WebSocket 反爬虫
WebSocket握手验证反爬虫
!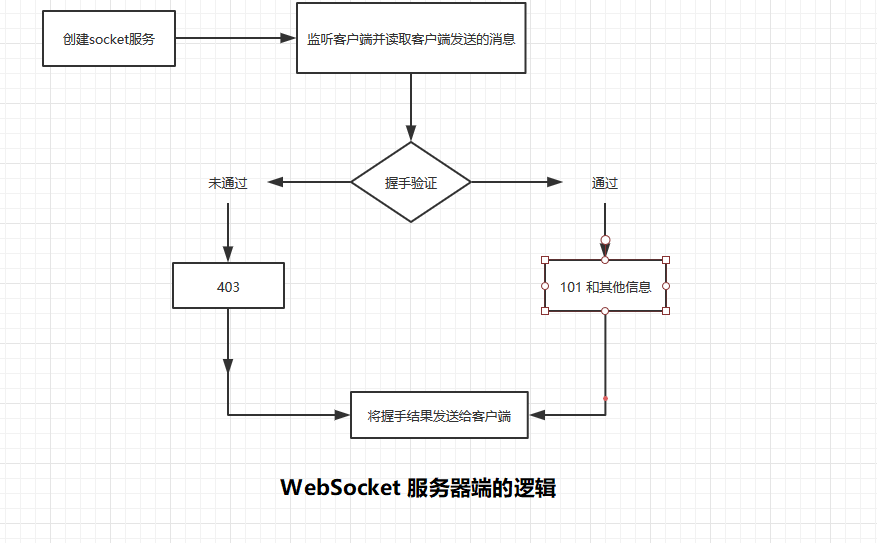
服务器端创建 socket 服务后监听客户端,使用 while True 的方式读取客户端发送的消息
然后对服务器端发送的握手请求进验证,如果验证通过,则返回状态码为 101 的响应头,否则返回状态码为 403 的响应头
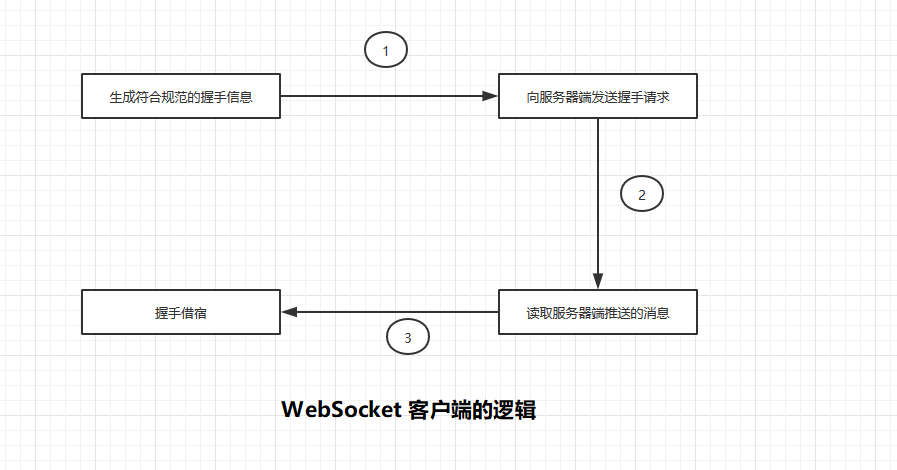
客户端按照 WebSocket 规范生成握手信息并向服务器端发送握手请求,然后读取服务器端推送的消息,最后验证握手信息
服务器端和客户端实际上可以不遵守这些约定
比如服务器可以在校验握手信息是增加对客户端 User-Agent 或 Referer (请求头)的验证,如果客户端发送的握手请求中并没有对应的信息,则拒绝连接
WebSocket 消息校验反爬虫
握手成功之后,双端就可以开始互推消息了
WebSocket 只需要完成 1 次握手,就可以保持长期连接,在后续的消息互发阶段是不需要用到 HTTP 协议的
其实消息互发阶段也是可以对客户端身份进行校验的,这是因为客户端所获取的消息是有服务器端主动推动的
如果服务器端不主动推送,那么客户端就无法获取信息
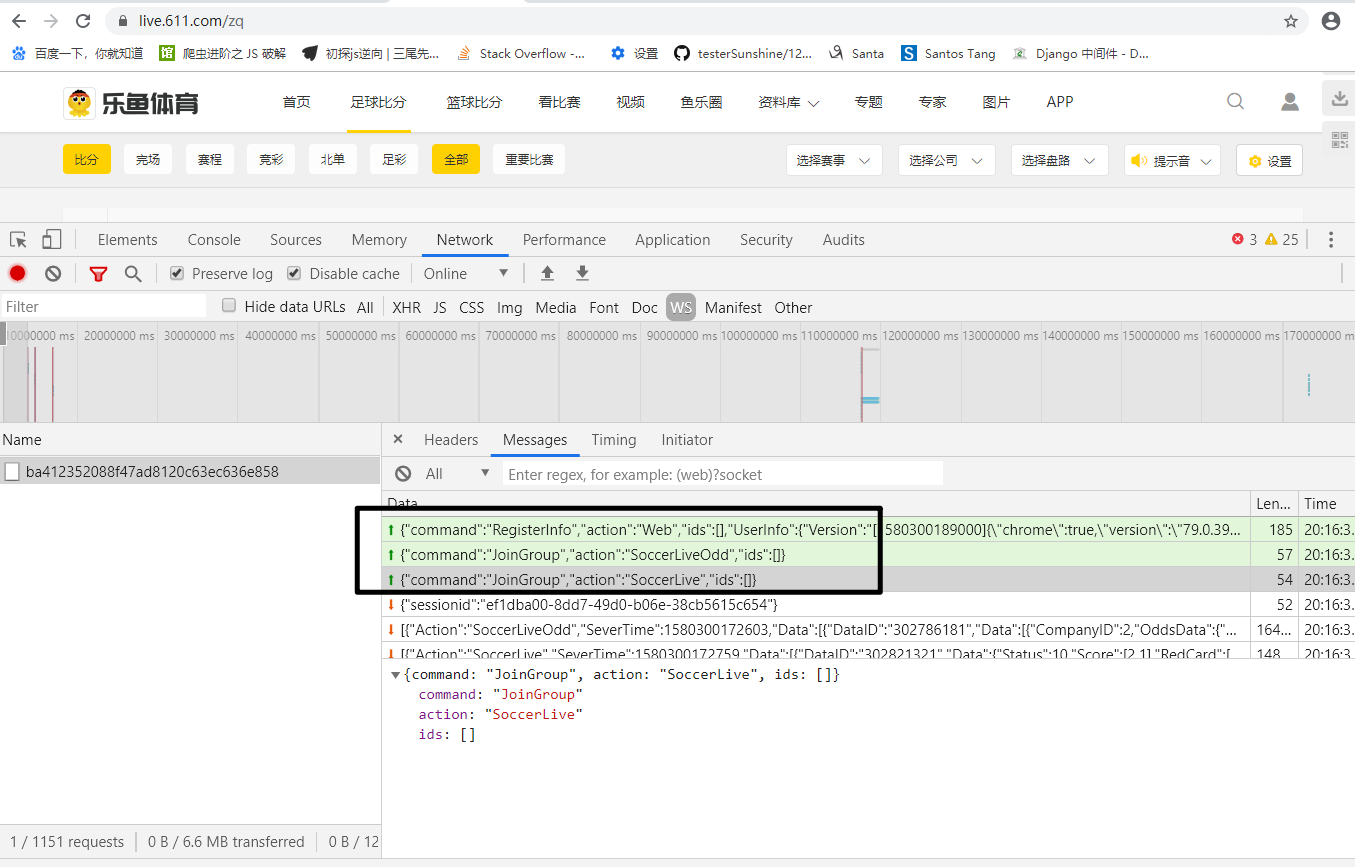
可以在服务器端新增一个逻辑:握手结束后客户端发送特定的消息,服务器端对该消息进行校验,校验通过则将服务器端的数据推送给客户端,否则不做处理
如果我们将客户端发送的新消息修改为数据仓库中没有的键,那么服务器端就不会给客户端推送消息
WebSocket Ping 反爬虫
通过刚才我们知道,WebSocket 是可以保持长期连接的,但是服务器端不可能保持所有客户端永久连接这太耗费资源了,
有没有一种方法可以检查客户端的状态呢?
WebSocket 协议规范中约定,服务器端可以向客户端发送 Ping 帧,当客户端收到 Ping 帧时应当回复 Pong 帧
如果客户端不回复或者回复的并不是 Pong 帧,那么服务器端就可以人为客户端异常,主动关闭该连接
通常,Ping 帧和 Pong 帧的 Plyload Data 中是没有内容的,所以只要目标服务器发送 Ping 帧时,客户端回复没有任何内容的 Pong 帧即可
总结
信息校验主要解决了客户端身份鉴别、数据来源判断和请求的合法性判断等问题,避免数据接收者使用被篡改过得数据,保证数据的有效性
无论是 HTTP 协议还是 WebSocket 协议,都需要对客户端身份进行鉴别,信息校验无疑是最合适的方法
WebSocket 反爬虫的产生跟协议规范有很大的关联,由于协议中的一些规范并不是强制实现的,所以开发者可以在服务器端与客户端握手和消息互传的过程叫做验证
WebSocket 反爬虫的更多相关文章
- 配置Nutch模拟浏览器以绕过反爬虫限制
原文链接:http://yangshangchuan.iteye.com/blog/2030741 当我们配置Nutch抓取 http://yangshangchuan.iteye.com 的时候,抓 ...
- 自动更改IP地址反爬虫封锁,支持多线程(转)
8年多爬虫经验的人告诉你,国内ADSL是王道,多申请些线路,分布在多个不同的电信机房,能跨省跨市更好,我这里写好的断线重拨组件,你可以直接使用. ADSL拨号上网使用动态IP地址,每一次拨号得到的IP ...
- crawler_爬虫_反爬虫策略
关于反爬虫和恶意攻击的一些策略和思路 有时网站经常受到恶意spider攻击,疯狂抓取网站内容,对网站性能有较大影响. 下面我说说一些反恶意spider和spam的策略和思路. 1. 通过日志分析来 ...
- Python爬虫从入门到放弃(二十二)之 爬虫与反爬虫大战
爬虫与发爬虫的厮杀,一方为了拿到数据,一方为了防止爬虫拿到数据,谁是最后的赢家? 重新理解爬虫中的一些概念 爬虫:自动获取网站数据的程序反爬虫:使用技术手段防止爬虫程序爬取数据误伤:反爬虫技术将普通用 ...
- 爬取豆瓣电影储存到数据库MONGDB中以及反反爬虫
1.代码如下: doubanmoive.py # -*- coding: utf-8 -*- import scrapy from douban.items import DoubanItem cla ...
- 爬虫_vs_反爬虫
爬虫中有哪些专业术语? 爬虫:自动获取网站数据的程序,关键是批量的获取 反爬虫:使用技术手段防止爬虫程序的方法 误伤:反爬虫技术将普通用户识别为爬虫,效果再好也不能用(禁止ip) 成本:反爬虫需要人力 ...
- 反反爬虫 IP代理
0x01 前言 一般而言,抓取稍微正规一点的网站,都会有反爬虫的制约.反爬虫主要有以下几种方式: 通过UA判断.这是最低级的判断,一般反爬虫不会用这个做唯一判断,因为反反爬虫非常容易,直接随机UA即可 ...
- 爬虫(Spider),反爬虫(Anti-Spider),反反爬虫(Anti-Anti-Spider)
爬虫(Spider),反爬虫(Anti-Spider),反反爬虫(Anti-Anti-Spider),这之间的斗争恢宏壮阔... Day 1小莫想要某站上所有的电影,写了标准的爬虫(基于HttpCli ...
- 爬虫实践---悦音台mv排行榜与简单反爬虫技术应用
由于要抓取的是悦音台mv的排行榜,这个排行榜是实时更新的,如果要求不停地抓取,这将有可能导致悦音台官方采用反爬虫的技术将ip给封掉.所以这里要应用一些反爬虫相关知识. 目标网址:http://vcha ...
随机推荐
- disconf---分布式配置管理平台的搭建(windows版本)
本人由刚开始接触博客,难免会有不足和错误,写博客只是记录本人在学习和工作的过程中的成长,如有不足,欢迎各位指正,谢谢~ 一.废话不多说,直接进入正题: ①获取github代码 https://gith ...
- python练习:编写一个函数isIn,接受两个字符串作为参数,如果一个字符串是另一个字符串的一部分,返回True,否则返回False。
python练习:编写一个函数isIn,接受两个字符串作为参数,如果一个字符串是另一个字符串的一部分,返回True,否则返回False. 重难点:定义函数的方法.使用str类型的find()函数,可以 ...
- Centos610 Oracle 监听文件配置参考
lister.ora配置参考 # listener.ora Network Configuration File: /home/oracle/app/oracle/product//dbhome_1/ ...
- 使用SQL计算宝宝每次吃奶的时间间隔(数据保障篇)
目前程序从功能上其实已经完全满足客户(当然我这里的客户都是指媳妇儿^_^)需求,具体可参考: 使用SQL计算宝宝每次吃奶的时间间隔 使用SQL计算宝宝每次吃奶的时间间隔(续) 那么本篇 使用SQL计算 ...
- 喵星之旅-狂奔的兔子-基于docker的redis分布式集群
一.docker安装(略) 二.下载redis安装包(redis-4.0.8.tar.gz) 以任何方式获取都可以.自行官网下载. 三.拉取centos7的docker镜像 命令:docker pul ...
- duv中内容不换行的解决办法
<div style='width: 100px;display:block;word-break: break-all;word-wrap: break-word;'> 内容超出div宽 ...
- Maven中配置jdk的版本
在单个项目中配置 在maven项目的pom.xml文件中加入以下内容 <build> <plugins> <plugin> <groupId>org.a ...
- 【代码总结】MYSQL数据库的常见操作
============================== MYSQL数据库的常见操作 ============================== 一.mysql的连接与关闭 -h:指定所连接的服 ...
- logback.xml设置mogodb日志打印控制台
<logger name="org.springframework.data.mongodb.core" level="DEBUG"/>
- ENTRYPOINT与CMD/实现切换用户执行
1.CMD 最终会被解析成:["cmd","arg1","arg2"] 可以在运行时被覆盖 2.ENTRYPOINT 最终解析成 [&quo ...