Python之爬虫(十九) Scrapy框架中Download Middleware用法
这篇文章中写了常用的下载中间件的用法和例子。
Downloader Middleware处理的过程主要在调度器发送requests请求的时候以及网页将response结果返回给spiders的时候,所以从这里我们可以知道下载中间件是介于Scrapy的request/response处理的钩子,用于修改Scrapy request和response。
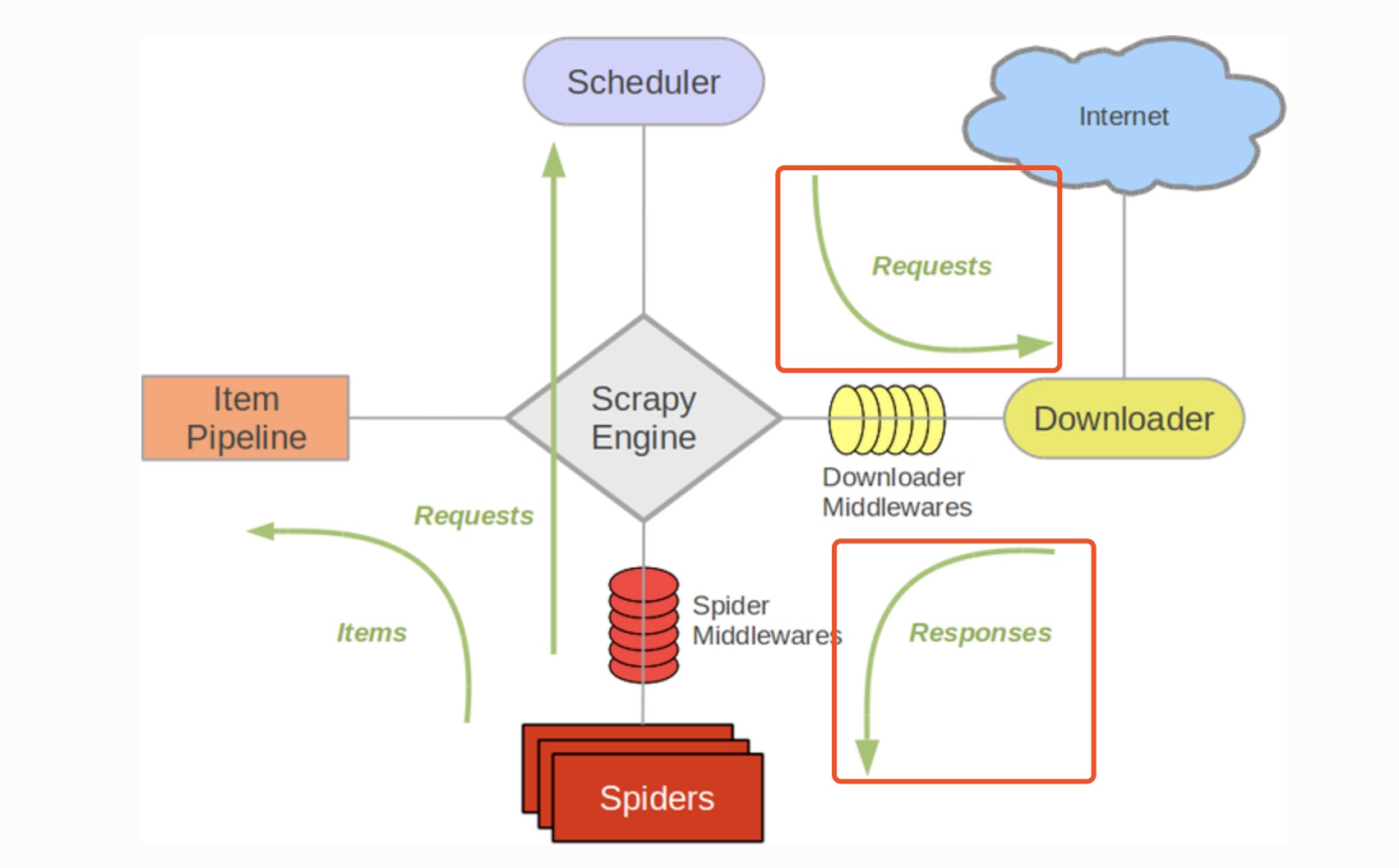
编写自己的下载器中间件
编写下载器中间件,需要定义以下一个或者多个方法的python类
为了演示这里的中间件的使用方法,这里创建一个项目作为学习,这里的项目是关于爬去httpbin.org这个网站
scrapy startproject httpbintest
cd httpbintest
scrapy genspider example example.com
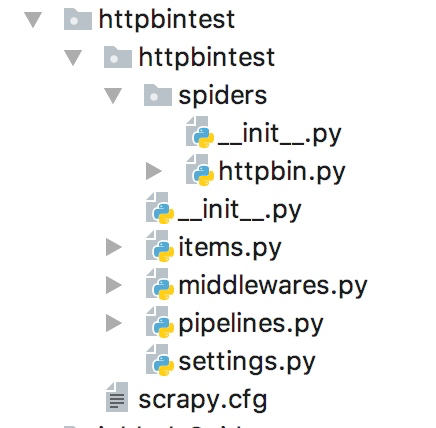
创建好后的目录结构如下:
这里我们先写一个简单的代理中间件来实现ip的伪装
创建好爬虫之后我们讲httpbin.py中的parse方法改成:
def parse(self, response):
print(response.text)
然后通过命令行启动爬虫:scrapy crawl httpbin
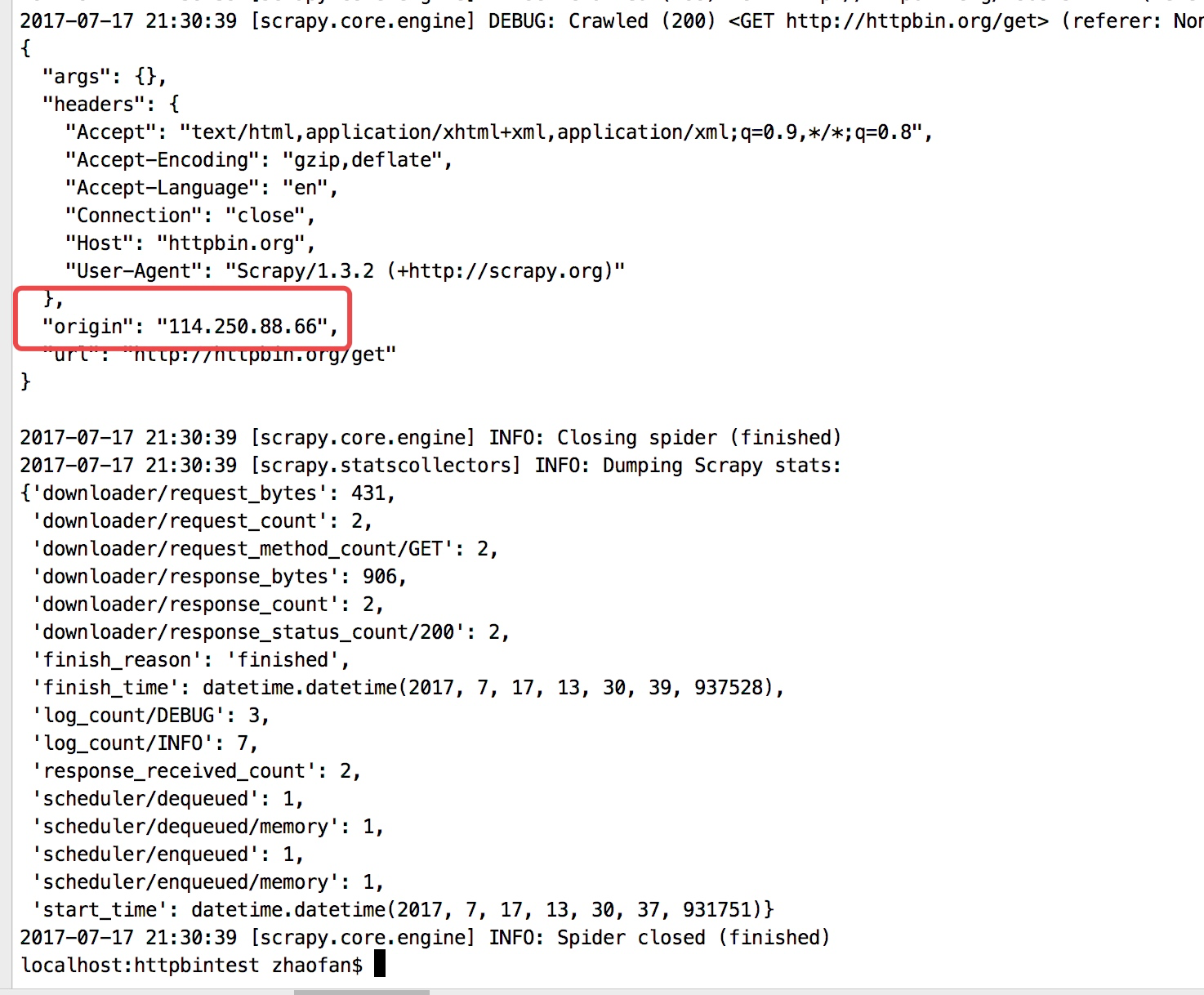
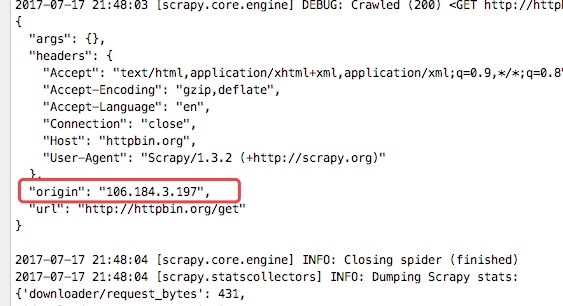
在最下面我们可以看到"origin": "114.250.88.66"
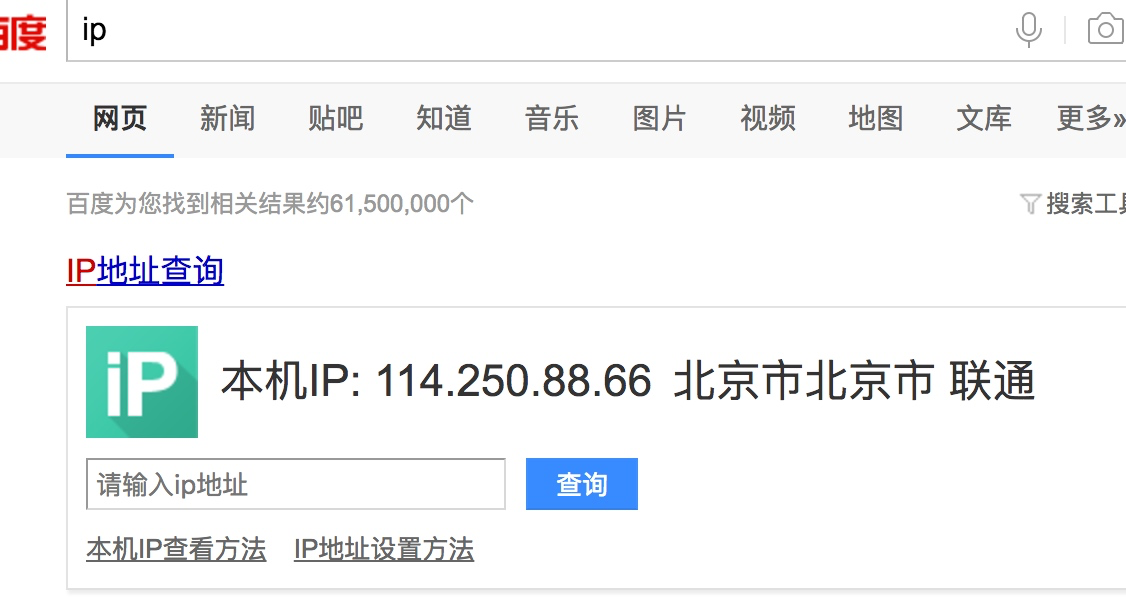
我们在查看自己的ip:
而我们要做就是通过代理中间件来实现ip的伪装,在middleares.py中写如下的中间件类:
class ProxyMiddleare(object):
logger = logging.getLogger(__name__)
def process_request(self,request, spider):
self.logger.debug("Using Proxy")
request.meta['proxy'] = 'http://127.0.0.1:9743'
return None
这里因为我本地有一个代理FQ地址为:http://127.0.0.1:9743
所以直接设置为代理用,代理的地址为日本的ip
然后在settings.py配置文件中开启下载中间件的功能,默认是关闭的
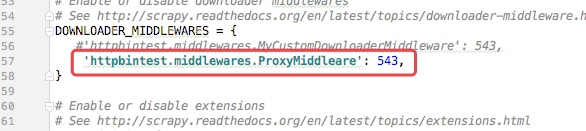
然后我们再次启动爬虫:scrapy crawl httpbin
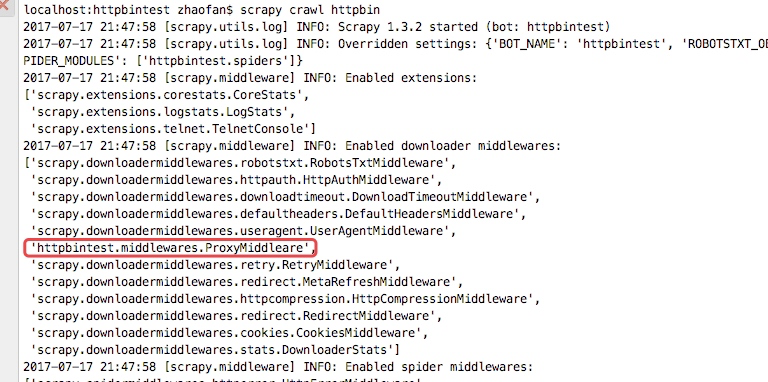
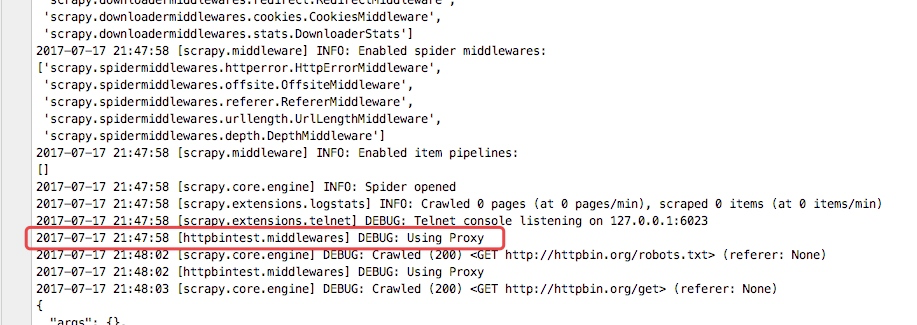
从下图的输入日志中我们可以看书我们定义的中间件已经启动,并且输入了我们打印的日志信息,并且我们查看origin的ip地址也已经成了日本的ip地址,这样我们的代理中间件成功了
详细说明
class Scrapy.downloadermiddleares.DownloaderMiddleware
process_request(request,spider)
当每个request通过下载中间件时,该方法被调用,这里有一个要求,该方法必须返回以下三种中的任意一种:None,返回一个Response对象,返回一个Request对象或raise IgnoreRequest。三种返回值的作用是不同的。
None:Scrapy将继续处理该request,执行其他的中间件的相应方法,直到合适的下载器处理函数(download handler)被调用,该request被执行(其response被下载)。
Response对象:Scrapy将不会调用任何其他的process_request()或process_exception() 方法,或相应地下载函数;其将返回该response。 已安装的中间件的 process_response() 方法则会在每个response返回时被调用。
Request对象:Scrapy则停止调用 process_request方法并重新调度返回的request。当新返回的request被执行后, 相应地中间件链将会根据下载的response被调用。
raise一个IgnoreRequest异常:则安装的下载中间件的 process_exception() 方法会被调用。如果没有任何一个方法处理该异常, 则request的errback(Request.errback)方法会被调用。如果没有代码处理抛出的异常, 则该异常被忽略且不记录。
process_response(request, response, spider)
process_response的返回值也是有三种:response对象,request对象,或者raise一个IgnoreRequest异常
如果其返回一个Response(可以与传入的response相同,也可以是全新的对象), 该response会被在链中的其他中间件的 process_response() 方法处理。
如果其返回一个 Request 对象,则中间件链停止, 返回的request会被重新调度下载。处理类似于 process_request() 返回request所做的那样。
如果其抛出一个 IgnoreRequest 异常,则调用request的errback(Request.errback)。 如果没有代码处理抛出的异常,则该异常被忽略且不记录(不同于其他异常那样)。
这里我们写一个简单的例子还是上面的项目,我们在中间件中继续添加如下代码:
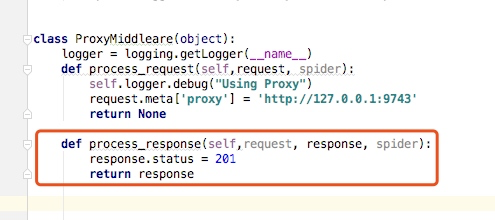
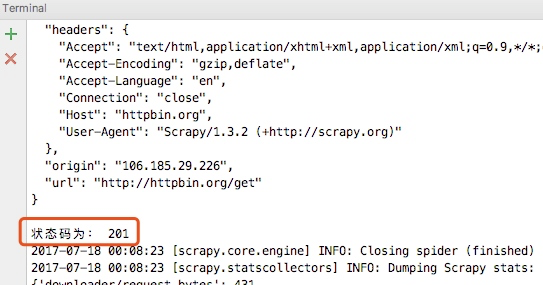
然后在spider中打印状态码:

这样当我们重新运行爬虫的时候就可以看到如下内容
process_exception(request, exception, spider)
当下载处理器(download handler)或 process_request() (下载中间件)抛出异常(包括 IgnoreRequest 异常)时,Scrapy调用 process_exception()。
process_exception() 也是返回三者中的一个: 返回 None 、 一个 Response 对象、或者一个 Request 对象。
如果其返回 None ,Scrapy将会继续处理该异常,接着调用已安装的其他中间件的 process_exception() 方法,直到所有中间件都被调用完毕,则调用默认的异常处理。
如果其返回一个 Response 对象,则已安装的中间件链的 process_response() 方法被调用。Scrapy将不会调用任何其他中间件的 process_exception() 方法。
如果其返回一个 Request 对象, 则返回的request将会被重新调用下载。这将停止中间件的 process_exception() 方法执行,就如返回一个response的那样。 这个是非常有用的,就相当于如果我们失败了可以在这里进行一次失败的重试,例如当我们访问一个网站出现因为频繁爬取被封ip就可以在这里设置增加代理继续访问,我们通过下面一个例子演示
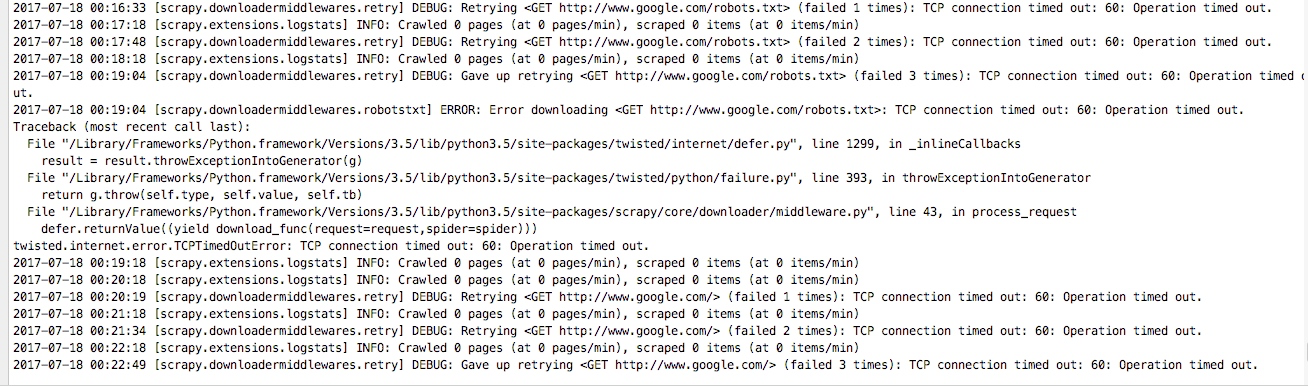
scrapy genspider google www.google.com 这里我们创建一个谷歌的爬虫,
然后启动scrapy crawl google,可以看到如下情况:
这里我们就写一个中间件,当访问失败的时候增加代理
首先我们把google.py代码进行更改,这样是白超时时间设置为10秒要不然等待太久,这个就是我们将spider里的时候的讲过的make_requests_from_url,这里我们把这个方法重写,并将等待超时时间设置为10s
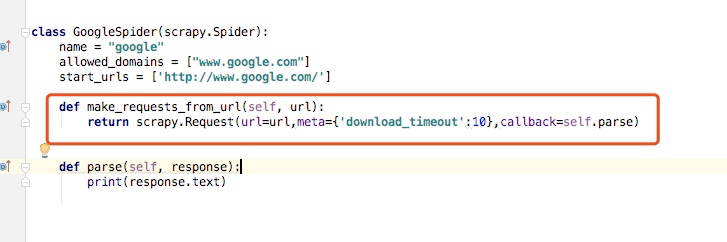
这样我重新启动爬虫:scrapy crawl google,可以看到如下:
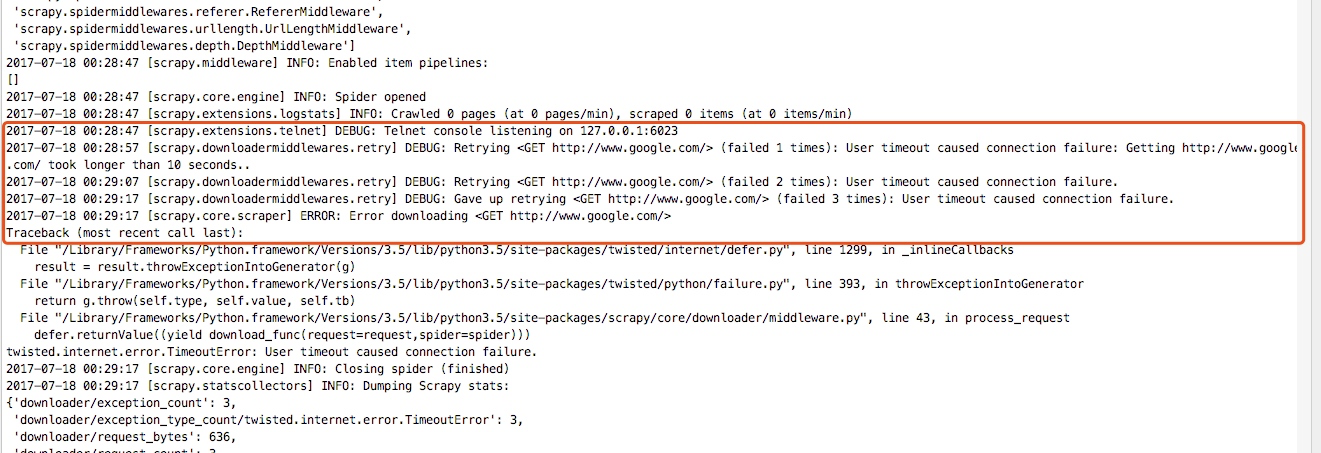
这里如果我们不想让重试,可以把重试中间件关掉:
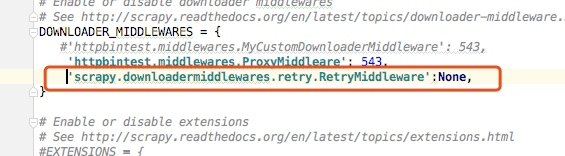
这样设置之后我们就把失败重试的中间件给关闭了,设置为None就表示关闭这个中间件,重新启动爬虫我们也可以看出没有进行重试直接报错了
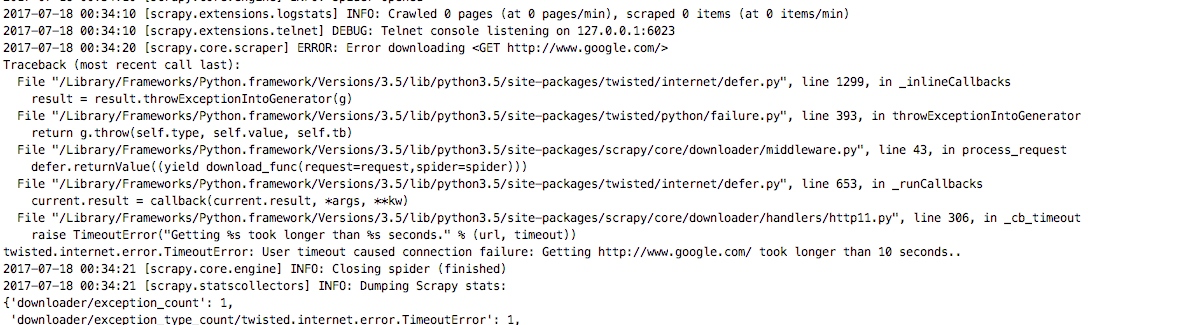
我们将代理中间件的代理改成如下,表示遇到异常的时候给请求加上代理,并返回request,这个样就会重新请求谷歌
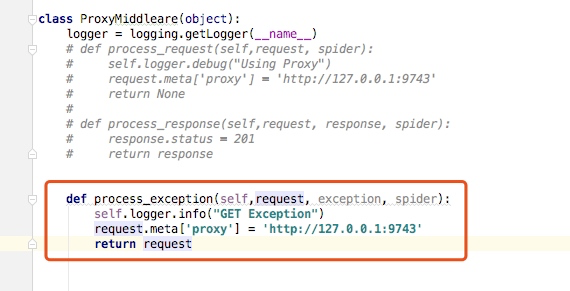
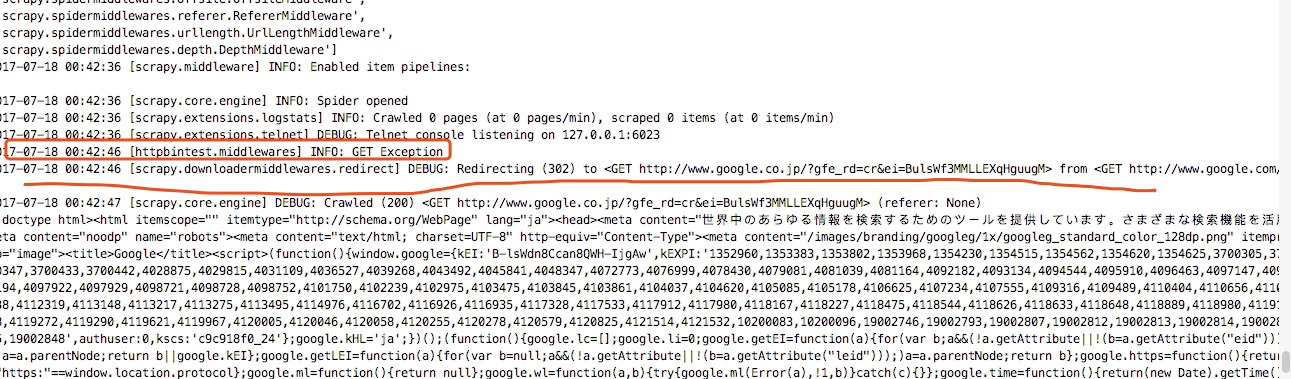
重新启动谷歌爬虫,我们可以看到,我们第一次返回我们打印的日志信息GET Exception,然后加上代理后成功访问了谷歌,这里我的代理是日本的代理节点,所以访问到的是日本的谷歌站
Python之爬虫(十九) Scrapy框架中Download Middleware用法的更多相关文章
- scrapy框架中Download Middleware用法
scrapy框架中Download Middleware用法 Downloader Middleware处理的过程主要在调度器发送requests请求的时候以及网页将response结果返回给sp ...
- Python爬虫从入门到放弃(十七)之 Scrapy框架中Download Middleware用法
这篇文章中写了常用的下载中间件的用法和例子.Downloader Middleware处理的过程主要在调度器发送requests请求的时候以及网页将response结果返回给spiders的时候,所以 ...
- Python爬虫从入门到放弃 之 Scrapy框架中Download Middleware用法
这篇文章中写了常用的下载中间件的用法和例子.Downloader Middleware处理的过程主要在调度器发送requests请求的时候以及网页将response结果返回给spiders的时候,所以 ...
- 7-----Scrapy框架中Download Middleware用法
这篇文章中写了常用的下载中间件的用法和例子.Downloader Middleware处理的过程主要在调度器发送 requests请求的时候以及网页将 response结果返回给 spiders的时候 ...
- Scrapy框架中选择器的用法【转】
Python爬虫从入门到放弃(十四)之 Scrapy框架中选择器的用法 请给作者点赞 --> 原文链接 Scrapy提取数据有自己的一套机制,被称作选择器(selectors),通过特定的Xpa ...
- scrapy框架中Item Pipeline用法
scrapy框架中item pipeline用法 当Item 在Spider中被收集之后,就会被传递到Item Pipeline中进行处理 每个item pipeline组件是实现了简单的方法的pyt ...
- scrapy框架中选择器的用法
scrapy框架中选择器的用法 Scrapy提取数据有自己的一套机制,被称作选择器(selectors),通过特定的Xpath或者CSS表达式来选择HTML文件的某个部分Xpath是专门在XML文件中 ...
- PYTHON网络爬虫与信息提取[scrapy框架应用](单元十、十一)
scrapy 常用命令 startproject 创建一个新的工程 scrapy startproject <name>[dir] genspider 创建一个爬虫 ...
- Python爬虫从入门到放弃(十六)之 Scrapy框架中Item Pipeline用法
当Item 在Spider中被收集之后,就会被传递到Item Pipeline中进行处理 每个item pipeline组件是实现了简单的方法的python类,负责接收到item并通过它执行一些行为, ...
随机推荐
- python自如爬虫
如果你想入门数据分析,但是苦于没有数据,那就看下文如何用 10 行代码写一个最简单的自如房源爬虫 首先我们通过分析看到自如手机版有个 url 如下:http://m.ziroom.com/list/a ...
- Windows程序设计(2) - API-02 文件系统
一.磁盘分区的基本概念 1.磁盘分区(Patitions): 分区就是物理存储设备分割成多个不同的逻辑上的存储设备.分区从实质上说就是对硬盘的一种格式化.当我们创建分区时,就已经设置好了硬盘的各项物理 ...
- 8.实战交付一套dubbo微服务到k8s集群(1)之Zookeeper部署
1.基础架构 主机名 角色 ip HDSS7-11.host.com K8S代理节点1,zk1 10.4.7.11 HDSS7-12.host.com K8S代理节点2,zk2 10.4.7.12 H ...
- Python三大器之迭代器
Python三大器之迭代器 迭代器协议 迭代器协议规定:对象内部必须提供一个__next__方法,对其执行该方法要么返回迭代器中的下一项(可以暂时理解为下一个元素),要么就引起一个Stopiterat ...
- caffe的python接口学习(2)生成solver文件
caffe在训练的时候,需要一些参数设置,我们一般将这些参数设置在一个叫solver.prototxt的文件里面 有一些参数需要计算的,也不是乱设置. 假设我们有50000个训练样本,batch_si ...
- Python实用笔记 (10)高级特性——生成器
通过列表生成式,我们可以直接创建一个列表.但是,受到内存限制,列表容量肯定是有限的.而且,创建一个包含100万个元素的列表,不仅占用很大的存储空间,如果我们仅仅需要访问前面几个元素,那后面绝大多数元素 ...
- DOM-BOM-EVENT(2)
2.获取DOM元素的方法 2.1.getElement系列 documentElementById 通过id获取元素 <div id="box"></div> ...
- php抽奖功能
在项目开发中经常会遇到花钱抽奖类型的需求.但是老板总是担心用户用小钱抽到大奖.这样会导致项目亏损.下边这段代码可以有效制止抽奖项目亏钱. 个人奖池: 语言:thinkphp redis mysql 表 ...
- Python之浅谈函数
目录 文件的高级应用 文件修改的两种方式 第一种 第二种 函数的定义 函数的参数 函数的返回值 文件的高级应用 r+即可读又可写,并且是在后面追加 w+清空文件的功能是w提供的 a+a有追加的功能,a ...
- 05 . k8s实战之部署PHP/JAVA网站
传统部署和k8s部署区别 通常使用传统的部署的时候,我们一个web项目,网站的搭建,往往使用的如下的一种整体架构,可能有的公司在某一环节使用的东西是不一样,但是大体的框架流程是都是差不多的 1111 ...