python爬虫-爬取盗墓笔记
本来今天要继续更新 scrapy爬取美女图片 系列文章,可是发现使用免费的代理ip都非常不稳定,有时候连接上,有时候连接不上,所以我想找到稳定的代理ip,下次再更新 scrapy爬取美女图片之应对反爬虫 文章。(我的新书《Python爬虫开发与项目实战》出版了,大家可以看一下样章)
好了,废话不多说,咱们进入今天的主题。这一篇文章是关于爬取盗墓笔记,主要技术要点是scrapy的使用,scrapy框架中使用mongodb数据库,文件的保存。

这次爬取的网址是 http://seputu.com/。之前也经常在上面在线看盗墓笔记。

按照咱们之前的学习爬虫的做法,使用firebug审查元素,查看如何解析html。
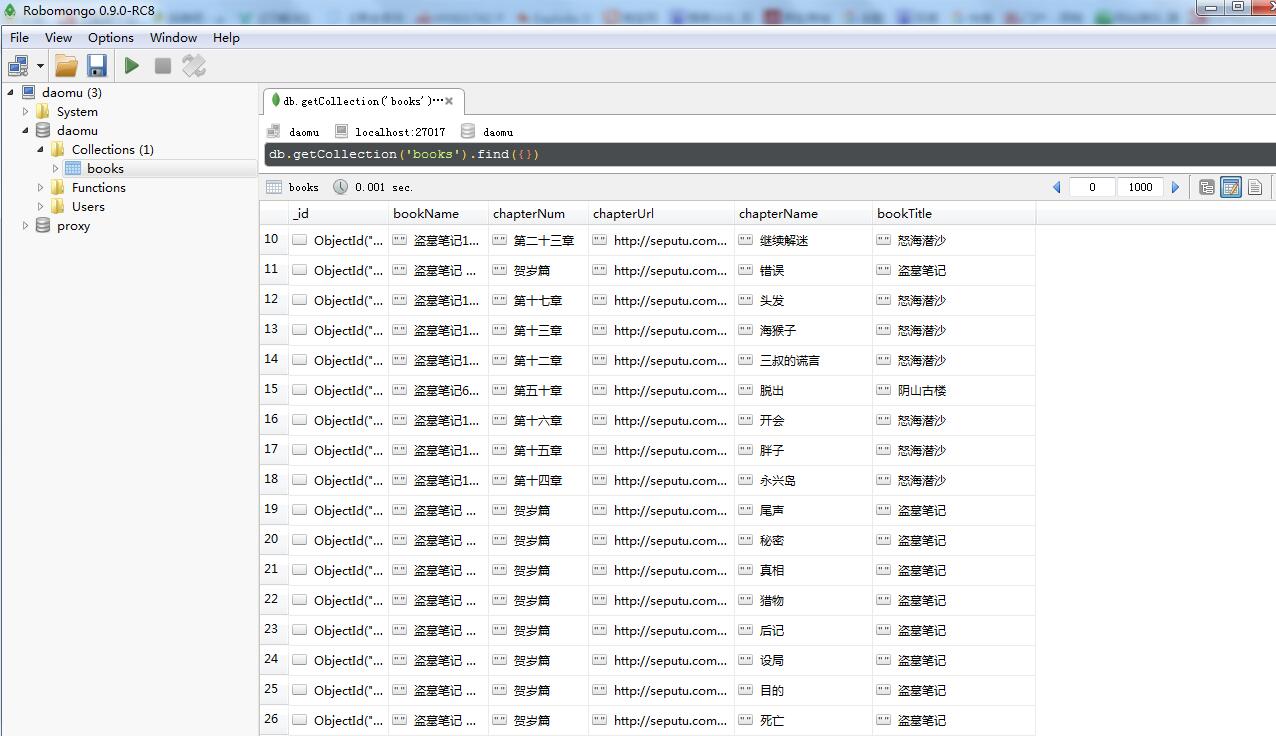
这次咱们要把书的名称,章节,章节名称,章节链接抽取出来,存储到数据库中,同时将文章的内容提取出来存成txt文件。
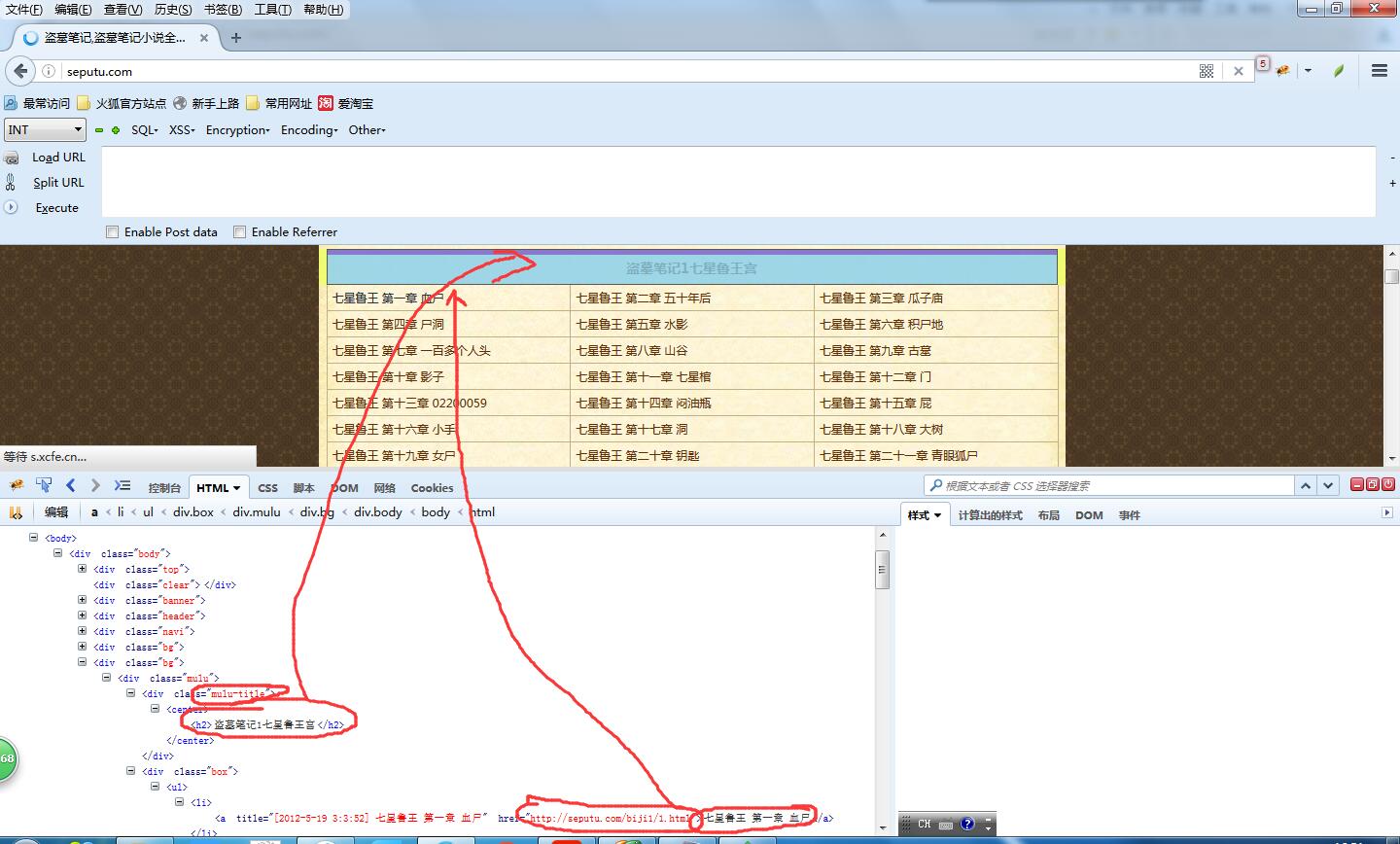
看一下html结构就会发现这个页面结构非常分明,标题的html节点是 div class = ''mulu-title",章节的节点是 div class= "box" ,每一章的节点是 div class= "box"中的<li>标签。
然后咱们将第一章的链接 http://seputu.com/biji1/1.html打开,上面就是文章的内容。
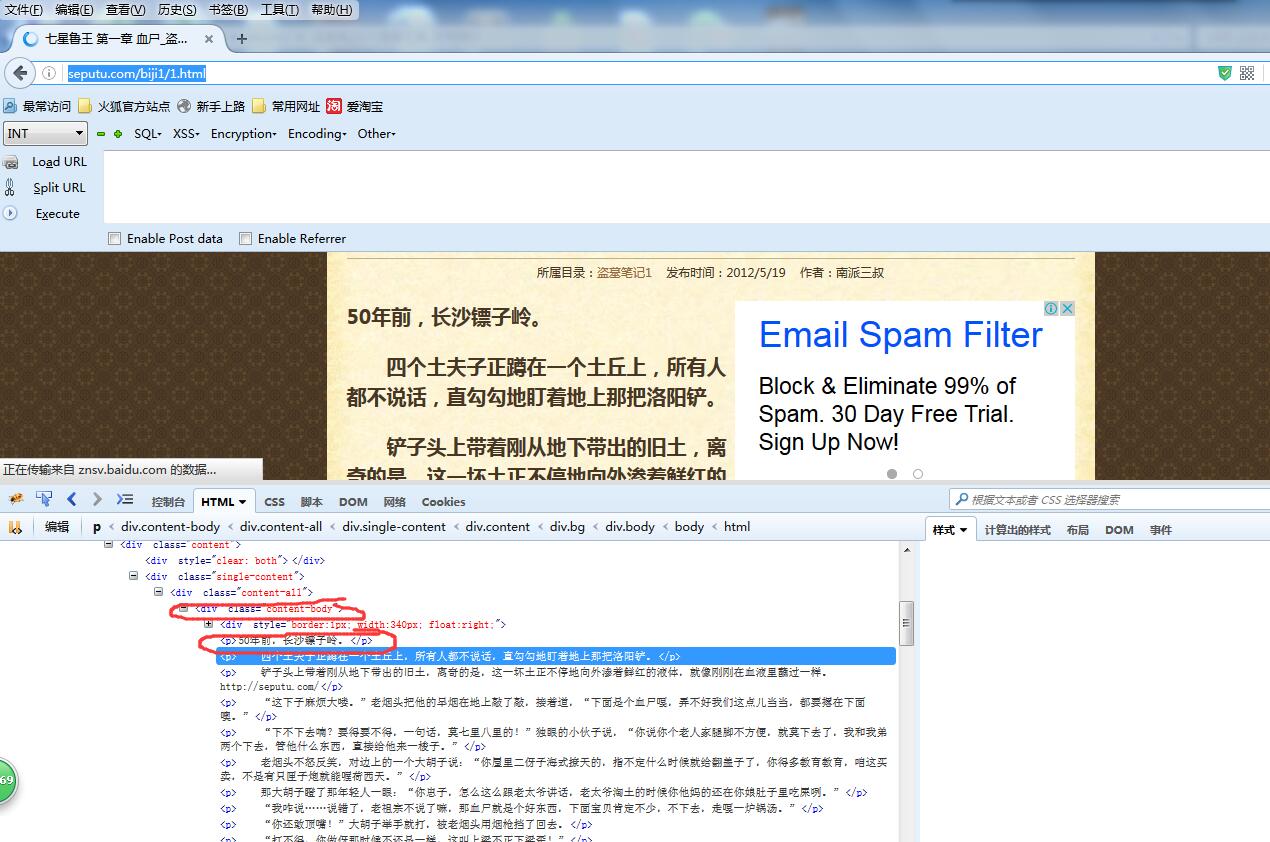
可以看到文章的内容是使用 div class ="content-body"中的<p>标签包裹起来的,总体来说提取难度挺小。
打开cmd,输入scrapy startproject daomubiji,这时候会生成一个工程,然后我把整个工程复制到pycharm中
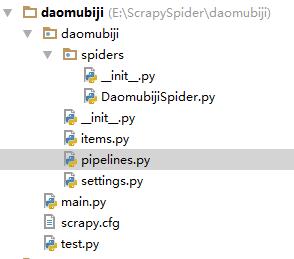
上图就是工程的结构。
DaomubijiSpider.py ------Spider 蜘蛛
items.py -----------------对要爬取数据的模型定义
pipelines.py-------------处理要存储的数据(存到数据库和写到文件)
settings.py----------------对Scrapy的配置
main.py -------------------启动爬虫
test.py -------------------- 测试程序(不参与整体运行)
下面将解析和存储的代码贴一下,完整代码已上传到github:https://github.com/qiyeboy/daomuSpider。
DaomubijiSpider.py (解析html)
#coding:utf-8
import scrapy
from scrapy.selector import Selector
from daomubiji.items import DaomubijiItem class daomuSpider(scrapy.Spider):
name = "daomu"
allowed_domains = ["seputu.com"]
start_urls = ["http://seputu.com/"]
''.split() def parse(self, response):
selector = Selector(response)
mulus= selector.xpath("//div[@class='mulu']/div[@class='mulu-title']/center/h2/text()").extract()#将目录提取出来
boxs = selector.xpath("//div[@class='mulu']/div[@class='box']")#.extract()
for i in range(len(mulus)):
mulu = mulus[i]#提取出来一个目录
box = boxs[i]#提取出来一个box
texts = box.xpath(".//ul/li/a/text()").extract()#将文本提取出来
urls = box.xpath(".//ul/li/a/@href").extract()#将链接提取出来
for j in range(len(urls)):
item = DaomubijiItem()
item['bookName'] = mulu
try:
item['bookTitle'] = texts[j].split(' ')[0]
item['chapterNum'] = texts[j].split(' ')[1]
item['chapterName'] = texts[j].split(' ')[2]
item['chapterUrl'] = urls[j]
request = scrapy.Request(urls[j],callback=self.parseBody)
request.meta['item'] = item
yield request except Exception,e:
print 'excepiton',e
continue def parseBody(self,response):
'''
解析小说章节中的内容
:param response:
:return:
'''
item = response.meta['item']
selector = Selector(response) item['chapterContent'] ='\r\n'.join(selector.xpath("//div[@class='content-body']/p/text()").extract())
yield item
pipelines.py:(处理要存储的数据) # -*- coding: utf-8 -*- # Define your item pipelines here
#
# Don't forget to add your pipeline to the ITEM_PIPELINES setting
# See: http://doc.scrapy.org/en/latest/topics/item-pipeline.html
import os
from scrapy.pipelines.files import FilesPipeline
from daomubiji import settings
from pymongo import MongoClient class DaomubijiPipeline(object):
def process_item(self, item, spider):#将小说进行存储
dir_path = '%s/%s/%s'%(settings.FILE_STORE,spider.name,item['bookName']+'_'+item['bookTitle'])#存储路径
print 'dir_path',dir_path
if not os.path.exists(dir_path):
os.makedirs(dir_path)
file_path = '%s/%s'%(dir_path,item['chapterNum']+'_'+item['chapterName']+'.txt')
with open(file_path,'w') as file_writer:
file_writer.write(item['chapterContent'].encode('utf-8'))
file_writer.write('\r\n'.encode('utf-8')) file_writer.close()
return item class DaomuSqlPipeline(object): def __init__(self):
#连接mongo数据库,并把数据存储
client = MongoClient()#'mongodb://localhost:27017/'///'localhost', 27017///'mongodb://tanteng:123456@localhost:27017/'
db = client.daomu
self.books = db.books def process_item(self, item, spider):
print 'spider_name',spider.name
temp ={'bookName':item['bookName'],
'bookTitle':item['bookTitle'],
'chapterNum':item['chapterNum'],
'chapterName':item['chapterName'],
'chapterUrl':item['chapterUrl']
}
self.books.insert(temp) return item

接下来切换到main.py所在目录,运行python main.py启动爬虫。
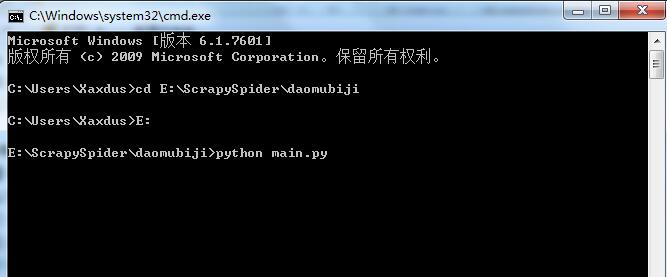
没过几分钟,爬虫就结束了,咱们看一下爬取的数据和文件。
数据库数据:
今天的分享就到这里,如果大家觉得还可以呀,记得推荐呦。

欢迎大家支持我公众号:

本文章属于原创作品,欢迎大家转载分享。尊重原创,转载请注明来自:七夜的故事 http://www.cnblogs.com/qiyeboy/
python爬虫-爬取盗墓笔记的更多相关文章
- Python爬虫爬取全书网小说,程序源码+程序详细分析
Python爬虫爬取全书网小说教程 第一步:打开谷歌浏览器,搜索全书网,然后再点击你想下载的小说,进入图一页面后点击F12选择Network,如果没有内容按F5刷新一下 点击Network之后出现如下 ...
- Python爬虫 - 爬取百度html代码前200行
Python爬虫 - 爬取百度html代码前200行 - 改进版, 增加了对字符串的.strip()处理 源代码如下: # 改进版, 增加了 .strip()方法的使用 # coding=utf-8 ...
- 用Python爬虫爬取广州大学教务系统的成绩(内网访问)
用Python爬虫爬取广州大学教务系统的成绩(内网访问) 在进行爬取前,首先要了解: 1.什么是CSS选择器? 每一条css样式定义由两部分组成,形式如下: [code] 选择器{样式} [/code ...
- 使用Python爬虫爬取网络美女图片
代码地址如下:http://www.demodashi.com/demo/13500.html 准备工作 安装python3.6 略 安装requests库(用于请求静态页面) pip install ...
- Python爬虫|爬取喜马拉雅音频
"GOOD Python爬虫|爬取喜马拉雅音频 喜马拉雅是知名的专业的音频分享平台,用户规模突破4.8亿,汇集了有声小说,有声读物,儿童睡前故事,相声小品等数亿条音频,成为国内发展最快.规模 ...
- python爬虫爬取内容中,-xa0,-u3000的含义
python爬虫爬取内容中,-xa0,-u3000的含义 - CSDN博客 https://blog.csdn.net/aiwuzhi12/article/details/54866310
- python爬虫—爬取英文名以及正则表达式的介绍
python爬虫—爬取英文名以及正则表达式的介绍 爬取英文名: 一. 爬虫模块详细设计 (1)整体思路 对于本次爬取英文名数据的爬虫实现,我的思路是先将A-Z所有英文名的连接爬取出来,保存在一个cs ...
- 一个简单的python爬虫,爬取知乎
一个简单的python爬虫,爬取知乎 主要实现 爬取一个收藏夹 里 所有问题答案下的 图片 文字信息暂未收录,可自行实现,比图片更简单 具体代码里有详细注释,请自行阅读 项目源码: # -*- cod ...
- python爬虫-爬取百度图片
python爬虫-爬取百度图片(转) #!/usr/bin/python# coding=utf-8# 作者 :Y0010026# 创建时间 :2018/12/16 16:16# 文件 :spider ...
随机推荐
- [USACO11JAN]Roads and Planes
嘟嘟嘟 这道题他会卡spfa,不过据说加SLF优化后能过,但还是讲讲正解吧. 题中有很关键的一句,就是无向边都是正的,只有单向边可能会有负的.当把整个图缩点后,有向边只会连接在每一个联通块之间(因为图 ...
- SpringBoot实战(十三)之缓存
什么是缓存? 引用下百度百科的解释: 缓存就是数据交换的缓冲区(又称作Cache),当某一硬件要读取数据时,会首先从缓存中查找需要的数据,找到了则直接执行,找不到的话则从内存中查找.由于缓存的运行速度 ...
- ionic 入门创建第一个应用demo
一.ionic卸载 1.清除旧版本的ionic框架 npm uninstall -g ionic npm uninstall -g cordova npm cache clear npm cache ...
- utils.js文件;一些常用方法的备份
一些常用方法备份: function _(value) { value = '0' + value; return value.substr(value.length - 2); } Date.pro ...
- 利用matplotlib绘画出二特征的散点图
实例的所有数据来源于吴恩达教授的机器学习数据,特此感谢.数据源可以前往course下载. 本文主要目地在于绘画二维的散点图,至于scatter的用法可以参见我之前的博客. import pandas ...
- NMON监控linux性能
NMON监控linux性能 一.下载nmon压缩包,下载地址:http://download.csdn.net/download/fhqsse220/6699865 二.安装方法: 1.将nmon_l ...
- Redis基本讲解
Redis基本讲解 首先我们要了解redis的使用试用范围,redis不像数据库能建立关系型的数据结构,除了有序集合能关联一个double类型的分数其它的几种都是单一存储的,所以他的局限性就比较高了, ...
- ORA-10485: Real-Time Query cannot be enabled while applying migration redo
情景:利用Dataguard滚动方式升级数据库后,备库应用redo报错:ORA-10485 MRP0: Background Media Recovery terminated with error ...
- android学习:关于RelativeLayout叠放布局的问题
RelativeLayout布局关于元素叠加的问题 1.RelativeLayout布局中的元素如果要实现元素叠加必须设置 RelativeLayout.ALIGN_PARENT_TOP 这样元素 ...
- FMDB数据库使用
创建数据库路径 NSString* docsdir = [NSSearchPathForDirectoriesInDomains( NSDocumentDirectory, NSUserDomainM ...