了解Spark
Apache Spark是一个开源的集群计算框架,主要用来处理实时生成的数据。
Spark是建立在Hadoop的MapReduce顶部。它被优化到了内存中运行,而MapReduce等替代方法是将数据写入硬盘或从硬盘中写入数据,因此,Spark比其它替代方法运行速度更快。
Apache Spark的特点:
- 快速——Spark使用的是DAG(有向无环图)调度程序,为批处理和流数据提供高性能;
- 易于使用——它有助于使用Java、Scala、Python以及R和SQL编写应用程序,还提供了80多个运算符。
- 通用性——它提供了一系列的库,包含SQL、DataFrame以及用于机器学习的MLlib、GraphX和Spark Streaming。
- 轻量级——它是一个轻型统一分析执行引擎,用于大规模的数据处理;
- 无处不在——它可以轻松运行在Hadoop、Apach Mesos、Kubernetes或独立云端。
Spark的应用:
- 数据集成——系统生成的数据不够整合,无法进行结合分析,Spark可以减少提取、转换、加载(数据仓库ETL技术)等过程的成本和时间;
- 流处理——处理实时生成的数据总是很困难(如日志文件),Spark可以运行流数据并拒绝潜在的欺诈性操作;
- 机器学习——Spark可以将数据存贮在内存中并且可以快速运行重复的查询,因此可以轻松处理机器学习算法;
- 交互式分析——Spark可以快速生成相应,因此可以交互式处理数据,而非运行预定义的查询。
Spark架构:
- Spark遵循主从架构,它的集群有一个主服务器和多个从服务器组成;
- Spark架构依赖于两个抽象:弹性分布式数据集(RDD);有向无环图(DAG);
弹性分布式数据集(RDD):可以存储在工作节点上内存的数据组项。
- 弹性——失败时可以恢复数据;
- 分布式——数据分布在不同的节点之间;
- 数据集——数据组。
- DAG中每个节点Node都是RDD分区。
Spark架构图:
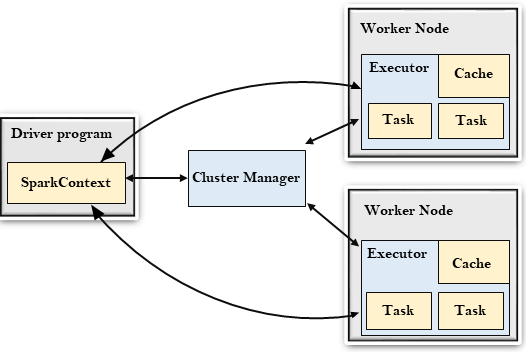
Driver Progarm:
- 驱动程序是一个运行应用程序,由
main()函数启动并创建SparkContext对象的进程。SparkContext的目的是协调spark应用程序,作为集群上的独立进程运行。要在群集上运行,SparkContext将连接到不同类型的群集管理器,然后执行以下任务:- 在集群的节点上获取执行程序;
- 将应用程序的代码发送给执行程序;
- 将任务发送给执行程序并运行。
Cluster Manager:
- 主要作用是跨应用程序分配资源;
- Spark能够在大量的集群上运行,它是由各种类型的集群管理器组成(例如:Hadoop Yarn、Apach Mesos、Standalone等);
Work Node:
- 工作节点是Spark的从节点;
- 它的作用是在集群中运行应用程序代码。
Executor:
- 执行程序是为工作节点上应用程序启动的进程;
- 它运行任务并将数据保存在内存或磁盘中;
- 将数据读写到外部源;
- 每个应用程序都包含其执行者。
Task:
- 任务是被发送给一个执行程序的工作单位。
Spark 组件:
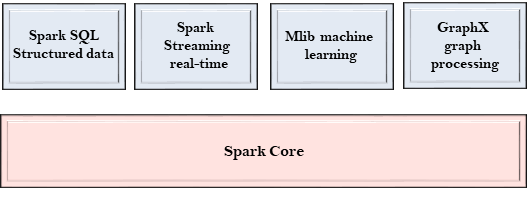
Spark 是一个计算引擎,可以组织、分发和监控多个应用程序,由不同的组件紧密集成。
Spark Core:
- Spark的核心,用来执行核心功能;
- 包含任务调度,故障恢复,与存储系统和内存管理交互的组件。
Spark SQL:
- 它构建于Spark core之上,为结构化数据提供支持;
- 它允许通过SQL(结构化查询语言)以及Hive查询数据;
- 它支持JDBC和ODBC连接,用于连接建立Java对象与现有数据库、数据仓库、商业智能工具之间的连接;
- 支持各种数据源,如Hive表、Parquet和Json
Spark Streaming:
- 用来支持流数据的可伸缩和容错处理;
- 它可以使用Spark Core的快速调度功能来执行流分析;
- 接受小批量数据并对数据执行RDD转换;
- 它的设计确保流数据编写的应用程序可以重复使用,只需要很少的修改即可分析批量的历史数据;
- Web服务器生成的日志文件可以视为流数据的实时示例,
MLib:
- 它是一个机器学习库,包含各种机器学习算法;
- 包含相关性和假设检验,分类、回归、聚类和主成分分析;
- 它比Apach Mahout使用的基于磁盘的实现快9倍。
GraphX:
- 它是一个用于操作图形和执行图形并行计算的库;
- 有助于创建一个有向图,可以任意属性附加到每个顶点和边;
- 要操纵图形,它支持各种基本运算符,如子图、连接顶点和聚合消息。
了解Spark的更多相关文章
- Spark踩坑记——Spark Streaming+Kafka
[TOC] 前言 在WeTest舆情项目中,需要对每天千万级的游戏评论信息进行词频统计,在生产者一端,我们将数据按照每天的拉取时间存入了Kafka当中,而在消费者一端,我们利用了spark strea ...
- Spark RDD 核心总结
摘要: 1.RDD的五大属性 1.1 partitions(分区) 1.2 partitioner(分区方法) 1.3 dependencies(依赖关系) 1.4 compute(获取分区迭代列表) ...
- spark处理大规模语料库统计词汇
最近迷上了spark,写一个专门处理语料库生成词库的项目拿来练练手, github地址:https://github.com/LiuRoy/spark_splitter.代码实现参考wordmaker ...
- Hive on Spark安装配置详解(都是坑啊)
个人主页:http://www.linbingdong.com 简书地址:http://www.jianshu.com/p/a7f75b868568 简介 本文主要记录如何安装配置Hive on Sp ...
- Spark踩坑记——数据库(Hbase+Mysql)
[TOC] 前言 在使用Spark Streaming的过程中对于计算产生结果的进行持久化时,我们往往需要操作数据库,去统计或者改变一些值.最近一个实时消费者处理任务,在使用spark streami ...
- Spark踩坑记——初试
[TOC] Spark简介 整体认识 Apache Spark是一个围绕速度.易用性和复杂分析构建的大数据处理框架.最初在2009年由加州大学伯克利分校的AMPLab开发,并于2010年成为Apach ...
- Spark读写Hbase的二种方式对比
作者:Syn良子 出处:http://www.cnblogs.com/cssdongl 转载请注明出处 一.传统方式 这种方式就是常用的TableInputFormat和TableOutputForm ...
- (资源整理)带你入门Spark
一.Spark简介: 以下是百度百科对Spark的介绍: Spark 是一种与 Hadoop 相似的开源集群计算环境,但是两者之间还存在一些不同之处,这些有用的不同之处使 Spark 在某些工作负载方 ...
- Spark的StandAlone模式原理和安装、Spark-on-YARN的理解
Spark是一个内存迭代式运算框架,通过RDD来描述数据从哪里来,数据用那个算子计算,计算完的数据保存到哪里,RDD之间的依赖关系.他只是一个运算框架,和storm一样只做运算,不做存储. Spark ...
- (一)Spark简介-Java&Python版Spark
Spark简介 视频教程: 1.优酷 2.YouTube 简介: Spark是加州大学伯克利分校AMP实验室,开发的通用内存并行计算框架.Spark在2013年6月进入Apache成为孵化项目,8个月 ...
随机推荐
- 『无为则无心』Python函数 — 31、命名空间(namespace)
目录 1.什么是命名空间 2.三种命名空间 3.命名空间查找顺序 4.命名空间的生命周期 5.如何获取当前的命名空间 1.什么是命名空间 命名空间指的是变量存储的位置,每一个变量都需要存储到指定的命名 ...
- 怎样用命令行导入注册表 .reg 文件
https://stackoverflow.com/questions/49676660/how-to-run-the-reg-file-using-powershell Get-Command re ...
- js字符串数组['1','2','3']转number
let arr = ['1','2','3']; arr.split(',').map(Number);
- js页面触发chargeRequest事件和Nginx获取日志信息
注:图片如果损坏,点击文章链接:https://www.toutiao.com/i6814836302966424072/ 承接上一篇文档<js页面触发pageView和event事件编写> ...
- mybatis关联查询基础----高级映射
本文链接地址:mybatis关联查询基础----高级映射(一对一,一对多,多对多) 前言: 今日在工作中遇到了一个一对多分页查询的问题,主表一条记录对应关联表四条记录,关联分页查询后每页只显示三条记录 ...
- k8s中kubeconfig的配置及使用
1.概述 kubeconfig文件保存了k8s集群的集群.用户.命名空间.认证的信息.kubectl命令使用kubeconfig文件来获取集群的信息,然后和API server进行通讯. 注意:用于配 ...
- manjora20不小心卸载,重新安装terminal,软件商店/软件中心linux类似
问题 重新安装老版本gnome-shell 如果突然死机可能卸载完了terminal和软件商店,但是没有安装新的. 此时没有terminal也没有软件商店 无法安装软件 解决方案 terminal c ...
- manjaro20默认关闭蓝牙
用于节电. https://gist.github.com/0xfe11/d0874b7d31cf649616fa9d816571ab3c 推荐执行 # Stop and disable the bl ...
- 数据库DDL、DML、DCL、DQL、DPL、CCL的全称和使用
数据库DDL.DML.DCL.DQL.DPL.CCL的全称和使用 简介: SQL (Structure Query Language):结构化查询语言,一种特殊目的的编程语言,一种数据库查询和程序设计 ...
- spring拦截机制中Filter(过滤器)、interceptor(拦截器)和Aspect(切面)的使用及区别
Spring中的拦截机制,如果出现异常的话,异常的顺序是从里面到外面一步一步的进行处理,如果到了最外层都没有进行处理的话,就会由tomcat容器抛出异常. 1.过滤器:Filter :可以获得Http ...