[IR] Inverted Index & Boolean retrieval
教材:《信息检索导论》
倒排索引
How to build Inverted Index?
1. Token sequence.
2. Sort by terms.
3. Dictionary & Postings
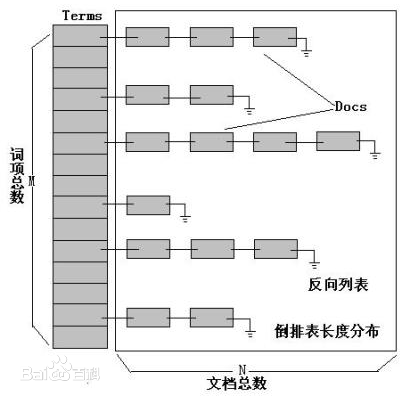
查询同时包含两单词的文档
【Qword1 and Qword2】
等高线式前进。
O(x+y)

【Qword1 and not Qword2】
O(m*log2n) = m个中的any one都要查看n个中是否也有(二分查找)。
【Qword1 or not Qword2】
O(m+n)
【Qword1 and Qword2 and Qword3 and ...】
借助 min-heap, 找 list 的时间。
Update min-heap: O(log2k), k = number of lists.
O(Total_Length * log2k)
Galloping Search
跳表:【Qword1 and Qword2】
- 源于skip pointers, but how to placing skip?
- L1/2
Normally, len(a) < len(b)
O( 2a*log2(b/a) ) [ better than O(a*log2b) 二分查找 ]
Stage1: Σi = 1log2(ni) = log2Πi=1(ni) <= log2(Σ(ni)/a)a (柯西不等式) = log2(b/a)a = a*log2(b/a)
Stage2: 二分查找的cost与Stage1相近(因为都是2的指数级增长)

Pharse Queries
Biword Indexes
Ref: 《信息检索导论》第二章总结
排列组合。但总有些组合是没用的,导致False Positive增加。
所以要Filter out.
将两个词看成一个item,即在dictionary中都是两个词为一组。
比如invert and revert,则会变成invert and和and revert;但是这种做法使得倒排记录表迅速变大。
这种方法的缺点很多:
(1)不适用于单词查询。
(2)倒排记录表太大。
(3)查询有时还不正确。需要进行后过滤(即在查询词组中过滤一遍)
折中策略
(1)对于单个单词出现次数非常多,而组成一个词组后出现次数大大减少的词组,用biword index;
(2)对于那些经常被用户查询的词组,使用biword index;
(3)其余使用positional index【接下来的内容】
Positional Index --> Proximity Queries
支持位置信息查询

k词邻近搜索
对两个单词的位置有要求,比如两个单词必须“相距五个单词以内”。


Figure, 邻近搜索中两个倒排记录表 p1 和 p2 的合并算法,算法寻找两个词项在 k 个词之内出现的情形,
返回一个三元组<文档 ID,词项在 p1中的位置,词项在 p2中的位置>的列表。
Step:
步骤(3)表示,再搜索M上的后面的词的话,这一段就不需要再看了,也就是N链其实是需要被遍历一遍。

End.
[IR] Inverted Index & Boolean retrieval的更多相关文章
- [IR] Boolean retrieval
How to build Inverted Index? 1. Token sequence. 2. Sort by terms. 3. Dictionary & Postings code ...
- [信息检索] 第一讲 布尔检索Boolean Retrieval
第一讲 布尔检索Boolean Retrieval 主要内容: 信息检索概述 倒排记录表 布尔查询处理 一.信息检索概述 什么是信息检索? Information Retrieval (IR) is ...
- [Search Engine] Compression in Inverted Index
最近在学一些搜索引擎的内容,感觉挺费劲,所以就用博客当做自己的笔记,遇到一些需要整理的部分,就在这里整理一下. 今天的内容是对inverted index进行压缩.核心思想,用我自己的话来总结,就是“ ...
- Fielddata is disabled on text fields by default. Set fielddata=true on [gender] in order to load fielddata in memory by uninverting the inverted index. Note that this can however use significant memor
ES进行如下聚合操作时,会报如题所示错误: ➜ Downloads curl -XPOST 'localhost:9200/bank/_search?pretty' -d ' { "size ...
- 倒排索引(Inverted Index)
倒排索引(Inverted Index) 倒排索引是一种索引结构,它存储了单词与单词自身在一个或多个文档中所在位置之间的映射.倒排索引通常利用关联数组实现.它拥有两种表现形式: inverted fi ...
- 正排索引(forward index)与倒排索引(inverted index)
正常的索引一般是指关系型数据库里的索引. 把不同的数据存放到不同的字段中.如果要实现baidu或google那种搜索,就需要与一条记录的多个字段进行比对,需要 全表扫描,如果数据量比较大的话,性能就很 ...
- 反向索引(Inverted Index)
转自:http://zhangyu8374.iteye.com/blog/86307 反向索引是一种索引结构,它存储了单词与单词自身在一个或多个文档中所在位置之间的映射.反向索引通常利用关联数组实现. ...
- Elasticsearch 报错:Fielddata is disabled on text fields by default. Set `fielddata=true` on [`your_field_name`] in order to load fielddata in memory by uninverting the inverted index.
Elasticsearch 报错: Fielddata is disabled on text fields by default. Set `fielddata=true` on [`your_fi ...
- Elasticsearch:inverted index,doc_values及source
以后会用到的相关知识:索引中某些字段禁止搜索,排序等操作 当我们学习Elasticsearch时,经常会遇到如下的几个概念: Reverted index doc_values source? 这个几 ...
随机推荐
- Docker容器网络篇
Docker容器网络篇 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. 一.Docker的网络模型概述 如上图所示,Docker有四种网络模型: 封闭式网络(Closed conta ...
- css3卡片阴影效果
1.css3阴影用到的知识点:阴影box-shadow和插入:after before HTML部分: <!DOCTYPE html> <html> <head> ...
- Codeforces B. Too Easy Problems
题目描述: time limit per test 2 seconds memory limit per test 256 megabytes input standard input output ...
- Python学习进阶
阅读目录 一.python基础 二.python高级 三.python网络 四.python算法与数据结构 一.python基础 人生苦短,我用Python(1) 工欲善其事,必先利其器(2) pyt ...
- background-image:url为空引发的两次请求问题
参考文章: https://blog.csdn.net/jsjhushilei/article/details/51101014 1.Nicholas 在 2009 年就开始推动各浏览器厂商,现在看起 ...
- 回调方式进行COM组件对外消息传递
情景:被调用者--COM组件:调用者---外部程序作用:COM组件 到 外部程序 的消息传递方法: 1.外部程序通过接口类对象,访问接口类的方法.COM对象通过连接点方式,进行消息的反向传递. 2.外 ...
- MP4文件批量转码成MP3
需求背景:最近为了学python爬虫,在论坛里找了不少视频教程,非常棒.但有时看视频不方便,就想着能否把视频批量转码成音频,这样在乘坐地铁公交的时候也能学习了. 解决路径:有了需求,我首先在论坛里搜了 ...
- python开发笔记-变长字典Series的使用
Series的基本特征: 1.类似一维数组的对象 2.由数据和索引组成 import pandas as pd >>> aSer=pd.Series([1,2.0,'a']) > ...
- clause
clause 英 [klɔːz] 美 [klɔz] 口语练习 跟读 n. 条款:[计] 子句 specify 英 ['spesɪfaɪ] 美 ['spɛsɪfaɪ] 口语练习 跟读 vt. 指 ...
- Impala 介绍(转载)
一.简介 1.概述 Impala是Cloudera公司推出,提供对HDFS.Hbase数据的高性能.低延迟的交互式SQL查询功能. •基于Hive使用内存计算,兼顾数据仓库.具有实时.批处理.多并发等 ...