Python爬虫学习笔记之模拟登陆并爬去GitHub
(1)环境准备:
请确保已经安装了requests和lxml库
(2)分析登陆过程:
首先要分析登陆的过程,需要探究后台的登陆请求是怎样发送的,登陆之后又有怎样的处理过程。
如果已经登陆GitHub,则需要先退出登陆,同时清除Cookies
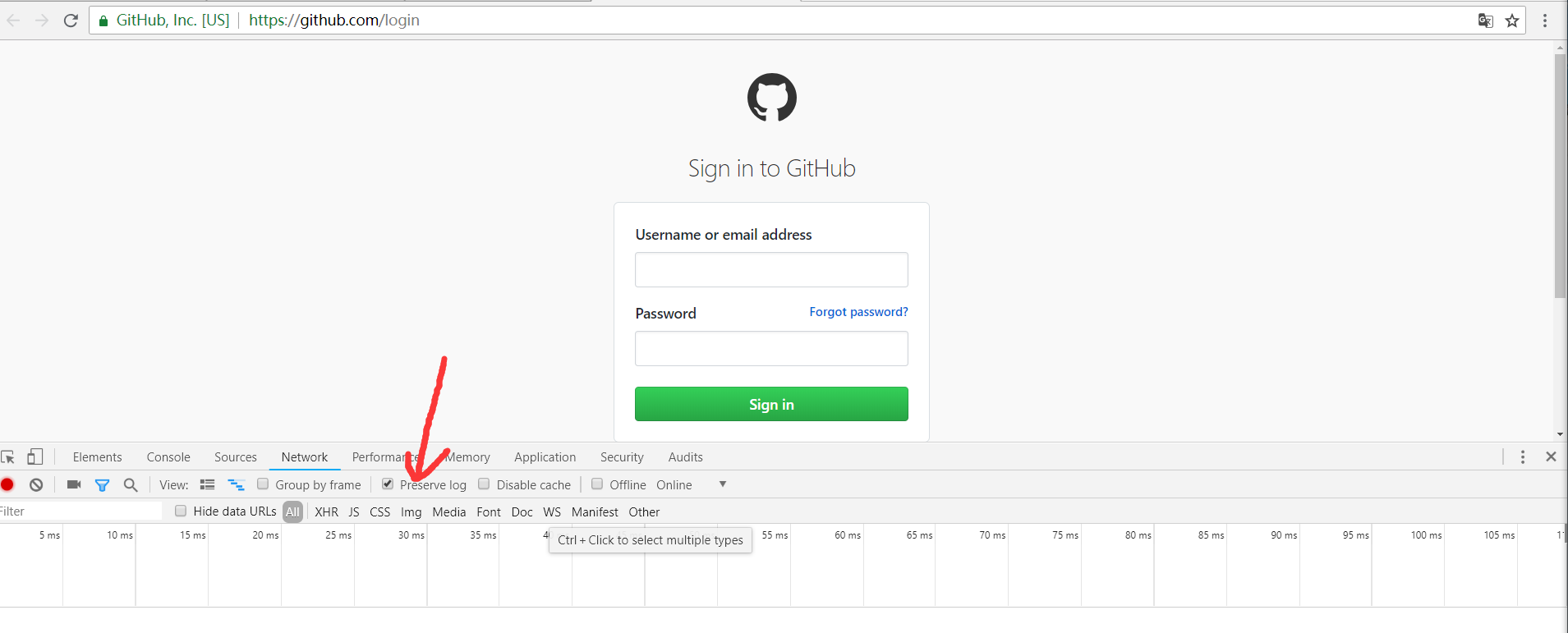
打开GitHub的登陆页面,链接为https://github.com/login,输入GitHub的用户名和密码,打开开发者工具
,将Preserver Log选项勾选上,这表示持续日志,如下图所示
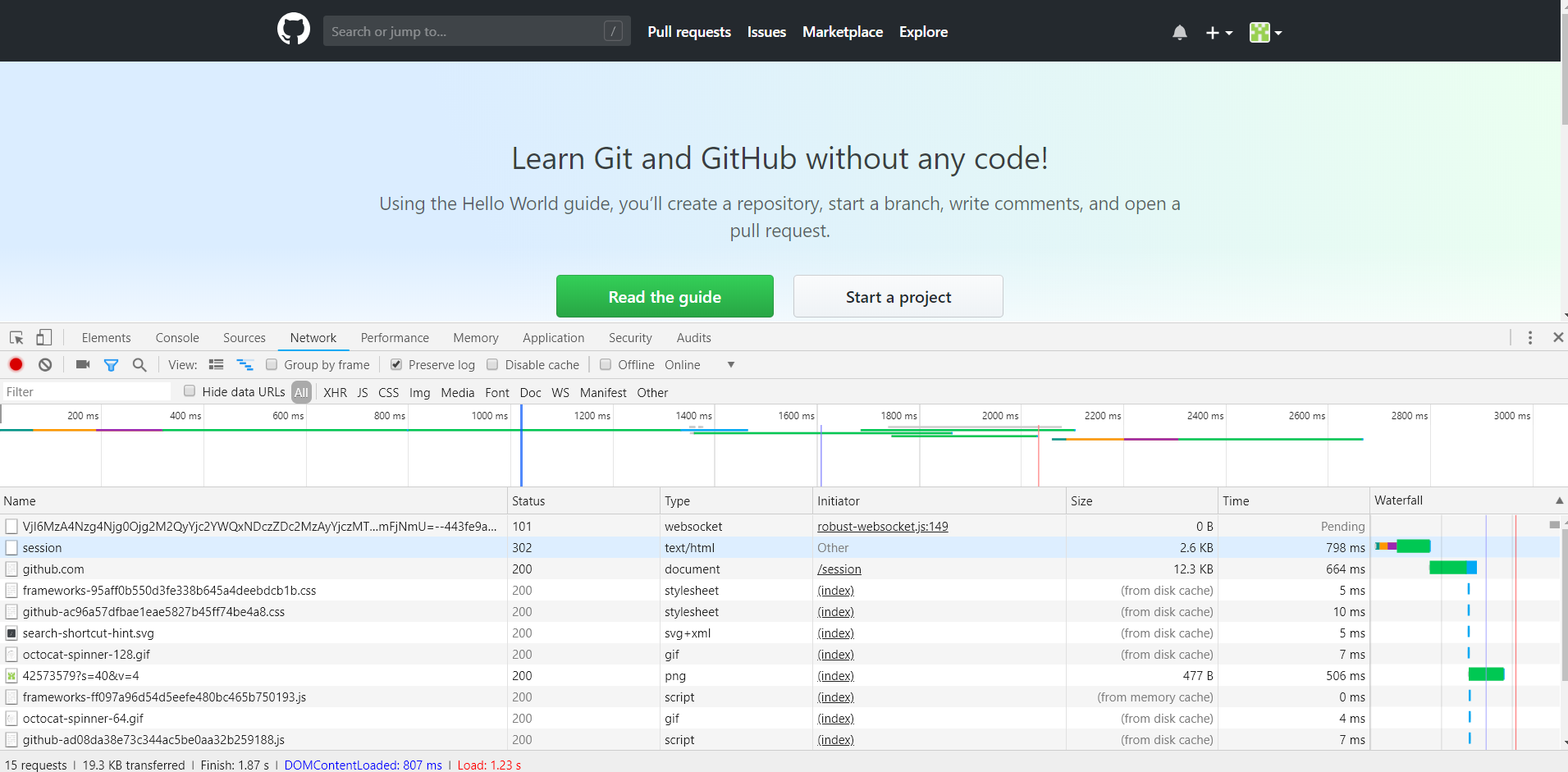
点击登录按钮,这时便会看到开发者工具下方显示了各个请求过程,如下图所示:
点击session请求,进入其详情,如下图所示:
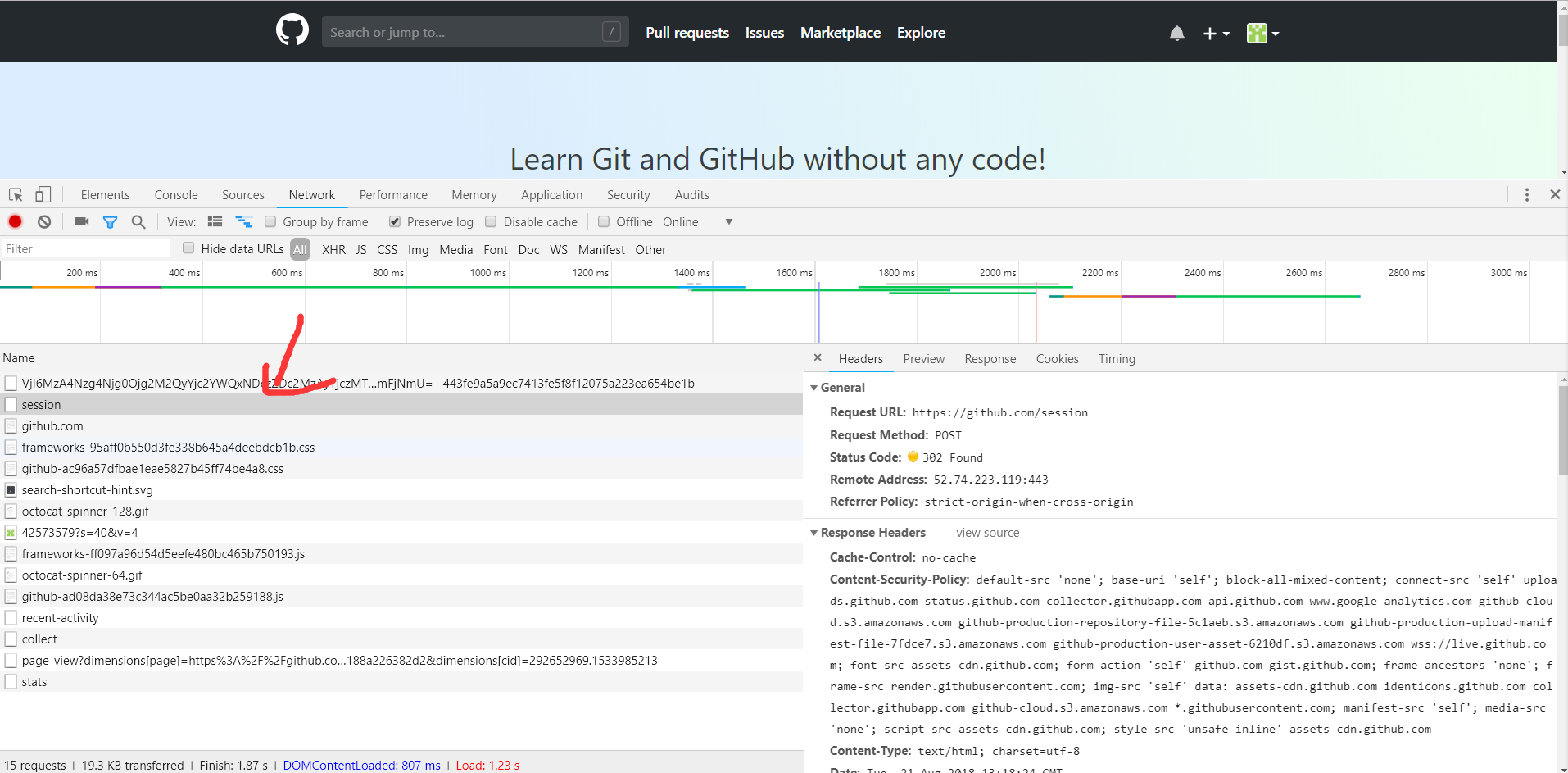
可以看到请求的URL为https://www.github.com/session,请求方式为POST。再往下看,我们观察到他的Form Data和Headers这两部分内容,
如下图所示:
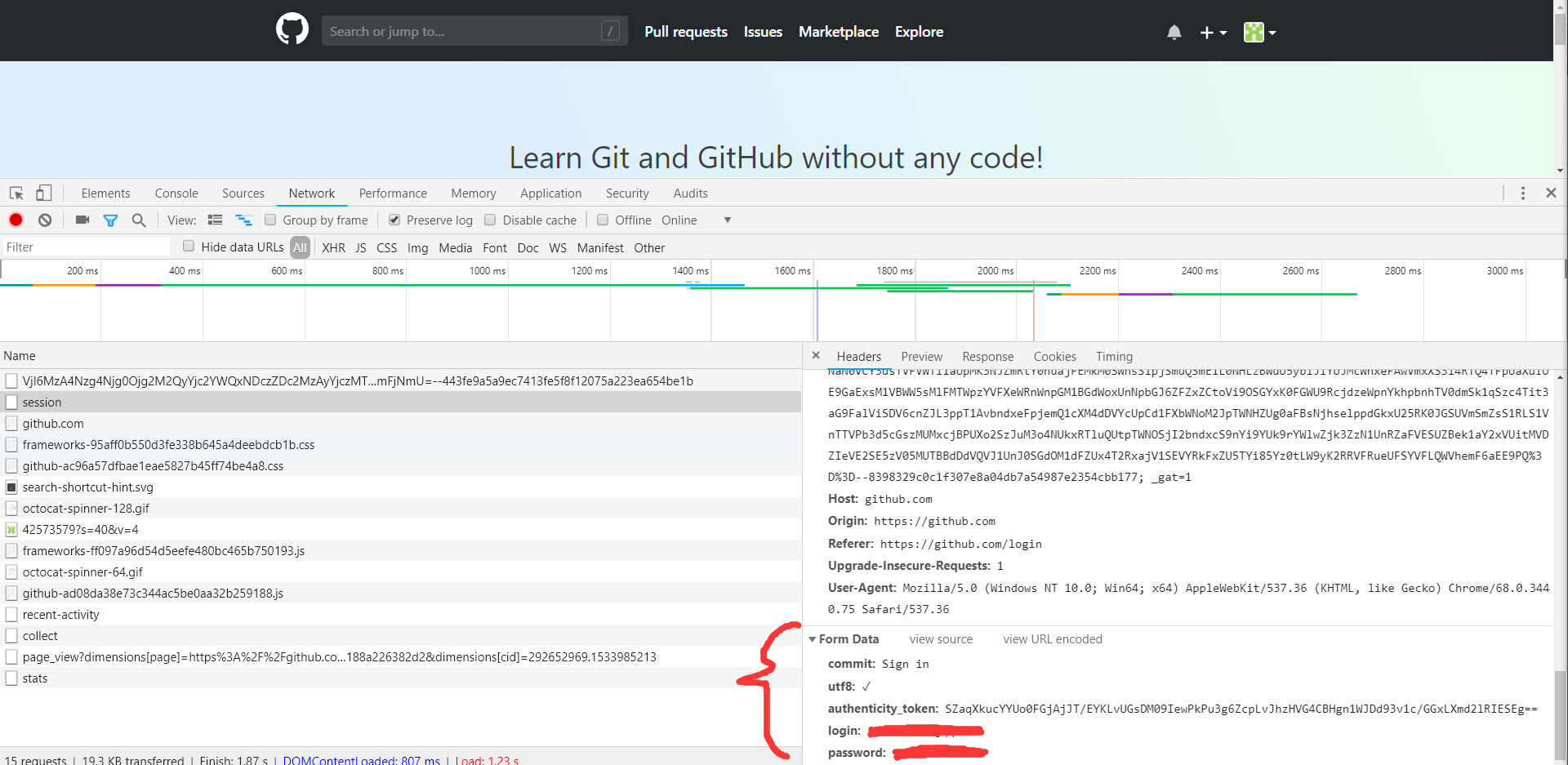
Headers里面包含了Cookies,Host,Origin,Refer,User-Agent等信息。Form Data包含了5个字段,commit是固定的字符串Sign in,utf8
是一个勾选字符,authenticity_token较长,其初步判断是一个Base64加密的字符串,login是登陆的用户名,password是登陆的密码。
综上所述,我们现在无法直接构造的内容有Cookies和authenticity_token。下面我们再来探寻一下这部分内容如何获取。
在登陆之前我们会访问到一个登陆页面,此页面是通过GET形式访问的。输入用户名和密码,点击登录按钮,浏览器发送这两部分信息,也就是
说Cookies和authenticity_token一定在访问扥估页面时候设置的。
这时在退出登陆,回到登录页,同时清除Cookies,重新访问登录页,截获发生的请求,如下图所示:
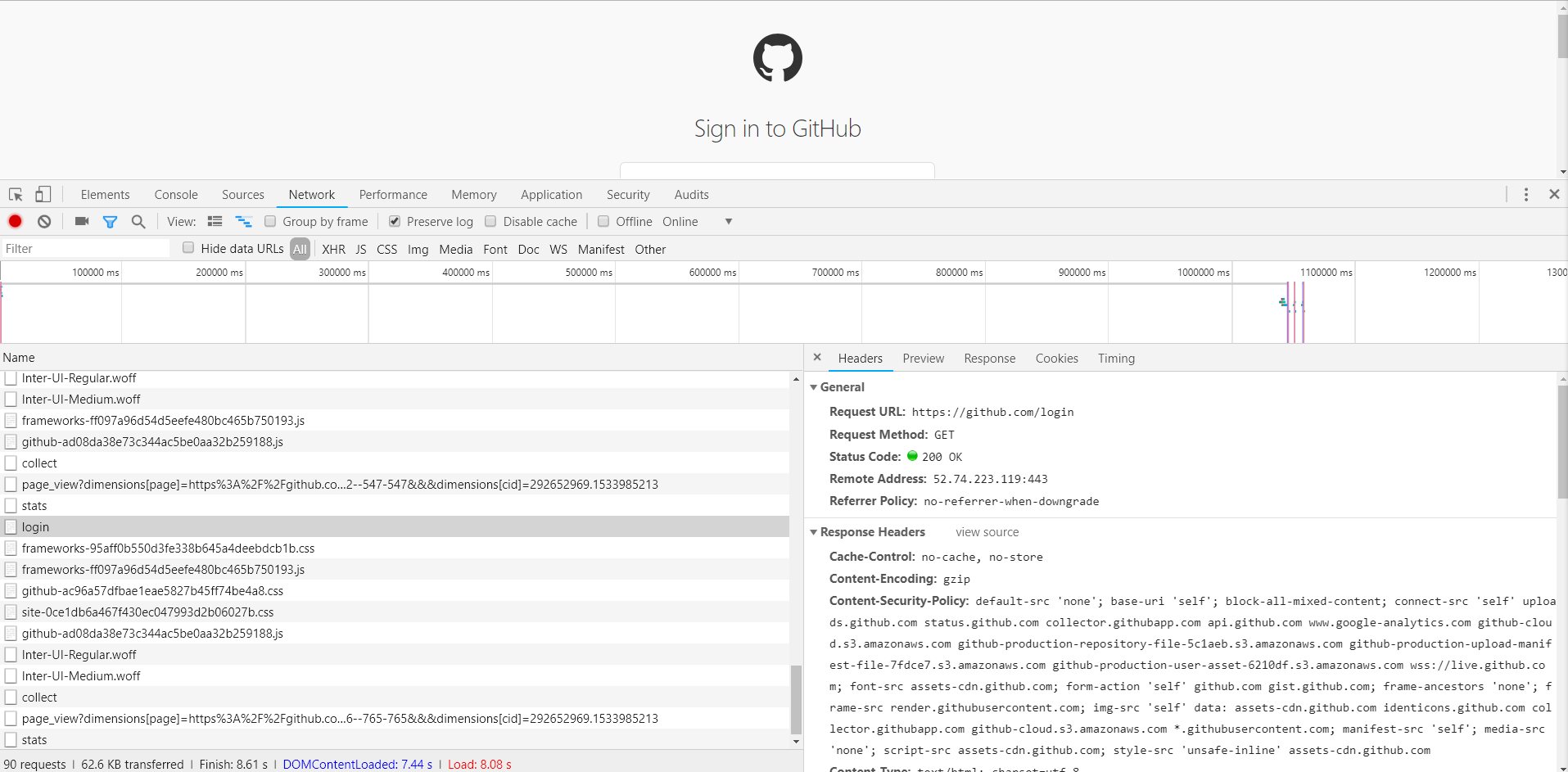
访问登陆页面的请求如上,Response Headers有一个Set-Cookie字段。这就是设置Cookies的过程。
另外,我们发现Response Headers没有和authenticity_token相关的信息,所以可能authenticity_token还隐藏在其他的地方或者是计算出来的
。我们再从网页的源码探寻,搜索相关字段,发现源代码里面还隐藏着此信息,他是一个隐藏式表单元素,如下图所示:
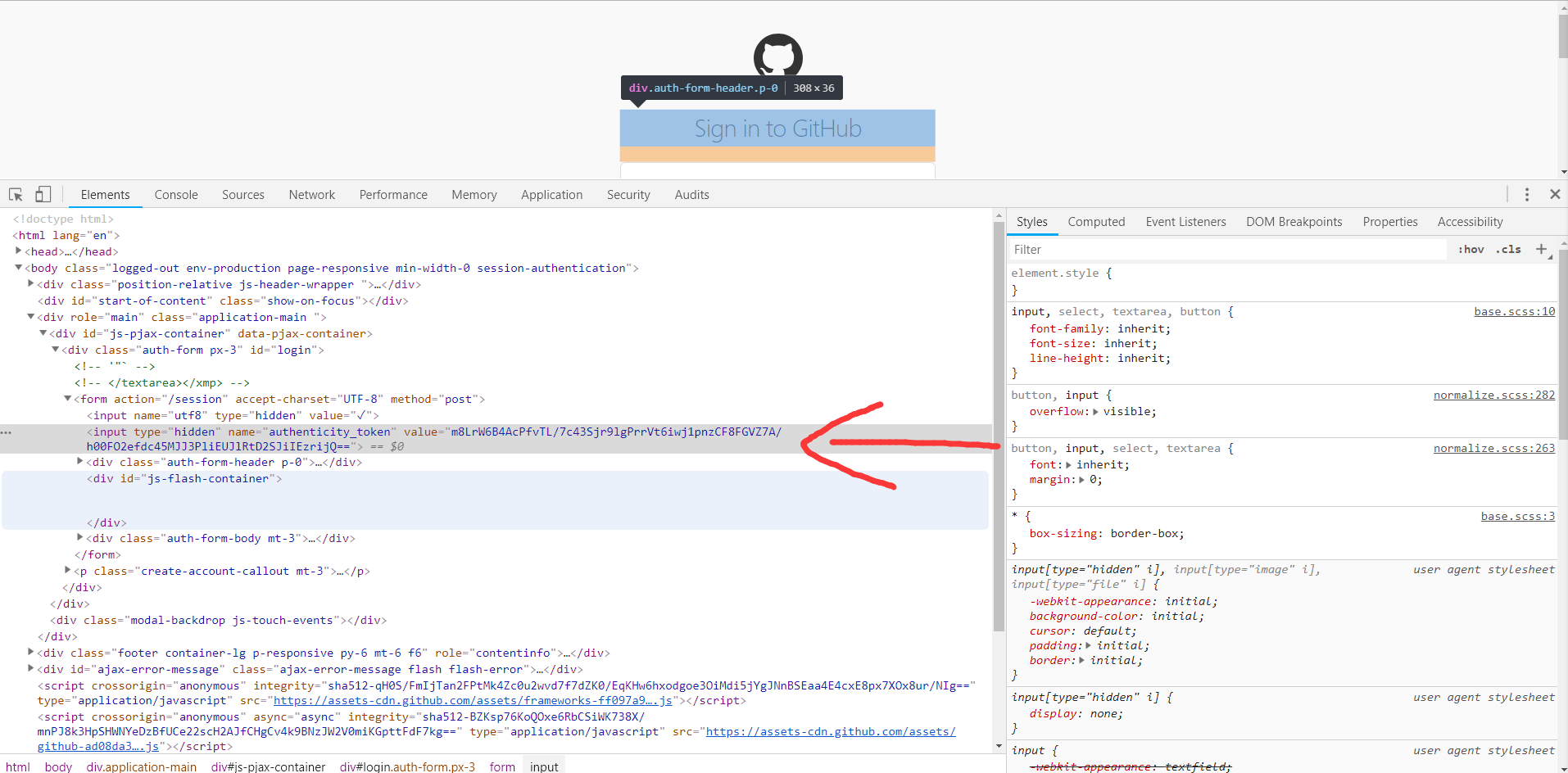
现在我们已经获取到网页所有信息,接下来让我们 实现模拟登陆
(3)代码如下:
import requests
from lxml import etree class Login(object):
def __init__(self):
self.headers = {
'Refer': 'https://github.com',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) '
'Chrome/68.0.3440.75 Safari/537.36',
'Host': 'github.com'
}
self.login_url = 'https://github.com/login'
self.post_url = 'https://github.com/session'
self.logined_url = 'https://github.com/settings/profile'
self.session = requests.Session() # 此函数可以帮助我们维持一个会话,而且可以自动处理cookies,我们不用再去担心cookies的问题 def token(self):
response = self.session.get(self.login_url, headers=self.headers) # 访问GitHub的登录页面
selector = etree.HTML(response.text)
token = selector.xpath('//div//input[2]/@value')[0] # 解析出登陆所需的authenticity_token信息
return token def login(self, email, password):
post_data = {
'commit': 'Sign in',
'utf-8': '✓',
'authenticity_token': self.token(),
'login': email,
'password': password
}
response = self.session.post(self.post_url, data=post_data, headers=self.headers)
if response.status_code == 200:
self.dynamics(response.text) response = self.session.get(self.logined_url, headers=self.headers)
if response.status_code == 200:
self.profile(response.text) def dynamics(self, html): # 使用此方法提取所有动态信息
selector = etree.HTML(html)
dynamics = selector.xpath('//div[contains(@class, "news")]//div[contains(@class, "alert")]')
for item in dynamics:
dynamics = ' '.join(item.xpath('.//div[@class="title"]//text()')).strip()
print(dynamics) def profile(self, html): # 使用此方法提取个人的昵称和绑定的邮箱
selector = etree.HTML(html)
name = selector.xpath('//input[@id="user_profile_name"]/@value')[0]
email = selector.xpath('//select[@id="user_profile_email"]/option[@value!=""]/text()')
print(name, email) if __name__ == "__main__":
login = Login()
login.login(email='', password='') # 此处填自己的
Python爬虫学习笔记之模拟登陆并爬去GitHub的更多相关文章
- python爬虫学习(3)_模拟登陆
1.登陆超星慕课,chrome抓包,模拟header,提取表单隐藏元素构成params. 主要是验证码图片地址,在js中发现由js->new Date().getTime()时间戳动态生成url ...
- python爬虫学习笔记(一)——环境配置(windows系统)
在进行python爬虫学习前,需要进行如下准备工作: python3+pip官方配置 1.Anaconda(推荐,包括python和相关库) [推荐地址:清华镜像] https://mirrors ...
- Python爬虫学习笔记——豆瓣登陆(三)
之前是不会想到登陆一个豆瓣会需要写三次博客,修改三次代码的. 本来昨天上午之前的代码用的挺好的,下午时候,我重新注册了一个号,怕豆瓣大号被封,想用小号爬,然后就开始出问题了,发现无法模拟登陆豆瓣了,开 ...
- python爬虫学习笔记
爬虫的分类 1.通用爬虫:通用爬虫是搜索引擎(Baidu.Google.Yahoo等)“抓取系统”的重要组成部分.主要目的是将互联网上的网页下载到本地,形成一个互联网内容的镜像备份. 简单来讲就是尽可 ...
- 一入爬虫深似海,从此游戏是路人!总结我的python爬虫学习笔记!
前言 还记得是大学2年级的时候,偶然之间看到了学长在学习python:我就坐在旁边看他敲着代码,感觉很好奇.感觉很酷,从那之后,我就想和学长一样的厉害,就想让学长教我,请他吃了一周的饭,他答应了.从此 ...
- Python爬虫学习笔记-1.Urllib库
urllib 是python内置的基本库,提供了一系列用于操作URL的功能,我们可以通过它来做一个简单的爬虫. 0X01 基本使用 简单的爬取一个页面: import urllib2 request ...
- Python爬虫学习笔记(一)
概念: 使用代码模拟用户,批量发送网络请求,批量获取数据. 分类: 通用爬虫: 通用爬虫是搜索引擎(Baidu.Google.Yahoo等)"抓取系统"的重要组成部分. 主要目的是 ...
- Python爬虫学习笔记(三)
Cookies: 以抓取https://www.yaozh.com/为例 Test1(不使用cookies): 代码: import urllib.request # 1.添加URL url = &q ...
- 模拟登陆并爬取Github
因为崔前辈给出的代码运行有误,略作修改和简化了. 书上例题,不做介绍. import requests from lxml import etree class Login(object): def ...
随机推荐
- Paper Reading - Show, Attend and Tell: Neural Image Caption Generation with Visual Attention ( ICML 2015 )
Link of the Paper: https://arxiv.org/pdf/1502.03044.pdf Main Points: Encoder-Decoder Framework: Enco ...
- solidity中的memory和 storage详解
Solidity是一种智能合约高级语言,运行在Ethereum虚拟机(EVM)之上.这里我会讲解一下关键字storage和memory的区别. storage的结构是在合约部署创建时,根据你的合约中状 ...
- OpenCV学习5-----使用Mat合并多张图像
最近做实验需要对比实验结果,需要将几张图片拼在一起,直观对比. 尝试用OpenCV解决. 核心思想其实是 声明一个足够大的,正好容纳下那几张图片的mat,然后将拼图依次copy到大图片相应的位置. ...
- POJ 2987 Firing(最大流最小割の最大权闭合图)
Description You’ve finally got mad at “the world’s most stupid” employees of yours and decided to do ...
- vue.js学习之 跨域请求代理与axios传参
vue.js学习之 跨域请求代理与axios传参 一:跨域请求代理 1:打开config/index.js module.exports{ dev: { } } 在这里面找到proxyTable{}, ...
- c语言中反转字符串的函数strrev(), reverse()
1.使用string.h中的strrev函数 #include<stdio.h> #include<string.h> int main() { char s[]=" ...
- 软工冲刺-Alpha 冲刺 (3/10)
队名:起床一起肝活队 组长博客:博客链接 作业博客:班级博客本次作业的链接 组员情况 组员1(队长):白晨曦 过去两天完成了哪些任务 描述: 很胖,刚学,照猫画虎做了登录与注册界面. 展示GitHub ...
- iOS- 如何从Boujour里解析出IP地址(sockaddr *的解析)?
1.前言 之前有网友跟我留言说到: 如何从Boujour 解析完的数组里解析出ip地址? 因为Boujour本身解析完毕之后的addresses是一个数组 那我们如何从这个数组里解析出我们需要的IP地 ...
- C#之WCF入门1—简单的wcf例子
第一步:创建一个空的解决方案,新建一个WCF服务应用程序项目(使用默认名字) 来模拟服务端,新建一个控制台应用程序项目(名称改为 ConsoleApp)来模拟客户端. 第二步:简单分析WcfServi ...
- Linux文件传输FTP详解
ftp命令用来设置文件系统相关功能.ftp服务器在网上较为常见,Linux ftp命令的功能是用命令的方式来控制在本地机和远程机之间传送文件,这里详细介绍Linux ftp命令的一些经常使用的命令,相 ...