集成学习-Adaboost
Adaboost 中文名叫自适应提升算法,是一种boosting算法。
boosting算法的基本思想
对于一个复杂任务来说,单个专家的决策过于片面,需要集合多个专家的决策得到最终的决策,通俗讲就是三个臭皮匠顶个诸葛亮。
对于给定的数据集,学习到一个较弱的分类器比学习到一个强分类器容易的多,boosting就是从弱学习器出发,反复学习,得到多个弱分类器,最后将这些弱分类器组合成强分类器。
boosting算法需要解决两个问题
每一轮如何改变训练样本的权重
如何将弱分类器组合成强分类器
adaboost是这样做的
1. 提高那些被前一轮弱分类器错误分类的样本的权值,而降低那些被正确分类样本的权值.,这样下个分类器就能专注于那些不好识别的样本,针对性的建立分类器。
2. 对于若分类器的组合,adaboost采取加权多数表决的方式,即加大分类错误率较小的弱分类器的权值,使其在表决中起较大作用,减小分类错误率较高的弱分类器的权值,使其在表决中起较小作用,
这可以理解为有些专家比较权威,他的意见要多采纳,有些只是不知名的专家,可以少采纳。
adaboost其实是一个加法模型,损失函数是指数损失函数,学习算法为前向分步算法的二分类学习方法。(其他学习算法如梯度下降)
加法模型
xgboost中其实也是加法模型,应该说boosting算法都是加法模型,而且还有很多算法也是加法模型,那什么是加法模型?
顾名思义,一个模型是由多个模型相加而得

那最终问题转化为基于加法模型的损失最小化,即

通常这是一个十分复杂的优化问题,想要一步到位非常困难,如用梯度下降,所以就有了前向分步算法。
前向分步算法
前向分步算法是一种优化算法,可以解决上面加法模型的问题。
大致思路是,从前向后,每一步学习一个基分类器,使得整体损失函数更小一点,从而逐步逼近全局最小值。
算法流程

解释一点: 新的学习器fm是在上个学习器fm-1的基础上学习的,也就是说在学习fm时fm-1已经确定,所以求L(y, fm)的极小值就是求b(x;r)的极小值,即单个学习器的最小值。
实际上这和梯度下降的思路十分相似,每次减小一点,逼近一点,而且形式也一样 fm=fm-1+βb
adaboost算法流程

误差解释
1. 误差计算时除以了Σw,因为每轮迭代时,Σw是一个固定值,而且后面会说明其实它等于1,所以不用除这个。
2. 误差计算时,分类正确为0,其权重被忽略,分类错误为1,其权重累加,所以是I(G!=y)
分类器权重解释

权重更新解释

组合分类器解释
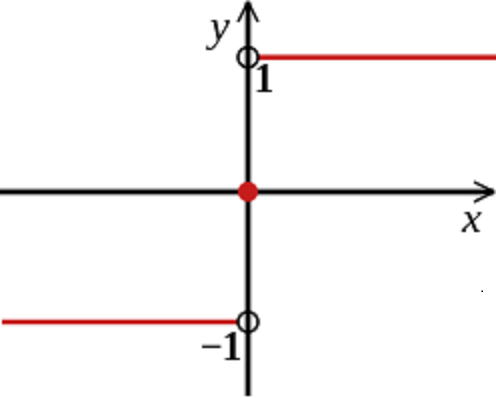
sign函数只能取1和-1,故adaboost为二分类。
当然可以通过修改实现多分类。
adaboost有很多种算法,但都大同小异,而且adaboost可以做回归,思路也是大同小异,具体请百度
adaboost进阶
正则化
adaboost每个学习器都是弱学习器,为什么还要正则化?其实不是正则化基学习器
fm=fm-1+αb(x,r),这是加法模型,α为基学习器的系数,可以理解为权重,
正则化是对加法模型增加一个学习率v,即fm=fm-1+vαb(x,r),这种方法适合于很多集成学习。
基分类器随机化
像随机森林一样,随机选特征,随机选样本
总结
理论上来讲,adaboost的弱学习器可以是任何模型,但用的最多的是决策树和神经网络,决策树是cart树
优点:精度高,不容易过拟合
缺点:对异常值敏感,因为异常值可能获得较大权重,最终影响整个模型
参考资料:
https://www.cnblogs.com/liuwu265/p/4693113.html?ptvd
https://zhuanlan.zhihu.com/p/59751960
https://zhuanlan.zhihu.com/p/42915999
https://blog.csdn.net/hahaha_2017/article/details/79852363
https://blog.csdn.net/guyuealian/article/details/70995333 原理-实例-代码(简明易懂)
集成学习-Adaboost的更多相关文章
- 吴裕雄 python 机器学习——集成学习AdaBoost算法回归模型
import numpy as np import matplotlib.pyplot as plt from sklearn import datasets,ensemble from sklear ...
- 吴裕雄 python 机器学习——集成学习AdaBoost算法分类模型
import numpy as np import matplotlib.pyplot as plt from sklearn import datasets,ensemble from sklear ...
- 机器学习算法总结(三)——集成学习(Adaboost、RandomForest)
1.集成学习概述 集成学习算法可以说是现在最火爆的机器学习算法,参加过Kaggle比赛的同学应该都领略过集成算法的强大.集成算法本身不是一个单独的机器学习算法,而是通过将基于其他的机器学习算法构建多个 ...
- 集成学习AdaBoost算法——学习笔记
集成学习 个体学习器1 个体学习器2 个体学习器3 ——> 结合模块 ——>输出(更好的) ... 个体学习器n 通常,类似求平均值,比最差的能好一些,但是会比最好的差. 集成可能提 ...
- 集成学习-Adaboost 进阶
adaboost 的思想很简单,算法流程也很简单,但它背后有完整的理论支撑,也有很多扩展. 权重更新 在算法描述中,权重如是更新 其中 wm,i 是m轮样本i的权重,αm是错误率,Øm是第m个基学习器 ...
- 集成学习——Adaboost(手推公式)
- 集成学习之Adaboost算法原理小结
在集成学习原理小结中,我们讲到了集成学习按照个体学习器之间是否存在依赖关系可以分为两类,第一个是个体学习器之间存在强依赖关系,另一类是个体学习器之间不存在强依赖关系.前者的代表算法就是是boostin ...
- 集成学习原理:Adaboost
集成学习通过从大量的特征中挑出最优的特征,并将其转化为对应的弱分类器进行分类使用,从而达到对目标进行分类的目的. 核心思想 它是一种迭代算法,其核心思想是针对同一个训练集训练不同的分类器(弱分类器), ...
- 集成学习之Boosting —— AdaBoost原理
集成学习大致可分为两大类:Bagging和Boosting.Bagging一般使用强学习器,其个体学习器之间不存在强依赖关系,容易并行.Boosting则使用弱分类器,其个体学习器之间存在强依赖关系, ...
随机推荐
- 小程序之 微信小程序下拉上方出现空白
往下拉页面后上方出现空白区域 用户需要手动划上去才能消失 方法一:"enablePullDownRefresh":false //这个在page.json中配置 整个页面都不能滑 ...
- requests库爬取猫眼电影“最受期待榜”榜单 --网络爬虫
目标站点:https://maoyan.com/board/6 # coding:utf8 import requests, re, json from requests.exceptions imp ...
- 理解去中心化 稳定币 DAI
本文转载于深入浅出区块链, 原文链接 随着摩根大通推出JPM Coin 稳定币,可以预见稳定币将成为区块链落地的一大助推器. 坦白来讲,对于一个程序员的我来讲(不懂一点专业经济和金融),理解DAI的机 ...
- SpringBoot之AOP
AOP:面向切面编程,相当于OOP面向对象编程. Spring的AOP的存在目的是为了解耦,AOP可以让一组类共享相同的行为. Spring支持AspectJ的注解切面编程: (1)使用@Aspect ...
- 使用Nome监控服务器各项指标
使用Nome监控服务器各项指标 关于Nome的使用: 1)如何将nome压缩文件上传到服务器是,首选需要将压缩包下载到本地 a.创建文件夹Nome:mk ...
- JAVA写接口傻瓜(%)教程(五)
今天主要说一下在URL 中使用?传值的问题.在显式的使用get方法获取特点数据时,一般会通过?传递参数值,sevlert根据参数在数据库中对应的查找内容.所以,SQL语句需要拼接,要加上后面的参数.参 ...
- win10释放的wifi热点手机连不上
直入正题吧…… 在win10的搜索框里输入ser,找到“windows服务”选项,点击进入,如下图 找到下图所示的两个服务,然后,右键,属性,启动类型改为自动,然后点确定,确定完以后,再右键,点启动, ...
- vue-计算属性和侦听器
1.计算属性 模板内的表达式非常便利,但是设计它们的初衷是用于简单运算的.在模板中放入太多的逻辑会让模板过重且难以维护.例如: <div id="example"> { ...
- Django 之 cookie和session
一. Cookie 1.Cookie的由来 因为HTTP协议是无状态的,无状态的意思就是每次请求都是独立的,它的执行情况和结果与前面的请求和之后的请求都无直接关系,也不会受前后请求响应情况直接影响.简 ...
- c# Process cmd 执行完回调 Proc_OutputDataReceived mysql mysqldump mysql source备份还原数据
c# Process 执行完回调 Proc_OutputDataReceived mysql mysqldump mysql source备份还原数据 直接贴代码 前提:mysql5.7 vs2017 ...