python 3 爬取某小说网站小说,注释详细
目标:每一个小说保存成一个txt文件
思路:获取每个小说地址(图一),进入后获取每章节地址(图二),然后进入获取该章节内容(图三)保存文件中。循环



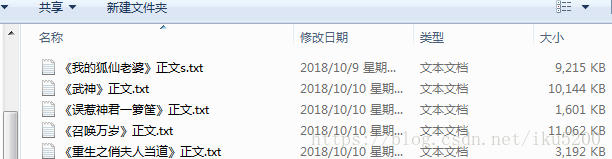
效果图:
每一行都有注释,不多解释了
import requests
from bs4 import BeautifulSoup
import os
if __name__ == '__main__':
# 要下载的网页
url = 'https://www.biqubao.com/quanben/'
# 网站根网址
root_url = 'https://www.biqubao.com'
# 保存本地路径
path = 'F:\\python\\txt'
# 解析网址
req = requests.get(url)
# 设置编码,浏览器查看网站编码:F12,控制开输入document.characterSet回车即可查看
req.encoding = 'gbk'
# 获取网页所有内容
soup = BeautifulSoup(req.text, 'html.parser')
# 查找网页中div的id为main的标签
list_tag = soup.div(id="main")
# 查看div内所有里标签
li = list_tag[0](['li'])
# 删除第一个没用的标签
del li[0]
# 循环遍历
for i in li:
# 获取到a标签间的内容---小说类型
txt_type = i.a.string
# 获取a标签的href地址值---小说网址
short_url = (i(['a'])[1].get('href'))
# 获取第三个span标签的值---作者
author = i(['span'])[3].string
# 获取网页设置网页编码
req = requests.get(root_url + short_url)
req.encoding = 'gbk'
# 解析网页
soup = BeautifulSoup(req.text, "html.parser")
list_tag = soup.div(id="list")
# 获取小说名
name = list_tag[0].dl.dt.string
print("类型:{} 短址:{} 作者:{} 小说名:{}".format(txt_type, short_url, author, name))
# 创建同名文件夹
# paths = path + '\\' + name
if not os.path.exists(path):
# 获取当前目录并组合新目录
# os.path.join(path, name)
os.mkdir(path)
# 循环所有的dd标签
for dd_tag in list_tag[0].dl.find_all('dd'):
# 章节名
zjName = dd_tag.string
# 章节地址
zjUrl = root_url + dd_tag.a.get('href')
# 访问网址爬取章节内容
req2 = requests.get(zjUrl)
req2.encoding = 'gbk'
zj_soup = BeautifulSoup(req2.text, "html.parser")
content_tag = zj_soup.div.find(id="content")
# 把空格内容替换成换行
text = str(content_tag.text.replace('\xa0', '\n'))
text.replace('\ufffd', '\n')
# 写入文件操作'a'追加
with open(path + "\\" + name + ".txt", 'a') as f:
f.write('\n' + '\n' + zjName)
f.write(text)
print("{}------->写入完毕".format(zjName))python 3 爬取某小说网站小说,注释详细的更多相关文章
- Python轻松爬取Rosimm写真网站全部图片
RosimmImage 爬取Rosimm写真网站图片 有图有真相 def main_start(url): """ 爬虫入口,主要爬取操作 ""&qu ...
- Python爬虫爬取美剧网站
一直有爱看美剧的习惯,一方面锻炼一下英语听力,一方面打发一下时间.之前是能在视频网站上面在线看的,可是自从广电总局的限制令之后,进口的美剧英剧等貌似就不在像以前一样同步更新了.但是,作为一个宅diao ...
- Python——Scrapy爬取链家网站所有房源信息
用scrapy爬取链家全国以上房源分类的信息: 路径: items.py # -*- coding: utf-8 -*- # Define here the models for your scrap ...
- python爬虫爬取ip记录网站信息并存入数据库
import requests import re import pymysql #10页 仔细观察路由 db = pymysql.connect("localhost",&quo ...
- Python爬虫爬取全书网小说,程序源码+程序详细分析
Python爬虫爬取全书网小说教程 第一步:打开谷歌浏览器,搜索全书网,然后再点击你想下载的小说,进入图一页面后点击F12选择Network,如果没有内容按F5刷新一下 点击Network之后出现如下 ...
- Jsoup-基于Java实现网络爬虫-爬取笔趣阁小说
注意!仅供学习交流使用,请勿用在歪门邪道的地方!技术只是工具!关键在于用途! 今天接触了一款有意思的框架,作用是网络爬虫,他可以像操作JS一样对网页内容进行提取 初体验Jsoup <!-- Ma ...
- bs4爬取笔趣阁小说
参考链接:https://www.cnblogs.com/wt714/p/11963497.html 模块:requests,bs4,queue,sys,time 步骤:给出URL--> 访问U ...
- Python 爬取所有51VOA网站的Learn a words文本及mp3音频
Python 爬取所有51VOA网站的Learn a words文本及mp3音频 #!/usr/bin/env python # -*- coding: utf-8 -*- #Python 爬取所有5 ...
- Python开发爬虫之BeautifulSoup解析网页篇:爬取安居客网站上北京二手房数据
目标:爬取安居客网站上前10页北京二手房的数据,包括二手房源的名称.价格.几室几厅.大小.建造年份.联系人.地址.标签等. 网址为:https://beijing.anjuke.com/sale/ B ...
- python爬虫学习之使用BeautifulSoup库爬取开奖网站信息-模块化
实例需求:运用python语言爬取http://kaijiang.zhcw.com/zhcw/html/ssq/list_1.html这个开奖网站所有的信息,并且保存为txt文件和excel文件. 实 ...
随机推荐
- Token防止表单重复提交和CSRF攻击
Token,可以翻译成标记!最大的特点就是随机性,不可预测,一般黑客或软件无法猜测出来. Token一般用在两个地方: 1: 防止表单重复提交 2: anti csrf攻击(Cross-site re ...
- Hadoop记录-退役
一.datanode添加新节点 1.在dfs.include文件中包含新节点名称,该文件在名称节点的本地目录下 [白名单] [/app/hadoop/etc/hadoop/dfs.include] 2 ...
- 从Socket入门到BIO,PIO,NIO,multiplexing,AIO(未完待续)
Socket入门 最简单的Server端读取Client端内容的demo public class Server { public static void main(String [] args) t ...
- ES6 数组遍历方法的实战用法总结(forEach,every,some,map,filter,reduce,reduceRight,indexOf,lastIndexOf)
目录 forEach every some map filter reduce && reduceRight indexOf lastIndexOf 前言 ES6原生语法中提供了非常多 ...
- [物理学与PDEs]第5章习题2 Jacobian 的物质导数
验证 (3. 6) 式, 即证明 $$\bex \cfrac{\rd J}{\rd t}=J\Div_y {\bf v}. \eex$$ 证明: $$\beex \bea \cfrac{\rd J}{ ...
- 给一个Unix域套接字bind一个路径名
#include <stdio.h> #include <stdlib.h> #include <unistd.h> #include <strings.h& ...
- mysql 分库分表 ~ 柔性事务
一 定义 TCC方案是可能是目前最火的一种柔性事务方案二 具体 内容 TCC=try(预设)-confrim(应用确认)-canal(回滚取消)三 目的 解决跨服务调用场景下的分布式事务问题,避免使用 ...
- jenkins中slave节点连接的两种常用方式
我们在使用jenkins的时候,一般来说肯定是有slave节点的,本来网上也有好多关于jenkins节点配置的教程,我也就不写了.简单说明一下:任务一般是在slave上面运行的.当然不是讲master ...
- linux redis 主从复制
在从服务的redis.conf 添加 slaveof 主服务器 端口 查看reids进程和端口,都是存在的.只是ip地址是127.0.0.1而不是0.0.0.0,只是本机能使用; 查找redis的配置 ...
- 详解HTTPS、TLS、SSL
HTTPS.TLS.SSL HTTP也称作HTTP over TLS.TLS的前身是SSL,TLS 1.0通常被标示为SSL 3.1,TLS 1.1为SSL 3.2,TLS 1.2为SSL 3.3.下 ...