使用 CUBLAS 库给矩阵运算提速
前言
编写 CUDA 程序真心不是个简单的事儿,调试也不方便,很费时。那么有没有一些现成的 CUDA 库来调用呢?
答案是有的,如 CUBLAS 就是 CUDA 专门用来解决线性代数运算的库。
本文将大致介绍如何使用 CUBLAS 库,同时演示一个使用 CUBLAS 库进行矩阵乘法的例子。
CUBLAS 内容
CUBLAS 是 CUDA 专门用来解决线性代数运算的库,它分为三个级别:
Lev1. 向量相乘
Lev2. 矩阵乘向量
Lev3. 矩阵乘矩阵
同时该库还包含状态结构和一些功能函数。
CUBLAS 用法
大体分成以下几个步骤:
1. 定义 CUBLAS 库对象
2. 在显存中为待运算的数据以及需要存放结果的变量开辟显存空间。( cudaMalloc 函数实现 )
3. 将待运算的数据传输进显存。( cudaMemcpy,cublasSetVector 等函数实现 )
3. 调用 CUBLAS 库函数 ( 根据 CUBLAS 手册调用需要的函数 )
4. 从显存中获取结果变量。( cudaMemcpy,cublasGetVector 等函数实现 )
5. 释放申请的显存空间以及 CUBLAS 库对象。( cudaFree 及 cublasDestroy 函数实现 )
代码示例
如下程序使用 CUBLAS 库进行矩阵乘法运算,请仔细阅读注释,尤其是 API 的参数说明:
// CUDA runtime 库 + CUBLAS 库
#include "cuda_runtime.h"
#include "cublas_v2.h" #include <time.h>
#include <iostream> using namespace std; // 定义测试矩阵的维度
int const M = ;
int const N = ; int main()
{
// 定义状态变量
cublasStatus_t status; // 在 内存 中为将要计算的矩阵开辟空间
float *h_A = (float*)malloc (N*M*sizeof(float));
float *h_B = (float*)malloc (N*M*sizeof(float)); // 在 内存 中为将要存放运算结果的矩阵开辟空间
float *h_C = (float*)malloc (M*M*sizeof(float)); // 为待运算矩阵的元素赋予 0-10 范围内的随机数
for (int i=; i<N*M; i++) {
h_A[i] = (float)(rand()%+);
h_B[i] = (float)(rand()%+); } // 打印待测试的矩阵
cout << "矩阵 A :" << endl;
for (int i=; i<N*M; i++){
cout << h_A[i] << " ";
if ((i+)%N == ) cout << endl;
}
cout << endl;
cout << "矩阵 B :" << endl;
for (int i=; i<N*M; i++){
cout << h_B[i] << " ";
if ((i+)%M == ) cout << endl;
}
cout << endl; /*
** GPU 计算矩阵相乘
*/ // 创建并初始化 CUBLAS 库对象
cublasHandle_t handle;
status = cublasCreate(&handle); if (status != CUBLAS_STATUS_SUCCESS)
{
if (status == CUBLAS_STATUS_NOT_INITIALIZED) {
cout << "CUBLAS 对象实例化出错" << endl;
}
getchar ();
return EXIT_FAILURE;
} float *d_A, *d_B, *d_C;
// 在 显存 中为将要计算的矩阵开辟空间
cudaMalloc (
(void**)&d_A, // 指向开辟的空间的指针
N*M * sizeof(float) // 需要开辟空间的字节数
);
cudaMalloc (
(void**)&d_B,
N*M * sizeof(float)
); // 在 显存 中为将要存放运算结果的矩阵开辟空间
cudaMalloc (
(void**)&d_C,
M*M * sizeof(float)
); // 将矩阵数据传递进 显存 中已经开辟好了的空间
cublasSetVector (
N*M, // 要存入显存的元素个数
sizeof(float), // 每个元素大小
h_A, // 主机端起始地址
, // 连续元素之间的存储间隔
d_A, // GPU 端起始地址
// 连续元素之间的存储间隔
);
cublasSetVector (
N*M,
sizeof(float),
h_B,
,
d_B, ); // 同步函数
cudaThreadSynchronize(); // 传递进矩阵相乘函数中的参数,具体含义请参考函数手册。
float a=; float b=;
// 矩阵相乘。该函数必然将数组解析成列优先数组
cublasSgemm (
handle, // blas 库对象
CUBLAS_OP_T, // 矩阵 A 属性参数
CUBLAS_OP_T, // 矩阵 B 属性参数
M, // A, C 的行数
M, // B, C 的列数
N, // A 的列数和 B 的行数
&a, // 运算式的 α 值
d_A, // A 在显存中的地址
N, // lda
d_B, // B 在显存中的地址
M, // ldb
&b, // 运算式的 β 值
d_C, // C 在显存中的地址(结果矩阵)
M // ldc
); // 同步函数
cudaThreadSynchronize(); // 从 显存 中取出运算结果至 内存中去
cublasGetVector (
M*M, // 要取出元素的个数
sizeof(float), // 每个元素大小
d_C, // GPU 端起始地址
, // 连续元素之间的存储间隔
h_C, // 主机端起始地址
// 连续元素之间的存储间隔
); // 打印运算结果
cout << "计算结果的转置 ( (A*B)的转置 ):" << endl; for (int i=;i<M*M; i++){
cout << h_C[i] << " ";
if ((i+)%M == ) cout << endl;
} // 清理掉使用过的内存
free (h_A);
free (h_B);
free (h_C);
cudaFree (d_A);
cudaFree (d_B);
cudaFree (d_C); // 释放 CUBLAS 库对象
cublasDestroy (handle); getchar(); return ;
}
运行测试
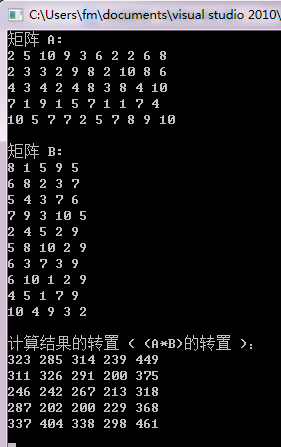
PS:矩阵元素是随机生成的
小结
1. 使用 CUDA 库固然方便,但也要仔细的参阅函数手册,其中每个参数的含义都要很清晰才不容易出错。
2. 如果程序仅使用 CUDA 库的话,用 .cpp 源码文件即可 (不用 .cu)
使用 CUBLAS 库给矩阵运算提速的更多相关文章
- 第四篇:使用 CUBLAS 库给矩阵运算提速
前言 编写 CUDA 程序真心不是个简单的事儿,调试也不方便,很费时.那么有没有一些现成的 CUDA 库来调用呢? 答案是有的,如 CUBLAS 就是 CUDA 专门用来解决线性代数运算的库. 本文将 ...
- [Python学习] python 科学计算库NumPy—矩阵运算
NumPy库的核心是矩阵及其运算. 使用array()函数可以将python的array_like数据转变成数组形式,使用matrix()函数转变成矩阵形式. 基于习惯,在实际使用中较常用array而 ...
- cuda中用cublas库做矩阵乘法
这里矩阵C=A*B,原始文档给的公式是C=alpha*A*B+beta*C,所以这里alpha=1,beta=0. 主要使用cublasSgemm这个函数,这个函数的第二个参数有三种类型,这里CUBL ...
- cublas相关的知识
下面链接给出了一个例子,怎么用cublas进行矩阵的运算提速,也说明了cublas的大致的使用方法. http://www.cnblogs.com/scut-fm/p/3756242.html cub ...
- python中的矩阵运算
摘自:http://m.blog.csdn.net/blog/taxueguilai1992/46581861 python的numpy库提供矩阵运算的功能,因此我们在需要矩阵运算的时候,需要导入nu ...
- 有关CUBLAS中的矩阵乘法函数
关于cuBLAS库中矩阵乘法相关的函数及其输入输出进行详细讨论. ▶ 涨姿势: ● cuBLAS中能用于运算矩阵乘法的函数有4个,分别是 cublasSgemm(单精度实数).cublasDgemm( ...
- python 常见矩阵运算
python 的 numpy 库提供矩阵运算的功能,因此我们在需要矩阵运算的时候,需要导入 numpy 的包. 1.numpy 的导入和使用 from numpy import *;#导入numpy的 ...
- Cublas矩阵加速运算
前言 编写 CUDA 程序真心不是个简单的事儿,调试也不方便,很费时.那么有没有一些现成的 CUDA 库来调用呢? 答案是有的,如 CUBLAS 就是 CUDA 专门用来解决线性代数运算的库. 本文将 ...
- Numba——python面向数组高性能计算库
python在计算性能上相对c是比较弱鸡的,有了numpy后计算性能短板是补了一些,而Numba库又给python计算性能加了发动机(忽然想到西虹市首富王多鱼的名言:我再加200万,给冰山提提速.), ...
随机推荐
- JMETER JDBC操作
本文目标 1.添加测试计划 2.配置JDBC连接 3.插入数据 4.使用控制器 5.查看插入结果 1.添加测试计划 添加mysql驱动 2.添加测试计划 3.添加JDBC连接 在这里JDB ...
- NetworkComms网络通信框架V3结构图
NetworkComms网络通信框架序言 来自英国的c#网络通信框架,历时五年打造,由英国剑桥的2位工程师倾情开发,最新版本V3.x版本.
- MyEclipse8.6 破解以及注册码
建立JAVA工程文件.将以下Java代码拷贝至类中并执行即可. 注册码: register name: bobo9360013 Serial:oLR8ZC-855550-6065705698041 ...
- Android——关于Activity跳转的返回(无返回值和有返回值)——有返回值
说明: 跳转页面,并将第一页的Edittext输入的数据通过按钮Button传到第二页用Edittext显示,点击第二页的 返回按钮Button返回第一页(改变第二页的Edittext的内容会传至第一 ...
- 推荐一款免安装的在线Visio流程工具ProcessOn
昨天收到一人的邮件,说某个软件叫ProcessOn是web版的visio,出于对技术知识的渴望以及自己的好奇所以对ProcessOn进行了一番体验.结果有点被这个软件给吸引上了,无论是在用户体验上,还 ...
- @ModelAttribute注解的作用
@ModelAttribute注解的作用:1.放在方法上注解不带属性: 方法无返回值: 执行其他方法时,先执行该注解标记方法. 如果方法中有将一些属性放入model的操作,其他方法model中也会共享 ...
- Installing Cygwin and Starting the SSH Daemon
This chapter explains how to install Cygwin and start the SSH daemon on Microsoft Windows hosts. Thi ...
- Spring计划会议内容
我们的小组成员是 王伟光,杨世超,苏海岩,曹锦锋,李夏蕾,闫立新. 组长为闫立新. 经过昨天课堂上的讨论,我们确定了未来一周里的工作内容和目标,以及每个人的任务. 我们确定本周的最终目标是实 ...
- python利用or在列表解析中调用多个函数.py
python利用or在列表解析中调用多个函数.py """ python利用or在列表解析中调用多个函数.py 2016年3月15日 05:08:42 codegay & ...
- vi notes
x = wqqq!, quit without save. movej,h,k,l^ or 0: start of line$: end of line:0, start of file:$, end ...