Python-爬虫-租房Ziroom
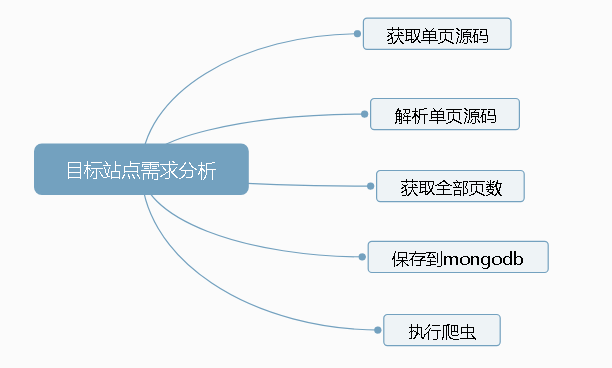
目标站点需求分析
涉及的库
import requests
import time
import pymongo
from lxml import etree
from requests.exceptions import RequestException
获取单页源码
def get_one_page(page):
'''获取单页源码'''
try:
url = "http://sh.ziroom.com/z/nl/z2.html?p=" + str(page)
print('url',url)
headers = {
'Referer':'http://sh.ziroom.com/',
'User-Agent':'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3538.77 Safari/537.36'
}
res = requests.get(url,headers=headers)
time.sleep(1)
if res.status_code == 200:
return res.text
return None
except RequestException:
return None
解析单页源码
def parse_one_page(sourcehtml):
'''解析单页源码'''
contentTree = etree.HTML(sourcehtml) #解析源代码
results = contentTree.xpath('//ul[@id="houseList"]/li') #利用XPath提取相应内容
for result in results:
title = result.xpath("./div/h3/a/text()")[0][5:] if len(result.xpath("./div/h3/a/text()")[0]) > 0 else ""
area = " ".join(result.xpath("./div/div/p[1]/span/text()")).replace(" ", "", 1) # 使用join方法将列表中的内容以" "字符连接
nearby = result.xpath("./div/div/p[2]/span/text()")[0].strip() if len(result.xpath("./div/div/p[2]/span/text()"))>0 else ""
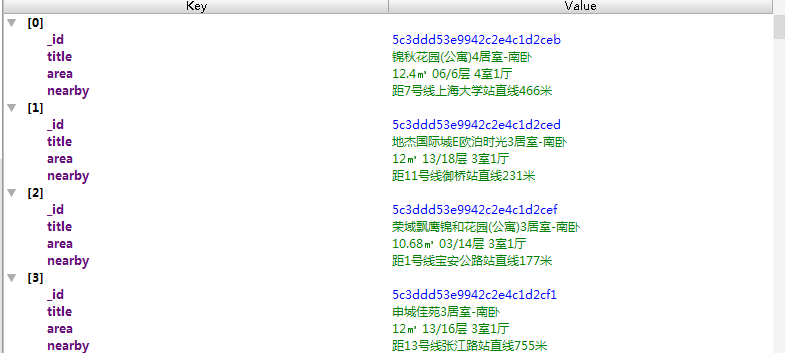
data = {
"title": title,
"area": area,
"nearby": nearby
}
print(data)
save_to_mongodb(data)
抓取总页数,保存到Mongobd中
def get_pages():
"""得到总页数"""
page = 1
html = get_one_page(page)
contentTree = etree.HTML(html)
pages = int(contentTree.xpath('//div[@class="pages"]/span[2]/text()')[0].strip("共页"))
return pages def save_to_mongodb(result):
"""存储到MongoDB中"""
# 创建数据库连接对象, 即连接到本地
client = pymongo.MongoClient(host="localhost")
# 指定数据库,这里指定ziroom和表名
db = client.iroomz
db_table = db.roominfo
try:
#插入到数据库
if db_table.insert(result):
print("抓取成功",result)
except Exception as reason:
print("抓取失败",reason)
def task():
pages = get_pages()
print('总共',pages)
for page in range(1,int(pages)+1):
html = get_one_page(page)
parse_one_page(html)
Python-爬虫-租房Ziroom的更多相关文章
- python 爬虫入门----案例爬取上海租房图片
前言 对于一个net开发这爬虫真真的以前没有写过.这段时间学习python爬虫,今天周末无聊写了一段代码爬取上海租房图片,其实很简短就是利用爬虫的第三方库Requests与BeautifulSoup. ...
- python爬虫项目(scrapy-redis分布式爬取房天下租房信息)
python爬虫scrapy项目(二) 爬取目标:房天下全国租房信息网站(起始url:http://zu.fang.com/cities.aspx) 爬取内容:城市:名字:出租方式:价格:户型:面积: ...
- python 爬虫入门案例----爬取某站上海租房图片
前言 对于一个net开发这爬虫真真的以前没有写过.这段时间开始学习python爬虫,今天周末无聊写了一段代码爬取上海租房图片,其实很简短就是利用爬虫的第三方库Requests与BeautifulSou ...
- Python爬虫(四)——开封市58同城数据模型训练与检测
前文参考: Python爬虫(一)——开封市58同城租房信息 Python爬虫(二)——对开封市58同城出租房数据进行分析 Python爬虫(三)——对豆瓣图书各模块评论数与评分图形化分析 数据的构建 ...
- Python爬虫之PyQuery使用(六)
Python爬虫之PyQuery使用 PyQuery简介 pyquery能够通过选择器精确定位 DOM 树中的目标并进行操作.pyquery相当于jQuery的python实现,可以用于解析HTML网 ...
- FocusBI: 使用Python爬虫为BI准备数据源(原创)
关注微信公众号:FocusBI 查看更多文章:加QQ群:808774277 获取学习资料和一起探讨问题. <商业智能教程>pdf下载地址 链接:https://pan.baidu.com/ ...
- 高德API+Python解决租房问题(.NET版)
源码地址:https://github.com/liguobao/58HouseSearch 在线地址:58公寓高德搜房(全国版):http://codelover.link:8080/ 周末闲着无事 ...
- Python爬虫:设置Cookie解决网站拦截并爬取蚂蚁短租
前言 文的文字及图片来源于网络,仅供学习.交流使用,不具有任何商业用途,版权归原作者所有,如有问题请及时联系我们以作处理. 作者: Eastmount PS:如有需要Python学习资料的小伙伴可以加 ...
- GitHub 上有哪些优秀的 Python 爬虫项目?
目录 GitHub 上有哪些优秀的 Python 爬虫项目? 大型爬虫项目: 实用型爬虫项目: 其它有趣的Python爬虫小项目: GitHub 上有哪些优秀的 Python 爬虫项目? 大型爬虫项目 ...
- Python爬虫系统化学习(5)
Python爬虫系统化学习(5) 多线程爬虫,在之前的网络编程中,我学习过多线程socket进行单服务器对多客户端的连接,通过使用多线程编程,可以大大提升爬虫的效率. Python多线程爬虫主要由三部 ...
随机推荐
- Weex Ui - Weex Conf 2018 干货分享
本文是2018年 Weex Conf 中议题<Weex + Ui>的内容文档整理,主要给大家介绍飞猪 Weex 技术体系从无到有的过程,包括 Weex Ui 组件库的开发和发展,重点分享在 ...
- FFI
FFI概念 https://segmentfault.com/t/ffi/info FFI即Foreign Function Interface,外部函数调用接口,是一个语言提供的使用其他语言现有库( ...
- 三十一、Linux 进程与信号——SIGCHLD 信号、kill和raise函数以及alarm函数
31.1 SIGCHLD 信号 子进程状态发生变化(子进程结束)产生该信号,父进程需要使用 wait 调用来等待子进程结束并回收它. 避免僵尸进程 #include <stdio.h> # ...
- 【51nod 1785】数据流中的算法
Description 51nod近日上线了用户满意度检测工具,使用高级人工智能算法,通过用户访问时间.鼠标轨迹等特征计算用户对于网站的满意程度. 现有的统计工具只能统计某一个窗口中,用户的满意程 ...
- mysql 5.7 ERROR 1054(42S22) Unknown column 'password' in ‘field list’ 报错
mysql 忘记密码 报错?ERROR 1054(42S22) Unknown column 'password' in ‘field list’原因:5.7版本下的mysql数据库下已经没有pass ...
- luogu P3722 [AH2017/HNOI2017]影魔
传送门 我太弱了,只会乱搞,正解是不可能正解的,这辈子不可能写正解的,太蠢了又想不出什么东西,就是乱搞这种东西,才能维持得了做题这样子 考虑将询问离线,按右端点排序,并且预处理出每个位置往前面第一个大 ...
- Karel版本的nnet1
除了chain,nnet1, nnet2, nnet3训练时调整转移模型,chain模型使用类似与MMI的训练准则 概要 Karel Vesely的nnet1用到以下技术: 每一层进行预训练,基于RB ...
- linux 查看文件夹大小
参考链接: http://www.cnblogs.com/iconfig/p/4863063.html
- React多行文本溢出处理(仅针对纯文本)
最多显示4行,第四行末尾显示“...”
- 《一头扎进SpringMvc视频教程》
第二章 SpringMvc控制器 第三章 Rest风格的资源URL 第四章 SpringMvc上传文件