了解Spark
Apache Spark是一个开源的集群计算框架,主要用来处理实时生成的数据。
Spark是建立在Hadoop的MapReduce顶部。它被优化到了内存中运行,而MapReduce等替代方法是将数据写入硬盘或从硬盘中写入数据,因此,Spark比其它替代方法运行速度更快。
Apache Spark的特点:
- 快速——Spark使用的是DAG(有向无环图)调度程序,为批处理和流数据提供高性能;
- 易于使用——它有助于使用Java、Scala、Python以及R和SQL编写应用程序,还提供了80多个运算符。
- 通用性——它提供了一系列的库,包含SQL、DataFrame以及用于机器学习的MLlib、GraphX和Spark Streaming。
- 轻量级——它是一个轻型统一分析执行引擎,用于大规模的数据处理;
- 无处不在——它可以轻松运行在Hadoop、Apach Mesos、Kubernetes或独立云端。
Spark的应用:
- 数据集成——系统生成的数据不够整合,无法进行结合分析,Spark可以减少提取、转换、加载(数据仓库ETL技术)等过程的成本和时间;
- 流处理——处理实时生成的数据总是很困难(如日志文件),Spark可以运行流数据并拒绝潜在的欺诈性操作;
- 机器学习——Spark可以将数据存贮在内存中并且可以快速运行重复的查询,因此可以轻松处理机器学习算法;
- 交互式分析——Spark可以快速生成相应,因此可以交互式处理数据,而非运行预定义的查询。
Spark架构:
- Spark遵循主从架构,它的集群有一个主服务器和多个从服务器组成;
- Spark架构依赖于两个抽象:弹性分布式数据集(RDD);有向无环图(DAG);
弹性分布式数据集(RDD):可以存储在工作节点上内存的数据组项。
- 弹性——失败时可以恢复数据;
- 分布式——数据分布在不同的节点之间;
- 数据集——数据组。
- DAG中每个节点Node都是RDD分区。
Spark架构图:
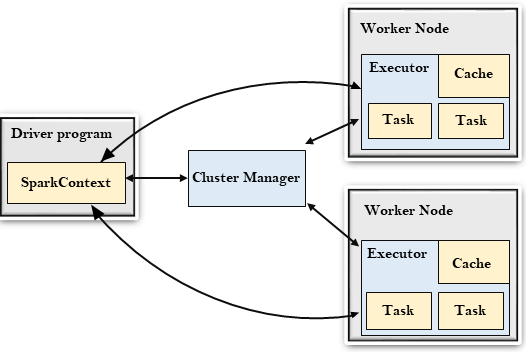
Driver Progarm:
- 驱动程序是一个运行应用程序,由
main()函数启动并创建SparkContext对象的进程。SparkContext的目的是协调spark应用程序,作为集群上的独立进程运行。要在群集上运行,SparkContext将连接到不同类型的群集管理器,然后执行以下任务:- 在集群的节点上获取执行程序;
- 将应用程序的代码发送给执行程序;
- 将任务发送给执行程序并运行。
Cluster Manager:
- 主要作用是跨应用程序分配资源;
- Spark能够在大量的集群上运行,它是由各种类型的集群管理器组成(例如:Hadoop Yarn、Apach Mesos、Standalone等);
Work Node:
- 工作节点是Spark的从节点;
- 它的作用是在集群中运行应用程序代码。
Executor:
- 执行程序是为工作节点上应用程序启动的进程;
- 它运行任务并将数据保存在内存或磁盘中;
- 将数据读写到外部源;
- 每个应用程序都包含其执行者。
Task:
- 任务是被发送给一个执行程序的工作单位。
Spark 组件:
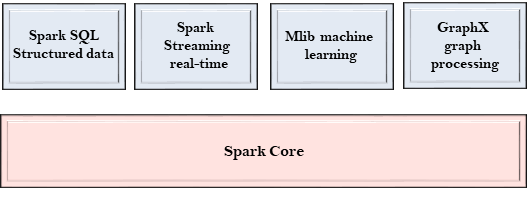
Spark 是一个计算引擎,可以组织、分发和监控多个应用程序,由不同的组件紧密集成。
Spark Core:
- Spark的核心,用来执行核心功能;
- 包含任务调度,故障恢复,与存储系统和内存管理交互的组件。
Spark SQL:
- 它构建于Spark core之上,为结构化数据提供支持;
- 它允许通过SQL(结构化查询语言)以及Hive查询数据;
- 它支持JDBC和ODBC连接,用于连接建立Java对象与现有数据库、数据仓库、商业智能工具之间的连接;
- 支持各种数据源,如Hive表、Parquet和Json
Spark Streaming:
- 用来支持流数据的可伸缩和容错处理;
- 它可以使用Spark Core的快速调度功能来执行流分析;
- 接受小批量数据并对数据执行RDD转换;
- 它的设计确保流数据编写的应用程序可以重复使用,只需要很少的修改即可分析批量的历史数据;
- Web服务器生成的日志文件可以视为流数据的实时示例,
MLib:
- 它是一个机器学习库,包含各种机器学习算法;
- 包含相关性和假设检验,分类、回归、聚类和主成分分析;
- 它比Apach Mahout使用的基于磁盘的实现快9倍。
GraphX:
- 它是一个用于操作图形和执行图形并行计算的库;
- 有助于创建一个有向图,可以任意属性附加到每个顶点和边;
- 要操纵图形,它支持各种基本运算符,如子图、连接顶点和聚合消息。
了解Spark的更多相关文章
- Spark踩坑记——Spark Streaming+Kafka
[TOC] 前言 在WeTest舆情项目中,需要对每天千万级的游戏评论信息进行词频统计,在生产者一端,我们将数据按照每天的拉取时间存入了Kafka当中,而在消费者一端,我们利用了spark strea ...
- Spark RDD 核心总结
摘要: 1.RDD的五大属性 1.1 partitions(分区) 1.2 partitioner(分区方法) 1.3 dependencies(依赖关系) 1.4 compute(获取分区迭代列表) ...
- spark处理大规模语料库统计词汇
最近迷上了spark,写一个专门处理语料库生成词库的项目拿来练练手, github地址:https://github.com/LiuRoy/spark_splitter.代码实现参考wordmaker ...
- Hive on Spark安装配置详解(都是坑啊)
个人主页:http://www.linbingdong.com 简书地址:http://www.jianshu.com/p/a7f75b868568 简介 本文主要记录如何安装配置Hive on Sp ...
- Spark踩坑记——数据库(Hbase+Mysql)
[TOC] 前言 在使用Spark Streaming的过程中对于计算产生结果的进行持久化时,我们往往需要操作数据库,去统计或者改变一些值.最近一个实时消费者处理任务,在使用spark streami ...
- Spark踩坑记——初试
[TOC] Spark简介 整体认识 Apache Spark是一个围绕速度.易用性和复杂分析构建的大数据处理框架.最初在2009年由加州大学伯克利分校的AMPLab开发,并于2010年成为Apach ...
- Spark读写Hbase的二种方式对比
作者:Syn良子 出处:http://www.cnblogs.com/cssdongl 转载请注明出处 一.传统方式 这种方式就是常用的TableInputFormat和TableOutputForm ...
- (资源整理)带你入门Spark
一.Spark简介: 以下是百度百科对Spark的介绍: Spark 是一种与 Hadoop 相似的开源集群计算环境,但是两者之间还存在一些不同之处,这些有用的不同之处使 Spark 在某些工作负载方 ...
- Spark的StandAlone模式原理和安装、Spark-on-YARN的理解
Spark是一个内存迭代式运算框架,通过RDD来描述数据从哪里来,数据用那个算子计算,计算完的数据保存到哪里,RDD之间的依赖关系.他只是一个运算框架,和storm一样只做运算,不做存储. Spark ...
- (一)Spark简介-Java&Python版Spark
Spark简介 视频教程: 1.优酷 2.YouTube 简介: Spark是加州大学伯克利分校AMP实验室,开发的通用内存并行计算框架.Spark在2013年6月进入Apache成为孵化项目,8个月 ...
随机推荐
- float类型数据精度问题:12.0f-11.9f=0.10000038,"减不尽"为什么?
现在我们就详细剖析一下浮点型运算为什么会造成精度丢失? 1.小数的二进制表示问题 首先我们要搞清楚下面两个问题: (1) 十进制整数如何转化为二进制数 算法很简单.举个例子,11表示成二进制数: 1 ...
- Python实战案例系列(一)
本节目录 烟草扫码数据统计 奖学金统计 实战一.烟草扫码数据统计 1. 需求分析 根据扫码信息在数据库文件中匹配相应规格详细信息,并进行个数统计 条码库.xls 扫码.xlsx 一个条码对应多个规格名 ...
- [转]浮点运算decimal.js
开发过程中免不了有浮点运算,JavaScript浮点运算的精度问题会带来一些困扰 JavaScript 只有一种数字类型 ( Number ) JavaScript采用 IEEE 754 标准双精度浮 ...
- [BZOJ2761] [JLOI2011] 不重复数字 (C++ STL - set)
不重复数字 题目: 给出N个数,要求把其中重复的去掉,只保留第一次出现的数.例如,给出的数 为1 2 18 3 3 19 2 3 6 5 4,其中2和3有重复,去除后的结果为1 2 1 ...
- 听说你想在 WordPress 网站上嵌入 PPT ?
年底了,想在 WordPress 博客上展示自己的春节旅行计划,尝试在文章中插入一个旅行计划 PPT 结果长这个样子 你有没有遇到同样的情况,懊恼网页支持展示的内容无法满足我们的需求: 想展示年度家庭 ...
- Java 将PDF转为PDF/A
通过将PDF格式转换为PDF/A格式,可保护文档布局.格式.字体.大小等不受更改,从而实现文档安全保护的目的,同时又能保证文档可读.可访问.本篇文章,将通过Java后端程序代码展示如何将PDF转为符合 ...
- day4 对偶数、偶数位的操作
1.函数fun()的功能:从低位开始取出整形变量s中偶数位上的数,依次构成一个新数放在t中.高位仍在高位. 效果理想:但是经测试的时候出现了错误 输入987654321时,打印出来的却是18681.经 ...
- Android学习笔记2
4,用intent在activity之间传递数据(两个Activity可能不是在一个应用程序中) (1),从MainActivity向HelloActivity传递参数123 package com. ...
- windows10双系统删除linux
问题 在这里删除后会发现有残留一个引导区,几百m(下图已经删除完),而且启动会进linux引导,然后必须f12进入选择启动项才可以启动windows 解决方法 使用删除引导就可以了 再使用傲梅分区助手 ...
- 读书笔记http之第一章
http TCP/IP协议各层: 应用层 决定了向用户提供应用服务时通信的活动. 比如 : FTP(FileTransferProtocol,文件传输协议)和DNS(DomainNameSystem, ...