5-----Scrapy框架中Spiders用法
Spider类定义了如何爬去某个网站,包括爬取的动作以及如何从网页内容中提取结构化的数据,总的来说spider就是定义爬取的动作以及分析某个网页
工作流程分析
1、以初始的URL初始化Request,并设置回调函数,当该request下载完毕并返回时,将生成response,并作为参数传给回调函数. spider中初始的 requesst是通过 start_requests()来获取的。start_requests()获取 start_urls中的URL,并以 parse以回调函数生成 Request
2、在回调函数内分析返回的网页内容,可以返回Item对象,或者 Dict,或者 Request,以及是一个包含三者的可迭代的容器,返回的Request对象之后会经过Scrapy处理,下载相应的内容,并调用设置的 callback函数
3、在回调函数内,可以通过 lxml,bs4,xpath,css等方法获取我们想要的内容生成 item
4、最后将 item传递给 Pipeline处理
我们以通过简单的分析源码来理解
我通常在写spiders下写爬虫的时候,我们并没有写 start_requests来处理 start_urls中的url,这是因为我们在继承的scrapy.Spider中已经写过了,我们可以点开scrapy.Spider查看分析。
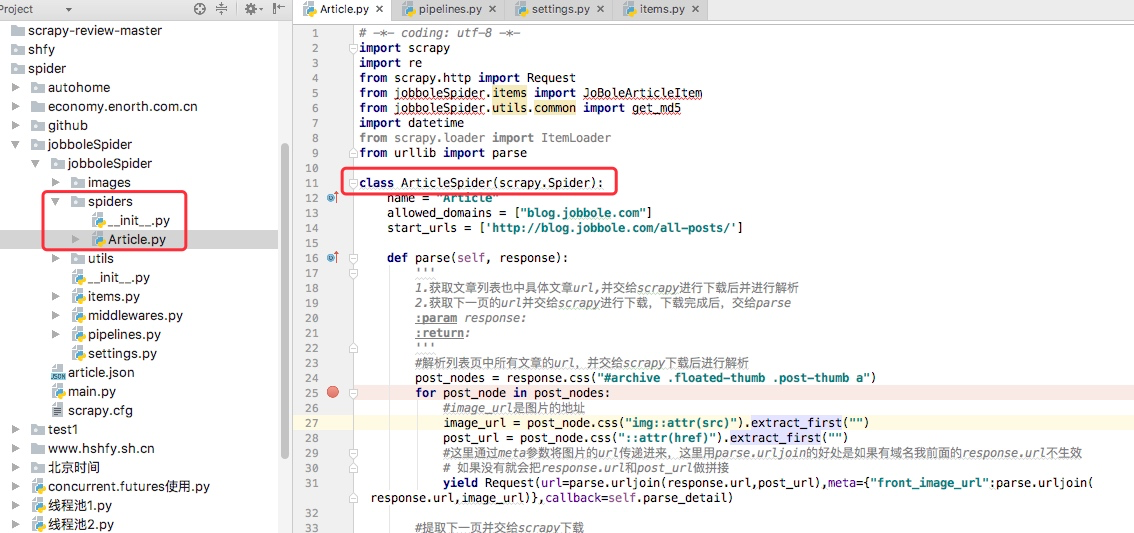
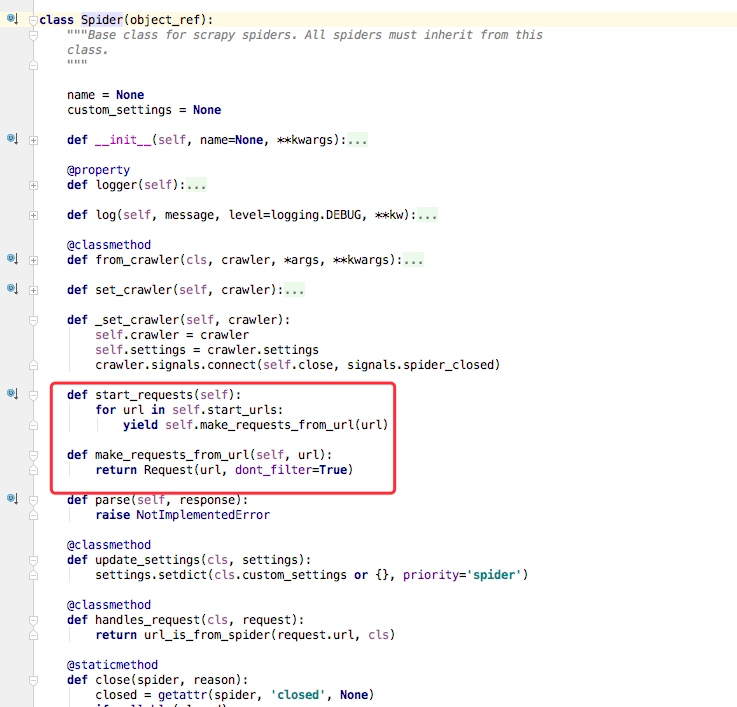
通过上述代码我们可以看到在父类里这里实现了 start_requests方法,通过 make_requests_from_url做了Request请求
如下图所示的一个例子,parse回调函数中的 response就是父类列 start_requests方法调用 make_requests_from_url返回的结果,并且在parse回调函数中我们可以继续返回 Request,如下属代码中 yield Request()并设置回调函数。
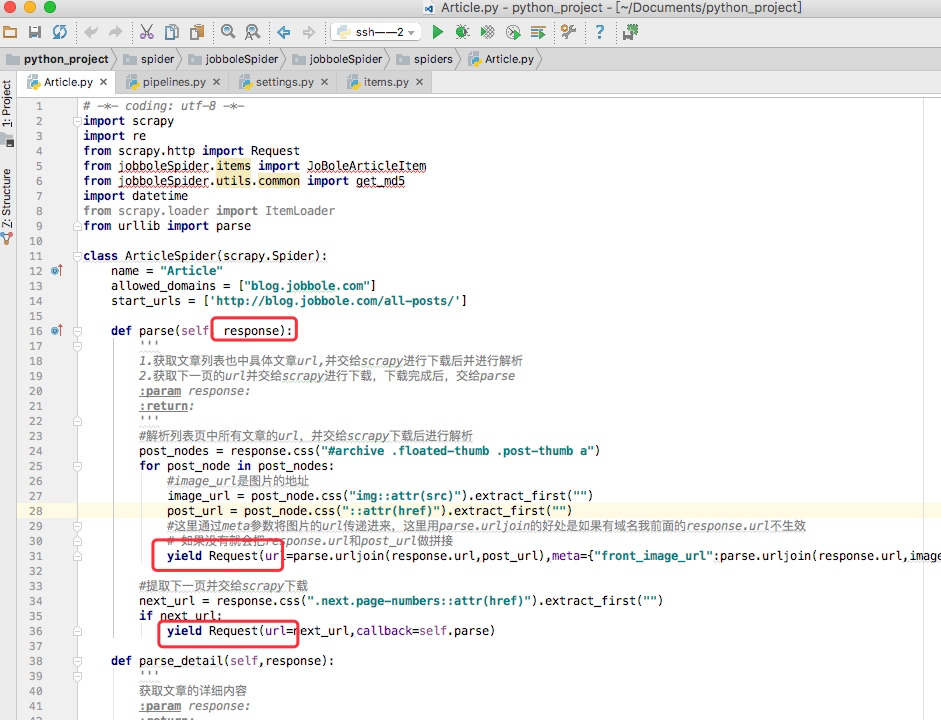
spider内的一些常用属性
我们所有自己写的爬虫都是继承与spider.Spider这个类
name
定义爬虫名字,我们通过命令启动的时候用的就是这个名字,这个名字必须是唯一的
allowed_domains
包含了spider允许爬取的域名列表。当offsiteMiddleware启用时,域名不在列表中URL不会被访问
所以在爬虫文件中,每次生成Request请求时都会进行和这里的域名进行判断
start_urls
起始的url列表
这里会通过spider.Spider方法中会调用start_request循环请求这个列表中每个地址。
custom_settings
自定义配置,可以覆盖settings的配置,主要用于当我们对爬虫有特定需求设置的时候
设置的是以字典的方式设置:custom_settings = {}
from_crawler
这是一个类方法,我们定义这样一个类方法,可以通过crawler.settings.get()这种方式获取settings配置文件中的信息,同时这个也可以在pipeline中使用
start_requests()
这个方法必须返回一个可迭代对象,该对象包含了spider用于爬取的第一个Request请求
这个方法是在被继承的父类中spider.Spider中写的,默认是通过get请求,如果我们需要修改最开始的这个请求,可以重写这个方法,如我们想通过post请求
make_requests_from_url(url)
这个也是在父类中start_requests调用的,当然这个方法我们也可以重写
parse(response)
这个其实默认的回调函数
负责处理response并返回处理的数据以及跟进的url
该方法以及其他的Request回调函数必须返回一个包含Request或Item的可迭代对象
5-----Scrapy框架中Spiders用法的更多相关文章
- scrapy框架中Spiders用法
scrapy框架中Spiders用法 Spider类定义了如何爬去某个网站,包括爬取的动作以及如何从网页内容中提取结构化的数据 总的来说spider就是定义爬取的动作以及分析某个网页 工作流程分析 以 ...
- Python爬虫从入门到放弃(十五)之 Scrapy框架中Spiders用法
Spider类定义了如何爬去某个网站,包括爬取的动作以及如何从网页内容中提取结构化的数据,总的来说spider就是定义爬取的动作以及分析某个网页 工作流程分析 以初始的URL初始化Request,并设 ...
- Python之爬虫(十七) Scrapy框架中Spiders用法
Spider类定义了如何爬去某个网站,包括爬取的动作以及如何从网页内容中提取结构化的数据,总的来说spider就是定义爬取的动作以及分析某个网页 工作流程分析 以初始的URL初始化Request,并设 ...
- scrapy框架中Download Middleware用法
scrapy框架中Download Middleware用法 Downloader Middleware处理的过程主要在调度器发送requests请求的时候以及网页将response结果返回给sp ...
- Scrapy框架中选择器的用法【转】
Python爬虫从入门到放弃(十四)之 Scrapy框架中选择器的用法 请给作者点赞 --> 原文链接 Scrapy提取数据有自己的一套机制,被称作选择器(selectors),通过特定的Xpa ...
- scrapy框架中Item Pipeline用法
scrapy框架中item pipeline用法 当Item 在Spider中被收集之后,就会被传递到Item Pipeline中进行处理 每个item pipeline组件是实现了简单的方法的pyt ...
- scrapy框架中选择器的用法
scrapy框架中选择器的用法 Scrapy提取数据有自己的一套机制,被称作选择器(selectors),通过特定的Xpath或者CSS表达式来选择HTML文件的某个部分Xpath是专门在XML文件中 ...
- Scrapy框架中的CrawlSpider
小思考:如果想要通过爬虫程序去爬取”糗百“全站数据新闻数据的话,有几种实现方法? 方法一:基于Scrapy框架中的Spider的递归爬取进行实现(Request模块递归回调parse方法). 方法二: ...
- Scrapy框架中的xpath选择
不同于我们普通爬虫获取xpath,scrapy获得xpath对象获取他的值语法 一.xpath对象获取值 xpath对象..extract() 二.Scrapy框架独有的xpath取值方式 利用hre ...
随机推荐
- nginx负载均衡, 配置地址带端口
nginx.conf 配置如下: upstream wlcf.dev.api { server 127.0.0.1:8833; server 127.0.0.2:8833; } server { l ...
- tomcat启动时加载配置文件 报错
原因: @serice("customerService") 和@Repository(value="customerDao") 解决: 直接@ ...
- java中怎么把String转化为字符数组呢?
我想让用户输入一组字符串,然后将这个字符串的每一个赋给一个char.即,abcde char ch[]=new char[5]; ch[0]=a;ch[1]=b;..... 解决方案如下图所示: St ...
- p3163 [CQOI2014]危桥
传送门 分析 代码 #include<iostream> #include<cstdio> #include<cstring> #include<string ...
- Flask框架 之 基本使用
初识Flask Flask是一个基于Python开发并且依赖jinja2模板和Werkzeug WSGI服务的一个微型框架,对于Werkzeug本质是Socket服务端,其用于接收http请求并对请求 ...
- Android应用启动优化:一种DelayLoad的实现和原理
http://www.androidperformance.com/2015/11/18/Android-app-lunch-optimize-delay-load.html
- 如何设置Oracle process值
参考链接:http://blog.51cto.com/sunwayle/88870 su - oracle sqlplus system as sysdba; show parameter proce ...
- C#字符串拼接的三种方式
static void Main(string[] args) { string name = "asher"; //方法1 string str1 = "hello & ...
- SQL XML示例
declare @xmlDoc xml,@id varchar(50); set @xmlDoc='<DocObjContent> <NewCtrl Id="0001&qu ...
- 转载-ActiveMQ通过JAAS实现的安全机制
JAAS(Java Authentication and Authorization Service)也就是java认证/授权服务.这是两种不同的服务,下面对其做一些区别:验证(Authenticat ...