ZooKeeper学习之路 (十)Hadoop的HA集群的机架感知
一、背景
Hadoop 的设计目的:解决海量大文件的处理问题,主要指大数据的存储和计算问题,其中, HDFS 解决数据的存储问题;MapReduce 解决数据的计算问题
Hadoop 的设计考虑:设计分布式的存储和计算解决方案架构在廉价的集群之上,所以,服 务器节点出现宕机的情况是常态。数据的安全是重要考虑点。HDFS 的核心设计思路就是对 用户存进 HDFS 里的所有数据都做冗余备份,以此保证数据的安全
那么 Hadoop 在设计时考虑到数据的安全,数据文件默认在 HDFS 上存放三份。显然,这三 份副本肯定不能存储在同一个服务器节点。那怎么样的存储策略能保证数据既安全也能保证 数据的存取高效呢?
HDFS 分布式文件系统的内部有一个副本存放策略:以默认的副本数=3 为例:
1、第一个副本块存本机
2、第二个副本块存跟本机同机架内的其他服务器节点
3、第三个副本块存不同机架的一个服务器节点上
好处:
1、如果本机数据损坏或者丢失,那么客户端可以从同机架的相邻节点获取数据,速度肯定 要比跨机架获取数据要快。
2、如果本机所在的机架出现问题,那么之前在存储的时候没有把所有副本都放在一个机架 内,这就能保证数据的安全性,此种情况出现,就能保证客户端也能取到数据
HDFS 为了降低整体的网络带宽消耗和数据读取延时,HDFS 集群一定会让客户端尽量去读取 近的副本,那么按照以上头解释的副本存放策略的结果:
1、如果在本机有数据,那么直接读取
2、如果在跟本机同机架的服务器节点中有该数据块,则直接读取
3、如果该 HDFS 集群跨多个数据中心,那么客户端也一定会优先读取本数据中心的数据
但是 HDFS 是如何确定两个节点是否是统一节点,如何确定的不同服务器跟客户端的远近呢? 答案就是机架感知。!!!!
在默认情况下,HDFS 集群是没有机架感知的,也就是说所有服务器节点在同一个默认机架 中。那也就意味着客户端在上传数据的时候,HDFS 集群是随机挑选服务器节点来存储数据 块的三个副本的。
那么假如,datanode1 和 datanode3 在同一个机架 rack1,而 datanode2 在第二个机架 rack2, 那么客户端上传一个数据块 block_001,HDFS 将第一个副本存放在 dfatanode1,第二个副本 存放在 datanode2,那么数据的传输已经跨机架一次(从 rack1 到 rack2),然后 HDFS 把第三 个副本存 datanode3,此时数据的传输再跨机架一次(从 rack2 到 rack1)。显然,当 HDFS 需 要处理的数据量比较大的时候,那么没有配置机架感知就会造成整个集群的网络带宽的消耗 非常严重。
下图是没有配置机架感知的 HDFS 集群拓扑:
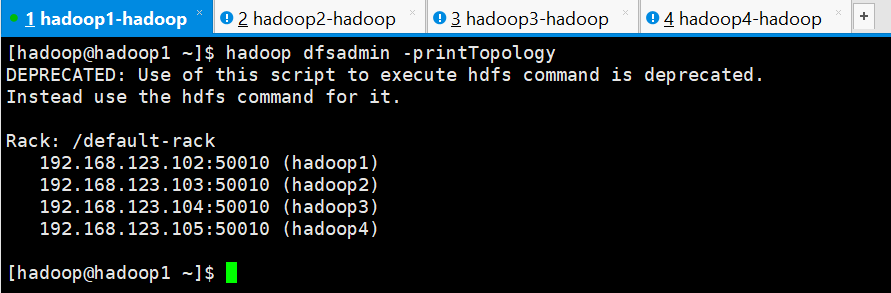
二、配置机架感知
2.1、修改配置文件 core-site.xml
给 NameNode 节点的 core-site.xml 配置文件增加一项配置:
<property>
<name>topology.script.file.name</name>
<value>/home/hadoop/apps/hadoop-2.7./etc/hadoop/topology.sh</value>
</property>
这个配置项的 value 通常是一个执行文件,该执行文件是一个 shell 脚本 topology.sh,
该脚本 接收一个参数,输出一个值。
接收的参数:datanode 节点的 IP 地址,比如:192.168.123.102
输出值:datanode 节点所在的机架配置信息,比如:/switch1/rack1
Namenode 启动时,会判断该配置选项是否为空,如果非空,则表示已经启用机架感知的配 置,此时 namenode 会根据配置寻找该脚本,并在接收到每一个 datanode 的 heartbeat 时,将该 datanode 的 ip 地址作为参数传给该脚本运行,并将得到的输出作为该 datanode 所属的 机架 ID,保存到内存的一个 map 中. 至于脚本的编写,就需要将真实的网络拓朴和机架信息了解清楚后,通过该脚本能够将机器 的 ip 地址和机器名正确的映射到相应的机架上去。一个简单的实现如下:
topology.sh
#!/bin/bash
HADOOP_CONF=/home/hadoop/apps/hadoop-2.7./etc/hadoop
while [ $# -gt ] ;
do
nodeArg=$
exec<${HADOOP_CONF}/topology.data
result=""
while read line
do
ar=( $line )
if [ "${ar[0]}" = "$nodeArg" ]||[ "${ar[1]}" = "$nodeArg" ]
then
result="${ar[2]}"
fi
done
shift
if [ -z "$result" ]
then
echo -n "/default-rack"
else
echo -n "$result"
fi
done
那么通过阅读脚本内容知道,我们需要准备一个 topology.data 的文件。topology.data 的内容 如下:
192.168.123.102 hadoop1 /switch1/rack1
192.168.123.103 hadoop2 /switch1/rack1
192.168.123.104 hadoop3 /switch2/rack2
192.168.123.105 hadoop4 /switch2/rack2
在自己对应的hadoop配置目录添加这两个文件,其中 switch 表示交换机,rack 表示机架 需要注意的是,在 Namenode 上,该文件中的节点必须使用 IP,使用主机名无效,而 ResourceManager 上,该文件中的节点必须使用主机名,使用 IP 无效,所以,最好 IP 和主 机名都配上。
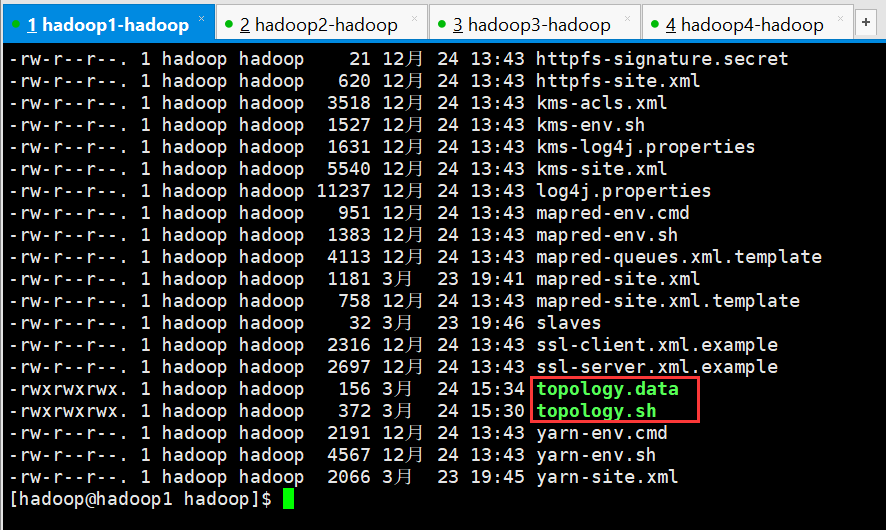
注意:以上两个文件都需要添加可执行权限
[hadoop@hadoop1 hadoop]$ chmod 777 topology.data topology.sh
2.2、验证机架感知
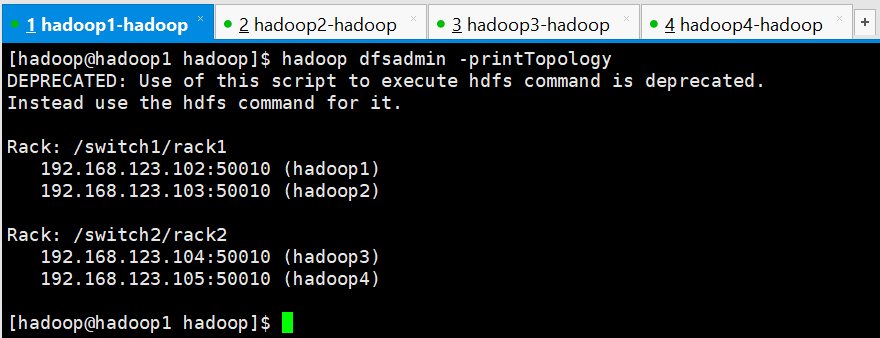
以上配置做好之后,启动集群,启动完集群之后,在使用命令:
[hadoop@hadoop1 hadoop]$ hadoop dfsadmin -printTopology
DEPRECATED: Use of this script to execute hdfs command is deprecated.
Instead use the hdfs command for it. Rack: /switch1/rack1
192.168.123.102: (hadoop1)
192.168.123.103: (hadoop2) Rack: /switch2/rack2
192.168.123.104: (hadoop3)
192.168.123.105: (hadoop4) [hadoop@hadoop1 hadoop]$
三、补充
3.1、增加 datanode 节点
增加 datanode 节点,不需要重启 namenode 非常简单的做法:在 topology.data 文件中加入新加 datanode 的信息,然后启动起来就 OK
3.2、节点间距离计算
有了机架感知,NameNode就可以画出下图所示的datanode网络拓扑图。
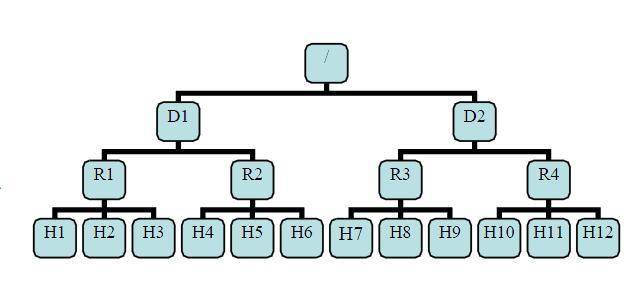
D1,R1都是交换机, 最底层Hx是 datanode。则 H1 的 rackid=/D1/R1/H1,H1 的 parent 是 R1,R1 的是 D1。这些 rackid 信息可以通过 topology.script.file.name 配置。有了这些 rackid 信息就可以计算出任意两台 datanode 之间的距离,得到最优的存放策略,优化整个集群的网络带宽均衡以及数据最优分配。
distance(/D1/R1/H1,/D1/R1/H1)= 相同的 datanode
distance(/D1/R1/H1,/D1/R1/H2)= 同一 rack 下的不同 datanode
distance(/D1/R1/H1,/D1/R2/H4)= 同一 IDC 下的不同 datanode
distance(/D1/R1/H1,/D2/R3/H7)= 不同 IDC 下的 datanode
写文件时根据策略输入 dn 节点列表,读文件时按与client由近到远距离返回 dn 列表
ZooKeeper学习之路 (十)Hadoop的HA集群的机架感知的更多相关文章
- Hadoop的HA集群启动和停止流程
假设我们有3台虚拟机,主机名分别是hadoop01.hadoop02和hadoop03. 这3台虚拟机的Hadoop的HA集群部署计划如下: 3台虚拟机的Hadoop的HA集群部署计划 hadoop0 ...
- ZooKeeper学习之路 (九)利用ZooKeeper搭建Hadoop的HA集群
Hadoop HA 原理概述 为什么会有 hadoop HA 机制呢? HA:High Available,高可用 在Hadoop 2.0之前,在HDFS 集群中NameNode 存在单点故障 (SP ...
- hadoop namenode HA集群搭建
hadoop集群搭建(namenode是单点的) http://www.cnblogs.com/kisf/p/7456290.html HA集群需要zk, zk搭建:http://www.cnblo ...
- hadoop搭建HA集群之后不能自动切换namenode
在搭好HA集群之后,想测试一下集群的高可用性,于是先把active的namenode给停掉: hadoop-daemon.sh stop namenode 或者直接kill掉该节点namenode的对 ...
- hadoop学习通过虚拟机安装hadoop完全分布式集群
要想深入的学习hadoop数据分析技术,首要的任务是必须要将hadoop集群环境搭建起来,可以将hadoop简化地想象成一个小软件,通过在各个物理节点上安装这个小软件,然后将其运行起来,就是一个had ...
- hadoop yarn HA集群搭建
可先完成hadoop namenode HA的搭建:http://www.cnblogs.com/kisf/p/7458519.html 搭建yarnde HA只需要在namenode HA配置基础上 ...
- HBase学习之路 (二)HBase集群安装
前提 1.HBase 依赖于 HDFS 做底层的数据存储 2.HBase 依赖于 MapReduce 做数据计算 3.HBase 依赖于 ZooKeeper 做服务协调 4.HBase源码是java编 ...
- HBase 学习之路(四)—— HBase集群环境配置
一.集群规划 这里搭建一个3节点的HBase集群,其中三台主机上均为Regin Server.同时为了保证高可用,除了在hadoop001上部署主Master服务外,还在hadoop002上部署备用的 ...
- 搭建hadoop的HA集群模式(hadoop2.7.3+hive+spark)
参考:http://blog.51cto.com/12824426/2177663?source=drh 一.集群的规划 Zookeeper集群:192.168.176.131 (bigdata112 ...
随机推荐
- DUBBO监控,设置接口调用数据的上报周期
目录 DUBBO监控,设置接口调用数据的上报周期 dubbo已有的监控方案 针对已有方案的改进 DUBBO监控,设置接口调用数据的上报周期 dubbo是目前比较好用的,用来实现soa架构的一个工具,d ...
- mysql中的坑
1,MySQL建表中double类型不能限制数据长度! 2,……
- Java异常(一)Java异常简介及其框架
Java异常(一)Java异常简介及其框架 概要 本章对Java中的异常进行介绍.内容包括:Java异常简介Java异常框架 Java异常简介 Java异常是Java提供的一种识别及响应错误的一致性机 ...
- 从api接口获取数据-okhttp
首先先介绍下api接口: API:应用程序接口(API:Application Program Interface) 通常用于数据连接,调用函数提供功能等等... 从api接口获取数据有四种方式:Ht ...
- Docker部署golang微服务项目
这篇博客是为了记录一下部署步骤. 因为实训需要,我要在服务器上用docker部署我们小组的微服务项目.我们的微服务有Gateway,User,Scene,Device四个部分,分别占用不同的端口,其中 ...
- time模块,计算时间差
计算当前时间与所输入的时间的时间差 #1 计算当前时间的时间戳时间 t_now = time.time() # 计算以前的时间的时间戳时间 t_before = input('请输入时间(例如:200 ...
- 【代码笔记】iOS-archive保存图片到本地
一,工程图: 二,代码: RootViewController.h #import <UIKit/UIKit.h> @interface RootViewController : UIVi ...
- DBFlow(4.2)新版使用
DBFlow新版使用 一.DBFlow4.2.4介绍 DBFlow是一个基于AnnotationProcessing(注解处理器)的ORM框架.此框架设计为了速度.性能和可用性.消除了大量死板的数据库 ...
- redis 数据淘汰策略与配置
redis 数据淘汰策略 volatile-lru:从已设置过期的数据集中挑选最近最少使用的淘汰volatile-ttr:从已设置过期的数据集中挑选将要过期的数据淘汰volatile-random:从 ...
- vuejs code splitting with webpack 3种模式
我们知道一个web app如果太大会严重影响用户的体验,如何能够最快速度地让用户看到完整页面是优化web应用需要做的重要工作. 这其中使用code split实现lazy加载,只让用户初次访问时只加载 ...