小白学 Python 爬虫(2):前置准备(一)基本类库的安装

人生苦短,我用 Python
前文传送门:
本篇内容较长,各位同学可以先收藏后再看~~
在开始讲爬虫之前,还是先把环境搞搞好,工欲善其事必先利其器嘛~~~
本篇文章主要介绍 Python 爬虫所使用到的请求库和解析库,请求库用来请求目标内容,解析库用来解析请求回来的内容。
开发环境
首先介绍小编本地的开发环境:
- Python3.7.4
- win10
差不多就这些,最基础的环境,其他环境需要我们一个一个安装,现在开始。
请求库
虽然 Python 为我们内置了 HTTP 请求库 urllib ,使用姿势并不是很优雅,但是很多第三方的提供的 HTTP 库确实更加的简洁优雅,我们下面开始。
Requests
Requests 类库是一个第三方提供的用于发送 HTTP 同步请求的类库,相比较 Python 自带的 urllib 类库更加的方便和简洁。
Python 为我们提供了包管理工具 pip ,使用 pip 安装将会非常的方便,安装命令如下:
pip install requests
验证:
C:\Users\inwsy>python
Python 3.7.4 (tags/v3.7.4:e09359112e, Jul 8 2019, 20:34:20) [MSC v.1916 64 bit (AMD64)] on win32
Type "help", "copyright", "credits" or "license" for more information.
>>> import requests
首先在 CMD 命令行中输入 python ,进入 python 的命令行模式,然后输入 import requests 如果没有任何错误提示,说明我们已经成功安装 Requests 类库。
Selenium
Selenium 现在更多的是用来做自动化测试工具,相关的书籍也不少,同时,我们也可以使用它来做爬虫工具,毕竟是自动化测试么,利用它我们可以让浏览器执行我们想要的动作,比如点击某个按钮、滚动滑轮之类的操作,这对我们模拟真实用户操作是非常方便的。
安装命令如下:
pip install selenium
验证:
C:\Users\inwsy>python
Python 3.7.4 (tags/v3.7.4:e09359112e, Jul 8 2019, 20:34:20) [MSC v.1916 64 bit (AMD64)] on win32
Type "help", "copyright", "credits" or "license" for more information.
>>> import selenium
这样没报错我们就安装完成,但是你以为这样就算好了么?图样图森破啊。
ChromeDriver
我们还需要浏览器的支持来配合 selenium 的工作,开发人员嘛,常用的浏览器莫非那么几种:Chrome、Firefox,那位说 IE 的同学,你给我站起来,小心我跳起来打你膝盖,还有说 360 浏览器的,你们可让我省省心吧。

接下来,安装 Chrome 浏览器就不用讲了吧。。。。
再接下来,我们开始安装 ChromeDriver ,安装了 ChromeDriver 后,我们才能通过刚才安装的 selenium 来驱动 Chrome 来完成各种骚操作。
首先,我们需要查看自己的 Chrome 浏览器的版本,在 Chrome 浏览器右上角的三个点钟,点击 帮助 -> 关于,如下图:
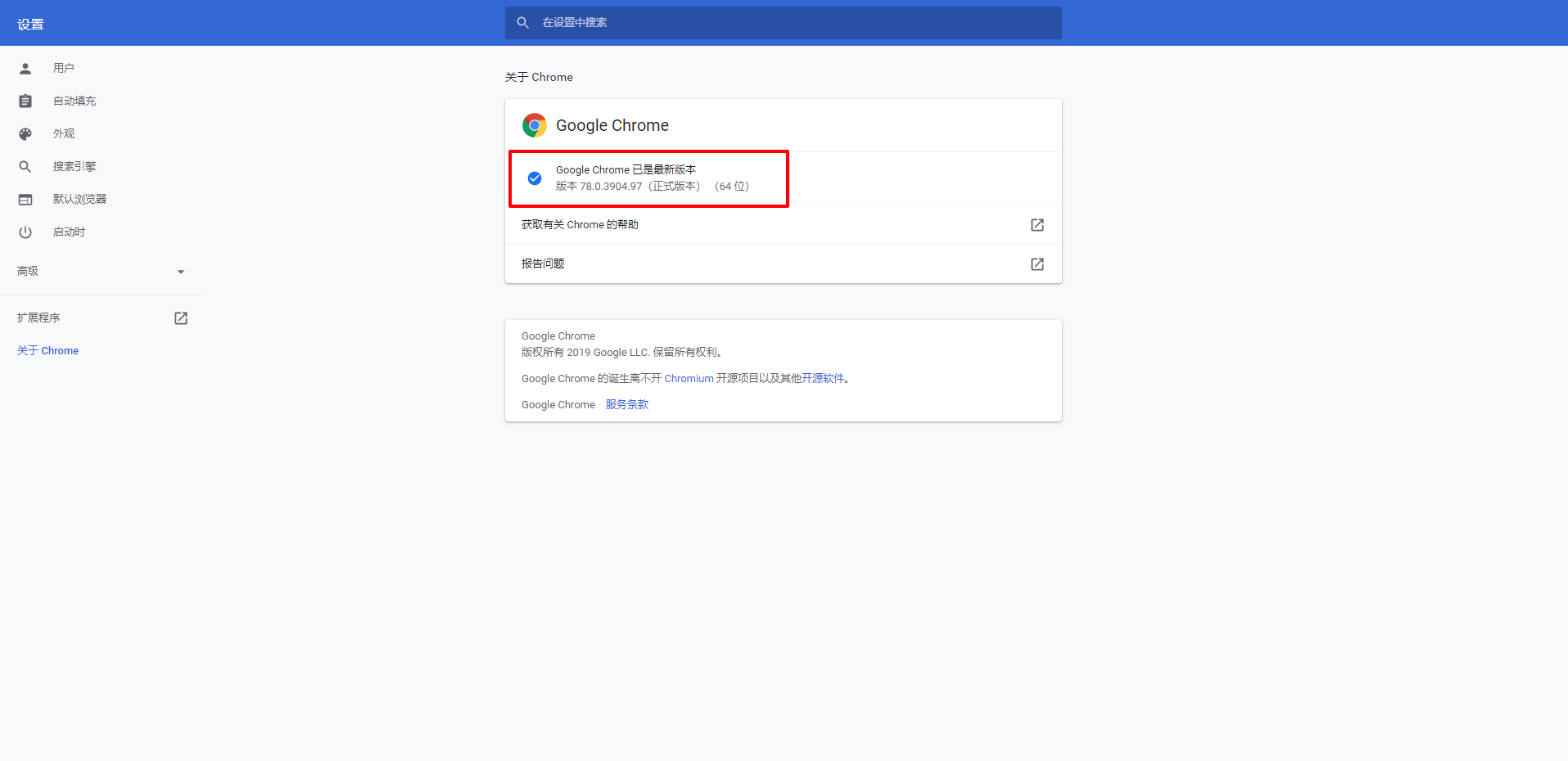
将这个版本找个小本本记下来,小编这里的版本为: 版本 78.0.3904.97(正式版本) (64 位)
接下来我们需要去 ChromeDriver 的官网查看当前 Chrome 对应的驱动。
官网地址: https://sites.google.com/a/chromium.org/chromedriver/
因某些原因,访问时需某些手段,访问不了的就看小编为大家准备的版本对应表格吧。。。
| ChromeDriver Version | Chrome Version |
|---|---|
| 78.0.3904.11 | 78 |
| 77.0.3865.40 | 77 |
| 77.0.3865.10 | 77 |
| 76.0.3809.126 | 76 |
| 76.0.3809.68 | 76 |
| 76.0.3809.25 | 76 |
| 76.0.3809.12 | 76 |
| 75.0.3770.90 | 75 |
| 75.0.3770.8 | 75 |
| 74.0.3729.6 | 74 |
| 73.0.3683.68 | 73 |
| 72.0.3626.69 | 72 |
| 2.46 | 71-73 |
| 2.45 | 70-72 |
| 2.44 | 69-71 |
| 2.43 | 69-71 |
| 2.42 | 68-70 |
| 2.41 | 67-69 |
| 2.40 | 66-68 |
| 2.39 | 66-68 |
| 2.38 | 65-67 |
| 2.37 | 64-66 |
| 2.36 | 63-65 |
| 2.35 | 62-64 |
顺便小编找到了国内对应的下载的镜像站,由淘宝提供,如下:
http://npm.taobao.org/mirrors/chromedriver
虽然和小编本地的小版本对不上,但是看样子只要大版本符合应该没啥问题,so,去镜像站下载对应的版本即可,小编这里下载的版本是:78.0.3904.70 ,ChromeDriver 78版本的最后一个小版本。
下载完成后,将可执行文件 chromedriver.exe 移动至 Python 安装目录的 Scripts 目录下。如果使用默认安装未修改过安装目录的话目录是:%homepath%\AppData\Local\Programs\Python\Python37\Scripts ,如果有过修改,那就自力更生吧。。。

将 chromedriver.exe 添加后结果如下图:

验证:
还是在 CMD 命令行中,输入以下内容:
C:\Users\inwsy>python
Python 3.7.4 (tags/v3.7.4:e09359112e, Jul 8 2019, 20:34:20) [MSC v.1916 64 bit (AMD64)] on win32
Type "help", "copyright", "credits" or "license" for more information.
>>> from selenium import webdriver
>>> browser = webdriver.Chrome()
如果打开一个空白的 Chrome 页面说明安装成功。
GeckoDriver
上面我们通过安装 Chrome 的驱动完成了 Selenium 与 Chrome 的对接,想要完成 Selenium 与 FireFox 的对接则需要安装另一个驱动 GeckoDriver 。
FireFox 的安装小编这里就不介绍了,大家最好去官网下载安装,路径如下:
FireFox 官网地址: http://www.firefox.com.cn/
GeckoDriver 的下载需要去 Github (全球最大的同性交友网站),下载路径小编已经找好了,可以选择最新的 releases 版本进行下载。
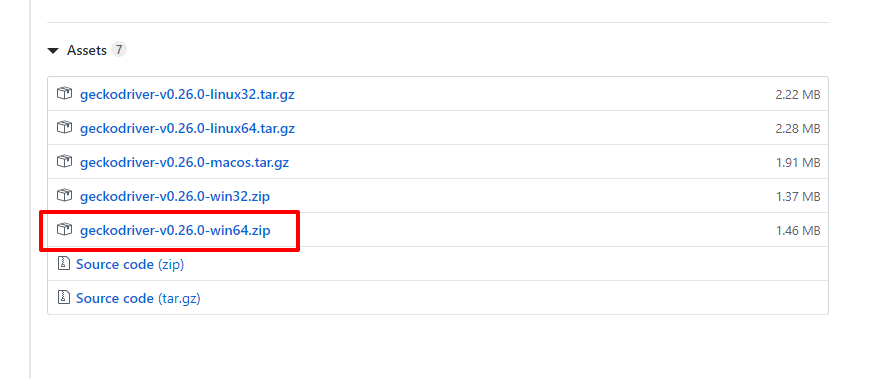
下载地址: https://github.com/mozilla/geckodriver/releases
选择对应自己的环境,小编这里选择 win-64 ,版本为 v0.26.0 进行下载。
具体配置方式和上面一样,将可执行的 .exe 文件放入 %homepath%\AppData\Local\Programs\Python\Python37\Scripts 目录下即可。
验证:
还是在 CMD 命令行中,输入以下内容:
C:\Users\inwsy>python
Python 3.7.4 (tags/v3.7.4:e09359112e, Jul 8 2019, 20:34:20) [MSC v.1916 64 bit (AMD64)] on win32
Type "help", "copyright", "credits" or "license" for more information.
>>> from selenium import webdriver
>>> browser = webdriver.Firefox()
应该是可以正常打开一个空白的 FireFox 页面的,结果如下:
注意: GeckoDriver 指出一点,当前的版本在 win 下使用有已知 bug ,需要安装微软的一个插件才能解决,原文如下:
You must still have the Microsoft Visual Studio redistributable runtime installed on your system for the binary to run. This is a known bug which we weren't able fix for this release.
插件下载地址: https://support.microsoft.com/en-us/help/2977003/the-latest-supported-visual-c-downloads
请各位同学选择自己对应的系统版本进行下载安装。
Aiohttp
上面我们介绍了同步的 Http 请求库 Requests ,而 Aiohttp 则是一个提供异步 Http 请求的类库。
那么,问题来了,什么是同步请求?什么是异步请求呢?
- 同步:阻塞式,简单理解就是当发出一个请求以后,程序会一直等待这个请求响应,直到响应以后,才继续做下一步。
- 异步:非阻塞式,还是上面的例子,当发出一个请求以后,程序并不会阻塞在这里,等待请求响应,而是可以去做其他事情。
从资源消耗和效率上来说,同步请求是肯定比不过异步请求的,这也是为什么异步请求会比同步请求拥有更大的吞吐量。在抓取数据时使用异步请求,可以大大提升抓取的效率。
如果还想了解跟多有关 aiohttp 的内容,可以访问官方文档: https://aiohttp.readthedocs.io/en/stable/ 。
aiohttp 安装如下:
pip install aiohttp
aiohttp 还推荐我们安装另外两个库,一个是字符编码检测库 cchardet ,另一个是加速DNS的解析库 aiodns 。
安装 cchardet 库:
pip install cchardet
安装 aiodns 库:
pip install aiodns
aiohttp 十分贴心的为我们准备了整合的安装命令,无需一个一个键入命令,如下:
pip install aiohttp[speedups]
验证:
C:\Users\inwsy>python
Python 3.7.4 (tags/v3.7.4:e09359112e, Jul 8 2019, 20:34:20) [MSC v.1916 64 bit (AMD64)] on win32
Type "help", "copyright", "credits" or "license" for more information.
>>> import aiohttp
没报错就安装成功。
解析库
lxml
lxml 是 Python 的一个解析库,支持 HTML 和 XML 的解析,支持 XPath 的解析方式,而且解析效率非常高。
什么是 XPath ?
XPath即为XML路径语言(XML Path Language),它是一种用来确定XML文档中某部分位置的语言。
XPath基于XML的树状结构,提供在数据结构树中找寻节点的能力。起初XPath的提出的初衷是将其作为一个通用的、介于XPointer与XSL间的语法模型。以上内容来源《百度百科》
好吧,小编说人话,就是可以从 XML 文档或者 HTML 文档中快速的定位到所需要的位置的路径语言。
还没看懂?emmmmmmmmmmm,我们可以使用 XPath 快速的取出 XML 或者 HTML 文档中想要的值。用法的话我们放到后面再聊。
安装 lxml 库:
pip install lxml
验证:
C:\Users\inwsy>python
Python 3.7.4 (tags/v3.7.4:e09359112e, Jul 8 2019, 20:34:20) [MSC v.1916 64 bit (AMD64)] on win32
Type "help", "copyright", "credits" or "license" for more information.
>>> import lxml
没报错就安装成功。
Beautiful Soup
Beautiful Soup 同样也是一个 Python 的 HTML 或 XML 的解析库 。它拥有强大的解析能力,我们可以使用它更方便的从 HTML 文档中提取数据。
首先,放一下 Beautiful Soup 的官方网址,有各种问题都可以在官网查看文档,各位同学养成一个好习惯,有问题找官方文档,虽然是英文的,使用 Chrome 自带的翻译功能还是勉强能看的。
官方网站:https://www.crummy.com/software/BeautifulSoup/
安装方式依然使用 pip 进行安装:
pip install beautifulsoup4
Beautiful Soup 的 HTML 和 XML 解析器是依赖于 lxml 库的,所以在此之前请确保已经成功安装好了 lxml 库 。
验证:
C:\Users\inwsy>python
Python 3.7.4 (tags/v3.7.4:e09359112e, Jul 8 2019, 20:34:20) [MSC v.1916 64 bit (AMD64)] on win32
Type "help", "copyright", "credits" or "license" for more information.
>>> from bs4 import BeautifulSoup
没报错就安装成功。
pyquery
pyquery 同样也是一个网页解析库,只不过和前面两个有区别的是它提供了类似 jQuery 的语法来解析 HTML 文档,前端有经验的同学应该会非常喜欢这款解析库。
首先还是放一下 pyquery 的官方文档地址。
官方文档: https://pyquery.readthedocs.io/en/latest/
安装:
pip install pyquery
验证:
C:\Users\inwsy>python
Python 3.7.4 (tags/v3.7.4:e09359112e, Jul 8 2019, 20:34:20) [MSC v.1916 64 bit (AMD64)] on win32
Type "help", "copyright", "credits" or "license" for more information.
>>> import pyquery
没报错就安装成功。
本篇的内容就先到这里结束了。请各位同学在自己的电脑上将上面介绍的内容都安装一遍,以便后续学习使用。
小白学 Python 爬虫(2):前置准备(一)基本类库的安装的更多相关文章
- 小白学 Python 爬虫(3):前置准备(二)Linux基础入门
人生苦短,我用 Python 前文传送门: 小白学 Python 爬虫(1):开篇 小白学 Python 爬虫(2):前置准备(一)基本类库的安装 Linux 基础 CentOS 官网: https: ...
- 小白学 Python 爬虫(4):前置准备(三)Docker基础入门
人生苦短,我用 Python 前文传送门: 小白学 Python 爬虫(1):开篇 小白学 Python 爬虫(2):前置准备(一)基本类库的安装 小白学 Python 爬虫(3):前置准备(二)Li ...
- 小白学 Python 爬虫(5):前置准备(四)数据库基础
人生苦短,我用 Python 前文传送门: 小白学 Python 爬虫(1):开篇 小白学 Python 爬虫(2):前置准备(一)基本类库的安装 小白学 Python 爬虫(3):前置准备(二)Li ...
- 小白学 Python 爬虫(6):前置准备(五)爬虫框架的安装
人生苦短,我用 Python 前文传送门: 小白学 Python 爬虫(1):开篇 小白学 Python 爬虫(2):前置准备(一)基本类库的安装 小白学 Python 爬虫(3):前置准备(二)Li ...
- 小白学 Python 爬虫(7):HTTP 基础
人生苦短,我用 Python 前文传送门: 小白学 Python 爬虫(1):开篇 小白学 Python 爬虫(2):前置准备(一)基本类库的安装 小白学 Python 爬虫(3):前置准备(二)Li ...
- 小白学 Python 爬虫(8):网页基础
人生苦短,我用 Python 前文传送门: 小白学 Python 爬虫(1):开篇 小白学 Python 爬虫(2):前置准备(一)基本类库的安装 小白学 Python 爬虫(3):前置准备(二)Li ...
- 小白学 Python 爬虫(9):爬虫基础
人生苦短,我用 Python 前文传送门: 小白学 Python 爬虫(1):开篇 小白学 Python 爬虫(2):前置准备(一)基本类库的安装 小白学 Python 爬虫(3):前置准备(二)Li ...
- 小白学 Python 爬虫(10):Session 和 Cookies
人生苦短,我用 Python 前文传送门: 小白学 Python 爬虫(1):开篇 小白学 Python 爬虫(2):前置准备(一)基本类库的安装 小白学 Python 爬虫(3):前置准备(二)Li ...
- 小白学 Python 爬虫(11):urllib 基础使用(一)
人生苦短,我用 Python 前文传送门: 小白学 Python 爬虫(1):开篇 小白学 Python 爬虫(2):前置准备(一)基本类库的安装 小白学 Python 爬虫(3):前置准备(二)Li ...
随机推荐
- 使用css实现导航下方线条随导航移动效果
HTML部分 <ul> <li><a href="">第一条</a></li> <li><a href ...
- Python之文件的使用
文件概述 读写文件是最常见的IO操作.Python内置了读写文件的函数,用法和C是兼容的. 读写文件前,我们先必须了解一下,在磁盘上读写文件的功能都是由操作系统提供的,现代操作系统不允许普通的程序直接 ...
- java web项目下的lib和build path 中jar包问题解惑
一.build path&WEB-INFO/lib介绍 build path:可以说是引用: WEB-INFO/lib:可以说是固定在一个地方: eclipse编译项目的时候是根据build ...
- 【网络安全】SQL注入、XML注入、JSON注入和CRLF注入科普文
目录 SQL注入 一些寻找SQL漏洞的方法 防御SQL注入 SQL注入相关的优秀博客 XML注入 什么是XML注入 预防XML注入 JSON注入 什么是JSON注入 JSON注入的防御 CRLF注入 ...
- justjavac(迷渡)知乎live--<<前端工程师的入门与进阶>>听讲总结
知乎听讲总结 知乎live----jjc<前端工程师的入门进阶> git地址 内容 前端的基础知识,计算机专业基础知识感觉还行.前端后台都有做过,现在觉得自己要深入.但是只看框架源码和自己 ...
- 关于Java 项目的思考总结
Java 项目思考总结 前言 今天是2017年3月25日,笔者已经毕业半年,工作经验一年. 正好有心思写这个总结. 持续开发 对于Java项目,我所接触的一般就是JavaWeb项目和 Java Jar ...
- 设计模式C++描述----11.组合(Composite)模式
一. 举例 这个例子是书上的,假设有一个公司的组结结构如下: 它的结构很像一棵树,其中人力资源部和财务部是没有子结点的,具体公司才有子结点. 而且最关健的是,它的每一层结构很相似. 代码实现如下: / ...
- 如何理解swift中的delegate
Delegation翻译为代理或者委托,是一种设计模式.顾名思义,使class或struct能够将某些职责移交给其他类型的实例. 该设计模式通过定义一个封装(包含)delegate的protocol( ...
- 题解和总结——noip2019集训测试赛(一)贪吃蛇+字符串+都城
Problem A: 贪吃蛇 描述 Input Output Sample Input [样例输入1] 4 5 ##... ..1#@ 432#. ...#. [样例输出1] 4 [样例输入2] 4 ...
- 2684亿!阿里CTO张建锋:不是任何一朵云都撑得住双11
2019天猫双11 成交额2684亿! "不是任何一朵云都能撑住这个流量.中国有两朵云,一朵是阿里云,一朵叫其他云."11月11日晚,阿里巴巴集团CTO张建锋表示,"阿里 ...