基于http(s)协议的模板化爬虫设计
声明:本文为原创,转载请注明出处
本文总共三章,前面两章废话吐槽比较多,想看结果的话,直接看第三章(后续会更新,最近忙着毕设呢,毕设也是我自己做的,关于射频卡的,有时间我也放上来,哈哈)。
- 一,系统总体结构
首先吐槽一下,标题取得好水,原谅我是一枚耿直的工科男。系统框图如下所示,简单看一下,对整体有个把握,总体由4个部分组成
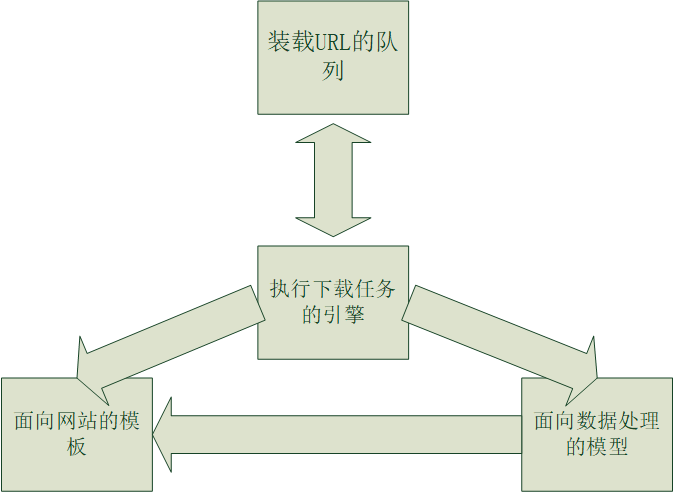
上图中,装载URL队列的是先进先出的队列,整个爬虫系统的设计就是基于宽度优先遍历的原则设计的。所以,对于执行整个下载任务的引擎而言,它只是启动一个线程池,然后机械的从队列里面拿出链接,下载网页,然后再将网页中的链接放到队列里面,循环上面的操作。由于每一个站点都有其自身布局的特点,比如特定的编码,特定的URL格式,面向站点的模板需要提供这些特点,以方便爬取效率和自己想要得到的效果。对于一张网页,我们真正关心的,讲个实话,只是一部分数据,所以在模板获取数据之前,是先需要对数据进行过滤,排版等相关处理的,面向数据处理的模型就是为了解决这个问题而产生的。(我去感觉这段话,有种催眠的感觉,发现自己表达能力好差。)
- 二,设计思想及核心流程图
说点题外话,关于爬虫的的实现,网上很多,但是只要你不是我这样的大老粗,你仔细看就会发现,所有的实现基本都是机械抓取URL,最为致命的是抓取的URL还有可能是相对URL。那什么获取个性化数据就有点大海捞针的感觉了。哈哈,自恋一下,本爬虫就可以大海捞针(你也可以当笑话看,否则这玩意太枯燥了)。其实我感觉的话,爬虫的核心无非就两个:一是要能很好的处理URL,二是方便获取想要的数据。至于什么效率,鄙人认为,在这个计算机处理能力飞速提示的年代,不是那么重要。
下面是整个引擎执行流程图:
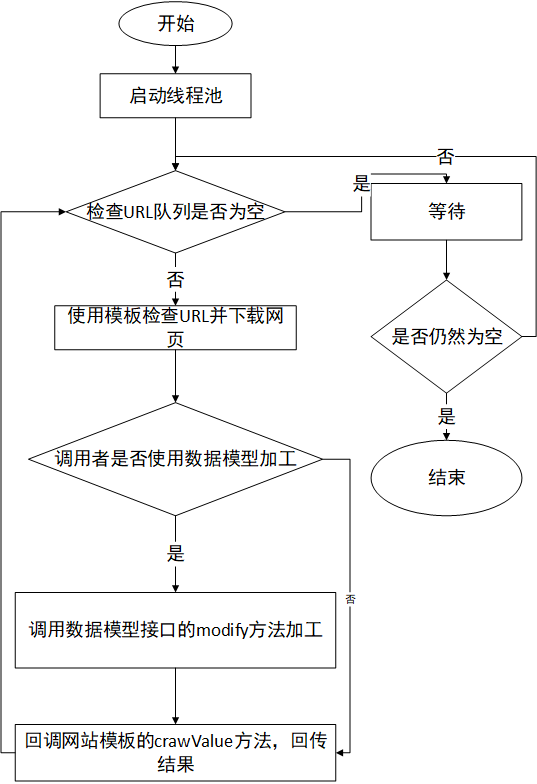
上图十分清楚的描述了整个引擎的执行流程图,现在一看好像很简单,但是当时写起来,那个问题,不想说了,不利于弘扬社会主义核心价值观,哈哈。至于到底是怎么用我会把代码放出来(留言qq索取也行,githup还没有建仓库呢),有了这个图大家看起来,也方便些。接下来,实在是不想废话了,直接看使用demo。
- 三,实践
正所谓实践是检验真理的唯一标准,这里以抓取阿里巴巴旗下蚂蚁金服的基金数据为例子,进行简单讲解一下。
3.1 定义一个基于该网站的引擎类。此类需要导入我开发的包,然后继承自Spider。Spider有几个函数是用于子类重载的。主要的也就是下面的三个重载子函数.详情看注释
public class AliFundtion extends Spider {
private WebClient webClient=new WebClient();
private Pattern HREF=Pattern.compile("href=\"(.*?)\"");
public AliFundtion(int maxSize,int threadSize){
super(maxSize,threadSize);
initWebOptions();
}
private void initWebOptions(){
webClient.setAjaxController(new NicelyResynchronizingAjaxController());
webClient.getOptions().setJavaScriptEnabled(true);
webClient.getOptions().setCssEnabled(false);
webClient.getOptions().setTimeout(35000);
webClient.getOptions().setThrowExceptionOnScriptError(false);
}
/**
* 通过重载这个函数,我们这里只抓取蚂蚁金服首页展示的基金数据,因为它首页包含了所有的基金,
* 这个函数决定了URL队列里面到底有哪些链接,是引擎的抓取的来源
* @param html 抓取到的网页
* @param url 该网页对应的URL
* @param que URL队列
*/
@Override
protected void allHrefEnQueue(String html, String url, SpiderQueue que) {
if(url.equals("http://www.fund123.cn/fund")){//断定是首页
List<String> hrefs=RegexUtil.getAllMatcher(html,1,HREF);
for(String href:hrefs){
String absoUrl=Browser.relative2TrUri(href,url);//转化为绝对路径
if(absoUrl.startsWith("http://www.fund123.cn/matiaria?fundCode")){//这正是我们需要的基金数据
que.enQueue(absoUrl);
}
}
}
}
/**
* 这个函数决定了,通过URL获取网页的方式,对于需要执行js代码的网页而言,重载这个函数是必须得,比如这里就是基于htmlUnit重载了Spider的这个函数
* @param url 即将抓取的URL
* @param charset 所用的字符编码
* @return 返回抓取到的数据
* @throws IOException
*/
@Override
synchronized protected String toGetHtmlPage(String url, String charset) throws IOException {
HtmlPage page=webClient.getPage(url);
return page.asXml();
}
/**
* 注意这里必须调用父类的close()方法,来释放一些资源
*/
@Override
protected void close() {
super.close();
webClient.close();
}
}
3.2 主程序调用步骤
public class Main {
public static void main(String[] args) {
//step1: 创建一个你自己定义的爬虫引擎,第一个参数表示队列的最大容量,第二个参数表示开启线程池中线程数量
AliFundtion aliFundtion=new AliFundtion(50,6);
//step2:定义你自己的站点模板
ICrawlTemplate temp=new AbstractTemplate() {
@Override
public void crawlValue(String html, String url) {
//todo 在这里写下你想做的事,比如将得到的数据持久化到数据库,或者保存到磁盘,其中html表示被数据模型修饰后的数据,url是该html对应的链接
System.out.println(html);
}
@Override
public String getBaseSite() {
return "http://www.fund123.cn/fund";
}
@Override
public String getCharset() {
return null;
}
@Override
public boolean filterUrl(String url) {
return true;
}
};
//step3:采用正则表达式进行数据建模
//<_%></_%>这是一对表示这个一个正则表达式的标签
//index 属性 就是该正则表达式需要提取的组
StringBuilder sb=new StringBuilder();
sb.append("基金名称:").append("<_% index=\"1\">").append("<span class=\"fundmatiaria-title-fundname\">(.*?)</span>").append("</_%>");
sb.append("基金代码:").append("<_% index=\"1\">").append("<span class=\"fundmatiaria-title-fundcode\">(.*?)</span>").append("</_%>");
sb.append("基金净值:").append("<_% index=\"1\">").append("<p class=\"fundmatiaria-fundinfo-value\".*?>(.*?)</p>").append("</_%>");
RegexModel model=new RegexModel(sb.toString());
model.getOptions().setAbsoJs(true);//表示将所有js路径转化为绝对路径
model.getOptions().setAbsoImage(true);//表示将所有image路径转化为绝对路径
model.getOptions().setAbsoCss(true);//表示将所有css路径转化为绝对路径
aliFundtion.setModel(model);
//step4:下载模板
aliFundtion.downLoadArtcle(temp);
}
}
3.3 看一下结果:
基金名称:南方原油(QDII-FOF)
基金代码:(501018)
基金净值:1.1502 +1.42% -1.57%
基金名称:广发道琼斯美国石油开发与生产指数(QDII-LOF)A
基金代码:(162719)
基金净值:1.1371 +1.65% +0.04%
基金名称:银华心诚灵活配置混合
基金代码:(005543)
基金净值:0.9507 +1.79% +1.79%
基于http(s)协议的模板化爬虫设计的更多相关文章
- 基于UDP传输协议局域网文件接收软件设计 Java版
网路传输主要的两大协议为TCP/IP协议和UDP协议,本文主要介绍基于UDP传输的一个小软件分享,针对于Java网络初学者是一个很好的练笔,大家可以参考进行相关的联系,但愿能够帮助到大家. 话不多说, ...
- 基于Heritrix的特定主题的网络爬虫配置与实现
建议在了解了一定网络爬虫的基本原理和Heritrix的架构知识后进行配置和扩展.相关博文:http://www.cnblogs.com/hustfly/p/3441747.html 摘要 随着网络时代 ...
- 利用Aspose.Word控件和Aspose.Cell控件,实现Word文档和Excel文档的模板化导出
我们知道,一般都导出的Word文档或者Excel文档,基本上分为两类,一类是动态生成全部文档的内容方式,一种是基于固定模板化的内容输出,后者在很多场合用的比较多,这也是企业报表规范化的一个体现. 我的 ...
- 读书笔记 effective c++ Item 43 了解如何访问模板化基类中的名字
1. 问题的引入——派生类不会发现模板基类中的名字 假设我们需要写一个应用,使用它可以为不同的公司发送消息.消息可以以加密或者明文(未加密)的方式被发送.如果在编译阶段我们有足够的信息来确定哪个信息会 ...
- 基于JT/T808协议的车辆监控平台架构方案
技术支持QQ:78772895 1.接入网关应用采用mina/netty+spring架构,独立于其他应用,主要负责维护接入终端的tcp链接.上行以及下行消息的解码.编码.流量控制,黑白名单等安全控制 ...
- 基于 Scrapy-redis 两种形式的分布式爬虫
基于 Scrapy-redis 两种形式的分布式爬虫 .caret, .dropup > .btn > .caret { border-top-color: #000 !important ...
- 基于Nutch+Hadoop+Hbase+ElasticSearch的网络爬虫及搜索引擎
基于Nutch+Hadoop+Hbase+ElasticSearch的网络爬虫及搜索引擎 网络爬虫架构在Nutch+Hadoop之上,是一个典型的分布式离线批量处理架构,有非常优异的吞吐量和抓取性能并 ...
- 基于TCP/IP协议的C++网络编程(API函数版)
源代码:http://download.csdn.net/detail/nuptboyzhb/4169959 基于TCP/IP协议的网络编程 定义变量——获得WINSOCK版本——加载WINSOCK库 ...
- 从零開始学习制作H5应用——V5.0:懊悔机制,整理文件夹,压缩,模板化
经过前面四个版本号的迭代.我们已经制作了一个从视觉和听觉上都非常舒服的H5微场景应用,没有看过的请戳以下: V1.0--简单页面滑动切换 V2.0--多页切换.透明过渡及交互指示 V3.0--增加lo ...
随机推荐
- [Vue 牛刀小试]:第十五章 - 传统开发模式下的 axios 使用入门
一.前言 在没有接触 React.Angular.Vue 这类 MVVM 的前端框架之前,无法抛弃 Jquery 的重要理由,除了优秀的前端 DOM 元素操作性以外,能够非常便捷的发起 http 请求 ...
- POJ 2728:Desert King(最优比率生成树)
http://poj.org/problem?id=2728 题意:有n个点,有三个属性代表每个点在平面上的位置,和它的高度.点与点之间有一个花费:两点的高度差:还有一个长度:两点的距离.现在要让你在 ...
- 计算机以及Python的初始
电脑的介绍 CPU:中央处理器,相当于人类的大脑 内存:暂时储存数据,速度快,造价高,断电后丢失 硬盘:长期储存数据.速度相对慢,造价相对低 操作系统:一个软件,连接计算机硬件和系统中的软件. Pyt ...
- 单个单选框radio 点击选中点击取消选中
$("input:radio").click(function(){ var domName = $(this).attr('name');//获取当前单选框控件name 属性值 ...
- Python中字符串常见操作
(1)find 查找 格式:mystr.find(str, start, end) 例如: mystr.find(str, start=0, end=len(mystr)) 作用:检测str是否包含在 ...
- SQL Server 函数的定义及使用
一.定义函数 1. 标量值函数: 返回一个确定类型的标量值,例如:int,char,bit等 --创建标量值函数 create function func_1(@func_parameter_1 in ...
- 齐治运维堡垒机后台存在命令执行漏洞(CNVD-2019-17294)分析
基本信息 引用:https://www.cnvd.org.cn/flaw/show/CNVD-2019-17294 补丁信息:该漏洞的修复补丁已于2019年6月25日发布.如果客户尚未修复该补丁,可联 ...
- python对Excel的读取
在python自动化中,经常会遇到对数据文件的操作,比如添加多名员工,但是直接将员工数据写在python文件中,不但工作量大,要是以后再次遇到类似批量数据操作还会写在python文件中吗? 应对这一问 ...
- Linux磁盘与分区
正在从新装载虚拟机,碰到磁盘分区一阵头大,花了一下午对分区的基本原理做了一个梳理 一.磁盘 硬盘内部结构:
- 数据库触发器_trigger
部门表_删除: USE [test] GO /****** Object: Trigger [dbo].[部门_Delete] Script Date: 2015/8/31 16:41:46 **** ...