数据分析入门——pandas之DataFrame数据丢失
一、数据丢失分类
1)nd中分为两种:None和np.nan(NaN)
其中,None是python中的对象,是一个object;而nan是一个float类型
两种不同的类型,运算速度也是不同的
2)pandas中两种都视作NaN(np.nan)
二、数据丢失处理
通过控制columns来创建有NaN的数据:

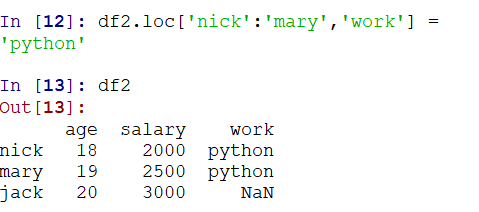
通过loc切片赋值来处理部分NaN数据:
1.与空相关的方法
检测:
isnull()和notnull()

如何检测df中哪些行中存在空行?
df.isnull().any(axis=1): True行中存在空 False行中不存在空(any的字面意思就是该行有一个为True即为True)
df.notnull().all(axis=1): False行中存在空 True行中不存在空(all与上面any类似,也就是逻辑里面的与操作了)
过滤:
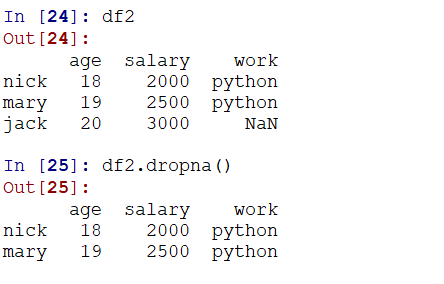
dropna() --可以选择过滤行还是列(默认为行,也就是axis = 0,有空行则删除)
可以通过how参数来控制,是any还是all(存在就剔除还是全部才剔除)
dropna(how = 'all')
这里重复一下,轴的概念:
根据stackoverflow答主解释,axis=0指的是逐行,轴是Index;axis=1指的是逐列,轴是columns。(index (0), columns (1))
根据结果:
mean(axis=0)计算的是每一列平均值,
mean(axis=1)计算的是每一行平均值。(轴是columns)
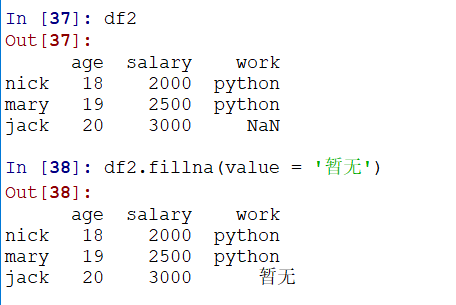
填充:(可以填充Series/DataFrame)
fillna(value = xx)
对所有的na都进行填充
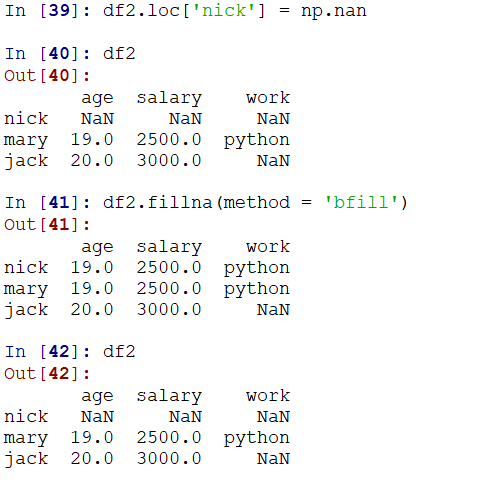
可以通过method选择向后填充(bfill,使用后一个的值进行填充,文档有详细参数解释),或者向前(ffill)填充
注意,此处是返回一个填充后的副本,本身并没有改变,可以通过inplace参数来控制
数据分析入门——pandas之DataFrame数据丢失的更多相关文章
- 数据分析入门——pandas之DataFrame基本概念
一.介绍 数据帧(DataFrame)是二维数据结构,即数据以行和列的表格方式排列. 可以看作是Series的二维拓展,但是df有行列索引:index.column 推荐参考:https://www. ...
- 数据分析入门——pandas之DataFrame多层/多级索引与聚合操作
一.行多层索引 1.隐式创建 在构造函数中给index.colunms等多个数组实现(datafarme与series都可以) df的多级索引创建方法类似: 2.显式创建pd.MultiIndex 其 ...
- 数据分析入门——pandas之Series
一.介绍 Pandas是一个开源的,BSD许可的库(基于numpy),为Python编程语言提供高性能,易于使用的数据结构和数据分析工具. 官方中文文档:https://www.pypandas.cn ...
- 数据分析入门——Pandas类库基础知识
使用python进行数据分析时,经常会用Pandas类库处理数据,将数据转换成我们需要的格式.Pandas中的有两个数据结构和处理数据相关,分别是Series和DataFrame. Series Se ...
- 数据分析入门——pandas数据处理
1,处理重复数据 使用duplicated检测重复的行,返回一个series,如果不是第一次出现,也就是有重复行的时候,则为True: 对应的,可以使用drop_duplicates来删除重复的行: ...
- 数据分析入门——pandas之数据合并
主要分为:级联:pd.concat.pd.append 合并:pd.merge 一.numpy级联的回顾 详细参考numpy章节 https://www.cnblogs.com/jiangbei/p/ ...
- 数据分析入门——pandas之合并函数merge
merge有点类似SQL中的join,可以将不同数据集按照某些字段进行合并,得到新的数据集 1.参数一览表: 2.一对一连接:默认情况下,会按照相同字段的进行连接 例如有相同字段emp的两个df,m ...
- Python数据分析入门之pandas基础总结
Pandas--"大熊猫"基础 Series Series: pandas的长枪(数据表中的一列或一行,观测向量,一维数组...) Series1 = pd.Series(np.r ...
- 利用python进行数据分析之pandas入门
转自https://zhuanlan.zhihu.com/p/26100976 目录: 5.1 pandas 的数据结构介绍5.1.1 Series5.1.2 DataFrame5.1.3索引对象5. ...
随机推荐
- 21.centos7基础学习与积累-007-远程连接
从头开始积累centos7系统运用 大牛博客:https://blog.51cto.com/yangrong/p5 IP地址: 互联网上的计算机 都会有一个唯一的32位的地址,ip地址,我们访问服务器 ...
- Linux访问控制列表(Access Control List,简称ACL)
Linux访问控制列表(Access Control List,简称ACL) 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. 一.ACL概述 ACL:Access Control L ...
- 矩阵指数 Matrix Exponentials
转自:https://zh.wikipedia.org/wiki/%E7%9F%A9%E9%98%B5%E6%8C%87%E6%95%B0 其中,X. X2.X3…….Xk 都是n阶矩阵,显然 exp ...
- SparkSQL读写外部数据源--csv文件的读写
object CSVFileTest { def main(args: Array[String]): Unit = { val spark = SparkSession .builder() .ap ...
- 做勇敢女孩 https://www.bilibili.com/video/av14346123?from=search&seid=14078047355739050009
So a few years ago, I did something really brave, or some would say really stupid. I ran for congres ...
- 洛谷 P3388 【模板】割点(割顶)题解
今天学了割点,就A了这道板子,比较难理解的地方就在于如果是根节点就要找两个点来满足low[y]>=dfn[x],如果不是就只需找一个点来满足.Tarjan(i,i)中第一个i是开始搜索的点而第 ...
- [译博文]CUDA是什么
翻译自:https://blogs.nvidia.com/blog/2012/09/10/what-is-cuda-2/ 你可能并没有意识到,GPU的应用有多广泛,它不但用于视频.游戏以及科学研究中, ...
- 【JZOJ6227】【20190621】ichi
题目 $n , m ,d,x\le 10^5 , $强制在线 题解 对原树做dfs,得到原树的dfs序 对kruksal重构树做dfs,得到重构树的dfs序 那么就是一个三维数点问题 强制在线并且卡空 ...
- 【loj3059】【hnoi2019】序列
题目 给出一个长度为 \(n\) 的序列 \(A\) ; 你需要构造一个新的序列\(B\) ,满足: $B_{i} \le B_{i+1} (1 \le i \lt n ) $ $\sum_{i=1} ...
- mysql regexp 表达式
mysql> select * from test; +----+----------+-------+-----------+ | id | name | score | subject | ...