leanring 基础(应该涉及到Bayes loss function)
Link: 另起一篇
DEEP REINFORCEMENT LEARNING: AN OVERVIEW
From: https://arxiv.org/pdf/1701.07274.pdf
中文简述:http://www.jiqizhixin.com/article/2208
有必要总结下later.
先了解传统的Q-learning,再结合NN深入Deep Q-learning。
主要是个人学习笔记,内容简要,重在学习方法。
Q-Learning
Concise outline I prefer.

An RL agent may include one or more of these components:
Policy: agent’s behaviour function
Value function: how good is each state and/or action
Model: agent’s representation of the environment
Policy: 显示了最佳路径。

Value function: 显示了各个位置的value。

Model: 建模时需考虑的一些问题。
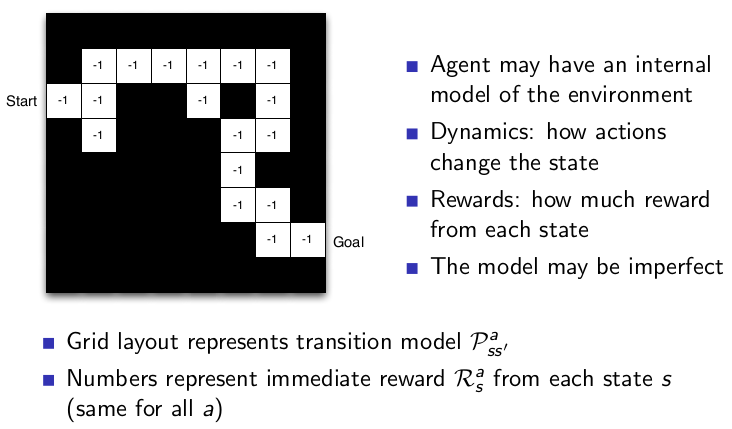
Most Markov reward and decision processes are discounted. Why? 为何设计为discount?
- Mathematically convenient to discount rewards
- Avoids infinite returns in cyclic Markov processes
- Uncertainty about the future may not be fully represented
- If the reward is financial, immediate rewards may earn more interest than delayed rewards
- Animal/human behaviour shows preference for immediate reward
- It is sometimes possible to use undiscounted Markov reward processes (i.e. γ = 1), e.g. if all sequences terminate.

采用discount,在c1状态时,对未来策略的一种评估。

利用Markov迭代的性质,如下。注意:这里像极了HMM的forward-backword algorithm。

利用上述结论,更新一个value function,如下:【这里默认了无衰减】

达到马尔科夫过程的稳态需要方法来收敛,如下可见Q-learning算是比较简单的一种。

A Painless Q-learning Tutorial (一个 Q-learning 算法的简明教程)





[DQN] What is Deep Reinforcement Learning的更多相关文章
- 论文笔记之:Asynchronous Methods for Deep Reinforcement Learning
Asynchronous Methods for Deep Reinforcement Learning ICML 2016 深度强化学习最近被人发现貌似不太稳定,有人提出很多改善的方法,这些方法有很 ...
- Deep Reinforcement Learning 基础知识(DQN方面)
Introduction 深度增强学习Deep Reinforcement Learning是将深度学习与增强学习结合起来从而实现从Perception感知到Action动作的端对端学习的一种全新的算 ...
- (转) Playing FPS games with deep reinforcement learning
Playing FPS games with deep reinforcement learning 博文转自:https://blog.acolyer.org/2016/11/23/playing- ...
- (zhuan) Deep Reinforcement Learning Papers
Deep Reinforcement Learning Papers A list of recent papers regarding deep reinforcement learning. Th ...
- Learning Roadmap of Deep Reinforcement Learning
1. 知乎上关于DQN入门的系列文章 1.1 DQN 从入门到放弃 DQN 从入门到放弃1 DQN与增强学习 DQN 从入门到放弃2 增强学习与MDP DQN 从入门到放弃3 价值函数与Bellman ...
- (转) Deep Reinforcement Learning: Playing a Racing Game
Byte Tank Posts Archive Deep Reinforcement Learning: Playing a Racing Game OCT 6TH, 2016 Agent playi ...
- 论文笔记之:Dueling Network Architectures for Deep Reinforcement Learning
Dueling Network Architectures for Deep Reinforcement Learning ICML 2016 Best Paper 摘要:本文的贡献点主要是在 DQN ...
- (转) Deep Reinforcement Learning: Pong from Pixels
Andrej Karpathy blog About Hacker's guide to Neural Networks Deep Reinforcement Learning: Pong from ...
- 论文笔记之:Deep Reinforcement Learning with Double Q-learning
Deep Reinforcement Learning with Double Q-learning Google DeepMind Abstract 主流的 Q-learning 算法过高的估计在特 ...
随机推荐
- CocosCreator编辑器界面
1,资源管理器[参考来源:官方文档] 资源管理器 里显示了项目资源文件夹(assets)中的所有资源.这里会以树状结构显示文件夹并自动同步在操作系统中对项目资源文件夹内容的修改.您可以将文件从项目外面 ...
- Microsoft.mshtml.dll 添加引用及类型选择错误问题解决办法
在比较早的文章中,提到使用 Microsoft.mshtml.dll 进行模拟浏览器点击的例子. 1.添加引用的问题 一般在开发环境下会在三个地方存有microsoft.mshtml.dll文件.所以 ...
- android: 使用本地广播
前面我们发送和接收的广播全部都是属于系统全局广播,即发出的广播可以被其他任何 的任何应用程序接收到,并且我们也可以接收来自于其他任何应用程序的广播.这样就很容 易会引起安全性的问题,比如说我们发送的一 ...
- js实现的map方法
/** * * 描述:js实现的map方法 * @returns {Map} */ function Map(){ var struct = function(key, value) { this.k ...
- Java时间串获取(格式:yyyyMMddHHmmss)
DateFormat df = new SimpleDateFormat("yyyyMMddHHmmss");Calendar calendar = Calendar.getI ...
- Kafka:ZK+Kafka+Spark Streaming集群环境搭建(三十):使用flatMapGroupsWithState替换agg
flatMapGroupsWithState的出现解决了什么问题: flatMapGroupsWithState的出现在spark structured streaming原因(从spark.2.2. ...
- Swift 弱引用与无主引用
前言 Swift 提供了两种解决循环引用的方法,弱引用和无主引用. 弱引用和无主引用可以使循环中的一个实例引用另一个实例时不使用强引用. 1.弱引用 对生命周期中会变为 nil 的实例采用弱引用,也就 ...
- 10.1.翻译系列:EF 6中的实体映射【EF 6 Code-First系列】
原文链接:https://www.entityframeworktutorial.net/code-first/configure-entity-mappings-using-fluent-api.a ...
- Fluent UDF【8】:编译型UDF
UDF除了可以以解释的方式外,其还可以以编译的方式被Fluent加载.解释型UDF只能使用部分C语言功能,而编译型UDF则可以全面使用C语言的所有功能. 1 编译型UDF介绍 编译型UDF的构建方式与 ...
- lua -- 所有UI组件的基类
-- 组件行为基础 local Behavior = class("Behavior"); function Behavior:ctor(name) self.owner = ni ...