5-----Scrapy框架中Spiders用法
Spider类定义了如何爬去某个网站,包括爬取的动作以及如何从网页内容中提取结构化的数据,总的来说spider就是定义爬取的动作以及分析某个网页
工作流程分析
1、以初始的URL初始化Request,并设置回调函数,当该request下载完毕并返回时,将生成response,并作为参数传给回调函数. spider中初始的 requesst是通过 start_requests()来获取的。start_requests()获取 start_urls中的URL,并以 parse以回调函数生成 Request
2、在回调函数内分析返回的网页内容,可以返回Item对象,或者 Dict,或者 Request,以及是一个包含三者的可迭代的容器,返回的Request对象之后会经过Scrapy处理,下载相应的内容,并调用设置的 callback函数
3、在回调函数内,可以通过 lxml,bs4,xpath,css等方法获取我们想要的内容生成 item
4、最后将 item传递给 Pipeline处理
我们以通过简单的分析源码来理解
我通常在写spiders下写爬虫的时候,我们并没有写 start_requests来处理 start_urls中的url,这是因为我们在继承的scrapy.Spider中已经写过了,我们可以点开scrapy.Spider查看分析。
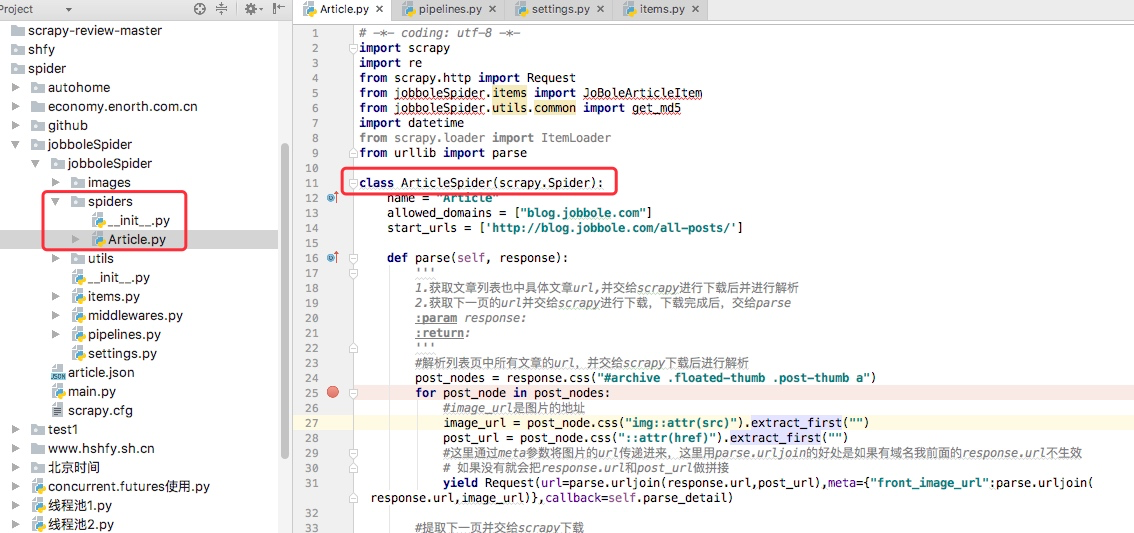
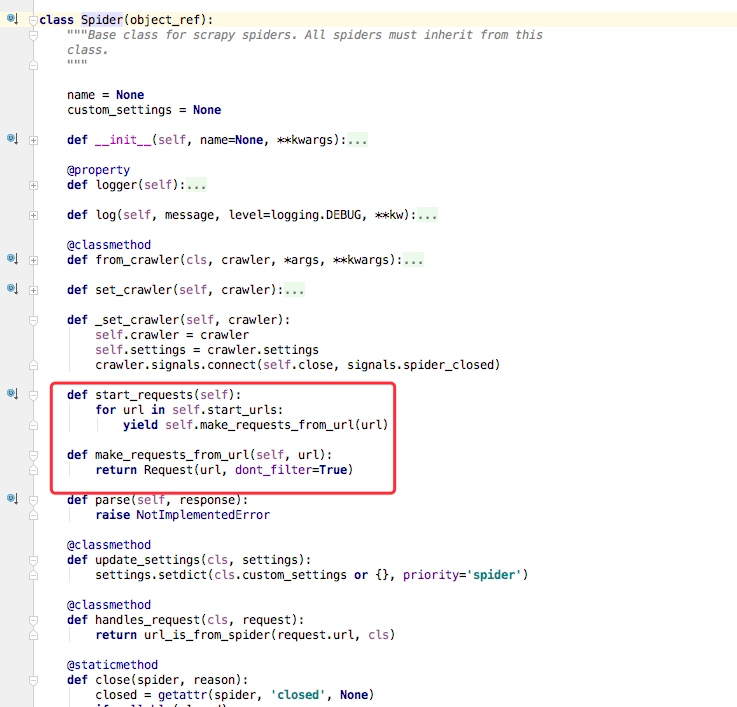
通过上述代码我们可以看到在父类里这里实现了 start_requests方法,通过 make_requests_from_url做了Request请求
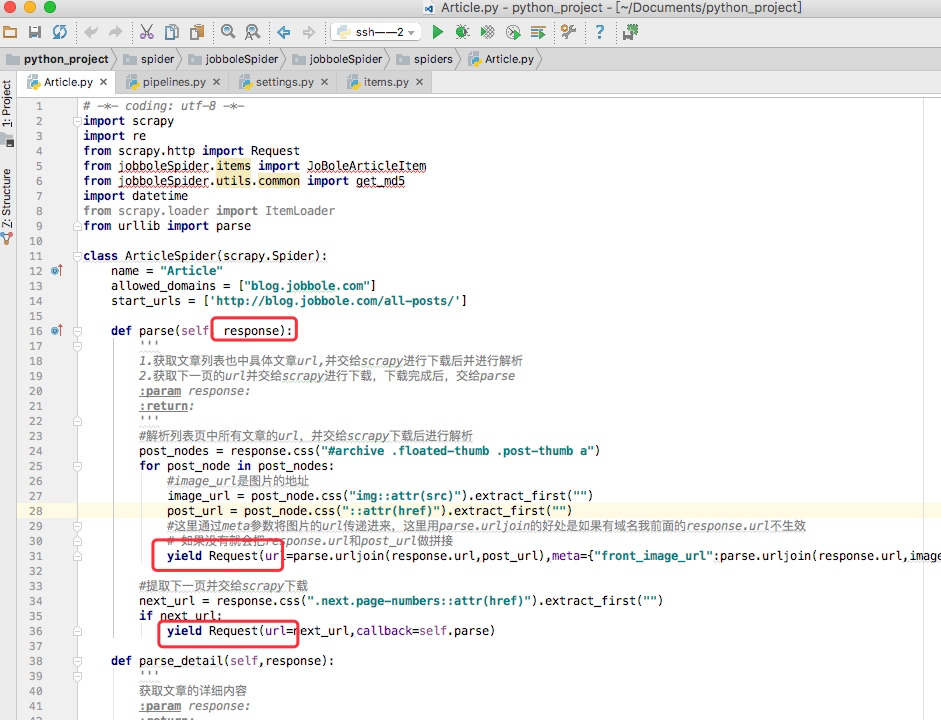
如下图所示的一个例子,parse回调函数中的 response就是父类列 start_requests方法调用 make_requests_from_url返回的结果,并且在parse回调函数中我们可以继续返回 Request,如下属代码中 yield Request()并设置回调函数。
spider内的一些常用属性
我们所有自己写的爬虫都是继承与spider.Spider这个类
name
定义爬虫名字,我们通过命令启动的时候用的就是这个名字,这个名字必须是唯一的
allowed_domains
包含了spider允许爬取的域名列表。当offsiteMiddleware启用时,域名不在列表中URL不会被访问
所以在爬虫文件中,每次生成Request请求时都会进行和这里的域名进行判断
start_urls
起始的url列表
这里会通过spider.Spider方法中会调用start_request循环请求这个列表中每个地址。
custom_settings
自定义配置,可以覆盖settings的配置,主要用于当我们对爬虫有特定需求设置的时候
设置的是以字典的方式设置:custom_settings = {}
from_crawler
这是一个类方法,我们定义这样一个类方法,可以通过crawler.settings.get()这种方式获取settings配置文件中的信息,同时这个也可以在pipeline中使用
start_requests()
这个方法必须返回一个可迭代对象,该对象包含了spider用于爬取的第一个Request请求
这个方法是在被继承的父类中spider.Spider中写的,默认是通过get请求,如果我们需要修改最开始的这个请求,可以重写这个方法,如我们想通过post请求
make_requests_from_url(url)
这个也是在父类中start_requests调用的,当然这个方法我们也可以重写
parse(response)
这个其实默认的回调函数
负责处理response并返回处理的数据以及跟进的url
该方法以及其他的Request回调函数必须返回一个包含Request或Item的可迭代对象
5-----Scrapy框架中Spiders用法的更多相关文章
- scrapy框架中Spiders用法
scrapy框架中Spiders用法 Spider类定义了如何爬去某个网站,包括爬取的动作以及如何从网页内容中提取结构化的数据 总的来说spider就是定义爬取的动作以及分析某个网页 工作流程分析 以 ...
- Python爬虫从入门到放弃(十五)之 Scrapy框架中Spiders用法
Spider类定义了如何爬去某个网站,包括爬取的动作以及如何从网页内容中提取结构化的数据,总的来说spider就是定义爬取的动作以及分析某个网页 工作流程分析 以初始的URL初始化Request,并设 ...
- Python之爬虫(十七) Scrapy框架中Spiders用法
Spider类定义了如何爬去某个网站,包括爬取的动作以及如何从网页内容中提取结构化的数据,总的来说spider就是定义爬取的动作以及分析某个网页 工作流程分析 以初始的URL初始化Request,并设 ...
- scrapy框架中Download Middleware用法
scrapy框架中Download Middleware用法 Downloader Middleware处理的过程主要在调度器发送requests请求的时候以及网页将response结果返回给sp ...
- Scrapy框架中选择器的用法【转】
Python爬虫从入门到放弃(十四)之 Scrapy框架中选择器的用法 请给作者点赞 --> 原文链接 Scrapy提取数据有自己的一套机制,被称作选择器(selectors),通过特定的Xpa ...
- scrapy框架中Item Pipeline用法
scrapy框架中item pipeline用法 当Item 在Spider中被收集之后,就会被传递到Item Pipeline中进行处理 每个item pipeline组件是实现了简单的方法的pyt ...
- scrapy框架中选择器的用法
scrapy框架中选择器的用法 Scrapy提取数据有自己的一套机制,被称作选择器(selectors),通过特定的Xpath或者CSS表达式来选择HTML文件的某个部分Xpath是专门在XML文件中 ...
- Scrapy框架中的CrawlSpider
小思考:如果想要通过爬虫程序去爬取”糗百“全站数据新闻数据的话,有几种实现方法? 方法一:基于Scrapy框架中的Spider的递归爬取进行实现(Request模块递归回调parse方法). 方法二: ...
- Scrapy框架中的xpath选择
不同于我们普通爬虫获取xpath,scrapy获得xpath对象获取他的值语法 一.xpath对象获取值 xpath对象..extract() 二.Scrapy框架独有的xpath取值方式 利用hre ...
随机推荐
- winform 对话框控件
ColorDialog 可以调节颜色的控件,如果给一个按钮点击事件 ColorDialog.showdialog();就会弹出这个 返回值是个枚举类 然后定义一个这个类的变量 接收一下它的返回值 Di ...
- java的邮件系统实现
想要java中邮件发送和接收邮件,首先需要支持SMTP- pop/pop3/IMAP协议,发送的话还需要配置文件,来对程序提供相应的接口,只需要这两个文件,就可以实现邮件的接收发送, 协议为jar包封 ...
- Linux 使用静态库注意事项
1. 静态库一定要放在生成文件后面 gcc main.c -o main libhello.a 2. 使用静态库时一定要连接所有用到的静态库 gcc main.c -o main liba.a lib ...
- java中byte是什么类型,和int有什么区别
byte字节型,int是整型,byte是8bit,int是32bit. byte可以转换为int,但int转byte可能会报错,因为精度问题,可能会超过上界.char也可转int,互转int的关系和b ...
- tcpdump/HTTP协议实践
tcpdump/HTTP协议实践 客户端: CLOSED->SYN_SENT->ESTABLISHED->FIN_WAIT_1->FIN_WAIT_2->TIME_WAI ...
- 【C#】EF学习<二> DbFirst (先创建数据库,表及其关联关系)
工程压缩文件放到百度云盘---20181019001文件夹 1. 创建表的脚本 create table Teacher ( TID char(12) primary key, Tname char( ...
- ListView 动态生成 Header
//取得结果集 DataTable dt = ub.GetUser().Tables[0]; //清空原本的内容 listView1.Items.Clear(); //通过DataTable 得到当前 ...
- metasploit 读书笔记-信息收集
三、信息收集 被动信息收集 在不接触目标系统时进行的信息收集,包括使用工具Yeti、Whois (1)Whois msf > whois secmaniac.net (2)Netcraft:fi ...
- NSNull空值
1.前言 作为占据空间的一个空值,如用在数组或字典中占据一个没有任何值的空间. 1.1 NULL & nil 的区别: nil 是 OC 的,空对象,地址指向空的对象,指针地址指向的是 NUL ...
- 亿级PV请求的三种负载均衡技术(转)
http://www.360doc.com/content/17/1126/23/50145453_707419125.shtml 目录 DNS轮询 LVS负载均衡 DR模式 NAT模式 ...