lucene 初探 - 查询
lucene初探, 是为了后面solr做准备的. 如果跳过lucene, 直接去看solr, 估计有点懵.
由于时间的关系, lucene查询方法也有多个, 所以单独出来.
一. 精确查询
/**
* 获取 查找对象
* @return
* @throws Exception
*/
private IndexSearcher getSearcher() throws Exception {
//1. 创建一个directory对象, 也就是索引库存放的位置
Directory directory = FSDirectory.open(new File(indexDir)); //2. 创建一个indexReader对象, 需要指定directory
IndexReader indexReader = DirectoryReader.open(directory); //3. 创建一个indexSearcher对象, 需要指定indexReader对象
IndexSearcher indexSearcher = new IndexSearcher(indexReader); return indexSearcher;
} /**
* 输出信息到控制台
* @param indexSearcher
* @param query
* @throws Exception
*/
public void sout(IndexSearcher indexSearcher, Query query) throws Exception {
//5. 执行查询
TopDocs topDocs = indexSearcher.search(query, 5); //6. 返回查询结果
ScoreDoc[] scoreDocs = topDocs.scoreDocs;
for (ScoreDoc scoreDoc : scoreDocs) {
//获取文档id
int doc = scoreDoc.doc;
//根据文档id获取文档
Document document = indexSearcher.doc(doc);
//文件名字
String fileName = document.get("fileName");
//文件大小
String fileSize = document.get("fileSize");
//文件路径
String filePath = document.get("filePath");
//文件内容
String fileContent = document.get("fileContent"); System.out.println("fileName : " + fileName);
System.out.println("fileSize : " + fileSize);
System.out.println("filePath : " + filePath);
System.out.println("fileContent : " + fileContent);
System.out.println("-----------------------");
}
} /**
* 精确查询
*
* @throws Exception
*/
@Test
public void searchIndex() throws Exception { //1. 获取查询对象
IndexSearcher indexSearcher = getSearcher(); //2. 创建一个TermQuery对象, 指定查询的域和查询的关键词
Query query = new TermQuery(new Term("fileName", "生活")); sout(indexSearcher, query); //3. 关闭IndexReader 对象
indexSearcher.getIndexReader().close();
}
在查询的时候, 新建一个Term对象, 进去精确匹配. 前一篇提到过, 经过分词器分下来的每一个词或者一段话, 就是一个Term.
这里在新建Term的时候, 传入的是 域名 和 要搜索的词.
这里, 一个Term对象, 只有一个域, 那如果我想查询多个域怎么办呢.
二. 组合查询
/**
* 组合查询
*/
@Test
public void queryBoolean() throws Exception {
IndexSearcher searcher = getSearcher(); BooleanQuery query = new BooleanQuery(); Query query1 = new TermQuery(new Term("fileName", "生活"));
Query query2 = new TermQuery(new Term("fileContent", "生活")); query.add(query1, BooleanClause.Occur.MUST);
query.add(query2, BooleanClause.Occur.SHOULD); //System.out.println(query); sout(searcher, query); searcher.getIndexReader().close();
}
这里的Occur枚举值, 有三个, must, should, must_not .
must : 相当于sql里面的 and 连接
should : 相当于 or , 可有可没有
must_not : 相当于 != , 不包含
这里如果打印query, 会显示: +fileName:生活 fileContent:生活
这是lucene的一种语法, lucene可以根据语法来查询数据. 后面会提到. 如果是must_not , 则使用减号.
如: 将上面的query2使用 MUST_NOT 连接, 则显示成: +fileName:生活 -fileContent:生活
三 . 查询所有
一般查询数据库的时候, 都会提供一个 getAll 方法, 用于查询满足条件的所有数据, 当不传条件时, 就查询所有
lucene也提供了一个查询所有的方法 : MatchAllDocsQuery
/**
* 查询所有
*
* @throws Exception
*/
@Test
public void queryAll() throws Exception {
IndexSearcher searcher = getSearcher(); Query query = new MatchAllDocsQuery(); sout(searcher, query); searcher.getIndexReader().close();
}
四. 数值区间查询
/**
* 数值区间查询
*
* @throws Exception
*/
@Test
public void queryNumericRange() throws Exception {
IndexSearcher searcher = getSearcher(); Query query = NumericRangeQuery.newLongRange("fileSize", 10L, 647L, true, true); sout(searcher, query); searcher.getIndexReader().close();
}
这里的语法输出就是 : fileSize:[40 to 647]
这是因为我后面两个都设置为true, 表示包含关系. 如果都设置为false, 就是 {40 to 647}
五. 分词器解析查询
如前面提到的, 我输入一句话查询, 结果展示的结果却并不是按照我输入的全匹配结果.
那是因为在查询之前, 对输入的信息, 进行了分词器解析, 然后根据解析结果, 再去查询数据.
/**
* 条件解析对象查询
*
* @throws Exception
*/
@Test
public void queryParser() throws Exception { IndexSearcher searcher = getSearcher(); QueryParser queryParser = new QueryParser("fileName", new IKAnalyzer()); //Query query = queryParser.parse("*:*");
Query query = queryParser.parse("fileName:这花好漂亮");
//Query query = queryParser.parse("花"); sout(searcher, query); searcher.getIndexReader().close();
}
*:* 表示查询所有. 不管是哪个域.
fileName:这花好漂亮 : 表示在fileName域中, 将 "这花好漂亮" 分词解析后, 进行查询
花 : 在fileName域中, 查询花. 因为在QueryParse创建的时候, 指定了域为 fileName
即使我在QueryParser里面指定了要查询的域, 但是在parse的时候, 我可以重新指定域.
这里需要注意的是, 在上面数值区间查询的时候, 如果我直接写语法进去查询, 是查不出来的. 因为数值类型变了. 通过语法输进去, 变成字符串类型了.
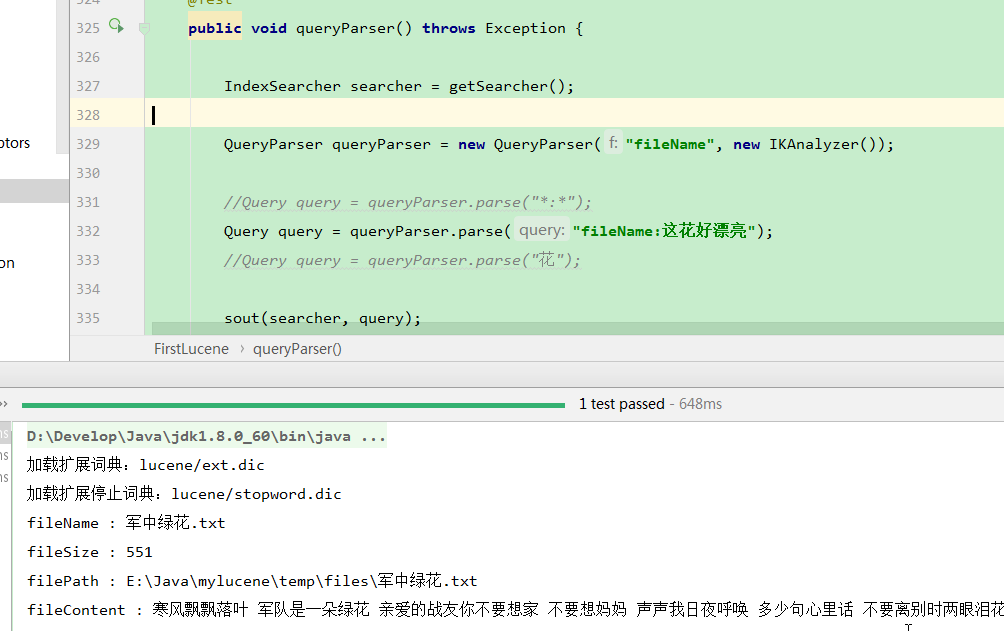
从结果中可以看到, 我输入 这花好漂亮, 查出来的却是 军中绿花. 这就是分词的作用了.
六. 多域分词查询
/**
* 条件解析对象查询
*
* @throws Exception
*/
@Test
public void queryMultiParser() throws Exception { IndexSearcher searcher = getSearcher(); String[] fields = {"fileName", "fileContent"};
MultiFieldQueryParser queryParser = new MultiFieldQueryParser(fields, new IKAnalyzer()); Query query = queryParser.parse("生活大爆炸"); sout(searcher, query); searcher.getIndexReader().close();
}
多域分词查询, 没啥好说的了.
lucene 初探 - 查询的更多相关文章
- lucene 初探
前言: window文件管理右上角, 有个搜索功能, 可以根据文件名进行搜索. 那如果从文件名上判断不出内容, 我岂不是要一个一个的打开文件, 查看文件的内容, 去判断是否是我要的文件? 几个, 十几 ...
- Lucene学习总结之八:Lucene的查询语法,JavaCC及QueryParser
一.Lucene的查询语法 Lucene所支持的查询语法可见http://lucene.apache.org/java/3_0_1/queryparsersyntax.html (1) 语法关键字 + ...
- Hibernate Search集与lucene分词查询
lucene分词查询参考信息:https://blog.csdn.net/dm_vincent/article/details/40707857
- Lucene的查询语法,JavaCC及QueryParser(1)
http://www.cnblogs.com/forfuture1978/archive/2010/05/08/1730200.html 一.Lucene的查询语法 Lucene所支持的查询语法可见h ...
- Lucene学习总结之八:Lucene的查询语法,JavaCC及QueryParser 2014-06-25 14:25 722人阅读 评论(1) 收藏
一.Lucene的查询语法 Lucene所支持的查询语法可见http://lucene.apache.org/java/3_0_1/queryparsersyntax.html (1) 语法关键字 + ...
- 全文检索Lucene框架---查询索引
一. Lucene索引库查询 对要搜索的信息创建Query查询对象,Lucene会根据Query查询对象生成最终的查询语法,类似关系数据库Sql语法一样Lucene也有自己的查询语法,比如:“name ...
- 【手把手教你全文检索】Apache Lucene初探
PS: 苦学一周全文检索,由原来的搜索小白,到初次涉猎,感觉每门技术都博大精深,其中精髓亦是不可一日而语.那小博猪就简单介绍一下这一周的学习历程,仅供各位程序猿们参考,这其中不涉及任何私密话题,因此也 ...
- [转载] Apache Lucene初探
转载自http://www.cnblogs.com/xing901022/p/3933675.html 讲解之前,先来分享一些资料 首先呢,学习任何一门新的亦或是旧的开源技术,百度其中一二是最简单的办 ...
- 【手把手教你全文检索】Apache Lucene初探 (zhuan)
http://www.cnblogs.com/xing901022/p/3933675.html *************************************************** ...
随机推荐
- MVC框架-.net-摘
MVC模式(三层架构模式)(Model-View-Controller)是软件工程中的一种软件架构模式,把软件系统分为三个基本部分:模型(Model).视图(View)和控制器(Controller) ...
- springboot工程读取配置文件application.yml的写法18045
现在流行springboot框架的项目,里面的默认配置文件为application.yml,我们怎样读取这个配置文件呢? 先贴上我得配置文件吧 目录结构 里面内容 1 写读取配置文件的工具类 @Con ...
- hibernate之三种时态之间的转换
判断状态的标准 oid 和 session相关性 public class HibernateUtils { private static SessionFactory sessionFact ...
- 发邮件、排序、FIFO
发送邮件.py: import smtplib from email.mime.text import MIMEText def email(receiver, title='标题', b ...
- bootstrap1.1
<!DOCTYPE html> <html> <head> <meta charset="utf-8" /> < ...
- Android-Kotlin简单计算器功能
上一篇博客 Android-Kotlin-配置/入门 配置好了 AndroidStudio Kotlin 的环境: 选择包名,然后右键: 选择Class类型,会有class: 创建CounterCla ...
- Android-Java多线程通讯(生产者 消费者)&10条线程对-等待唤醒/机制的管理
上一篇博客 Android-Java多线程通讯(生产者 消费者)&等待唤醒机制 是两条线程(Thread-0 / Thread-1) 在被CPU随机切换执行: 而今天这篇博客是,在上一篇博客A ...
- ASP.NET Forms 认证流程
ASP.NET Forms 认证 Forms认证基础 HTTP是无状态的协议,也就是说用户的每次请求对服务器来说都是一次全新的请求,服务器不能识别这个请求是哪个用户发送的. 那服务器如何去判断一个用户 ...
- [leetcode.com]算法题目 - Remove Duplicates from Sorted List
Given a sorted linked list, delete all duplicates such that each element appear only once. For examp ...
- Lerning Entity Framework 6 ------ Defining the Database Structure
There are three ways to define the database structure by Entity Framework API. They are: Attributes ...