5.聚类算法k-means
聚类与分类的区别在于,是在没有给定划分类别的情况下,更具数据相似度进行样本分组的一种办法,是一种非监督的学习算法,聚类的输入时一组未被标记的样本,聚类更具数据自身的距离或者相似度将其划分为若干组,划分的原则是组内距离最小化,而组间(外部)距离最大化。
聚类中的k-means算法
1. k-means工作过程:
下述图片均来自网络

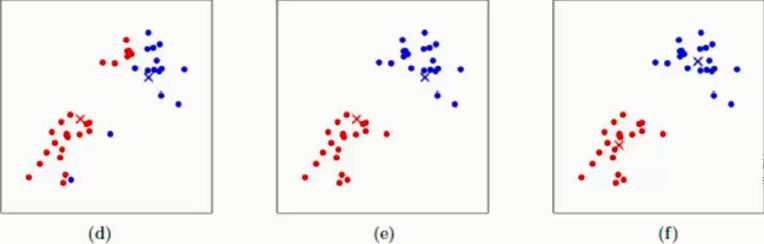
(a)表示两类点
(b)表示随机选取两个点作为中心点
(c)表示测点上述两类点到我们在(b)中随机选定的红色×和蓝色×之间的距离,离哪个中心点近就归为相应的类别,在(c)中我们就已经将上述两类点进行分为两类
(d)在上述c的基础上利用红色圆点重新计算红色类的中心点,蓝色同理就会得到如(d)图所示的红×与蓝×,此时中心点即得到了一次更新
(e)以(d)中确定的中心点再次计算所有样本点到(d)中心点的距离,离哪个中性点近就归为相应类别即得到了(e)中的分类效果
(f)和(d)同样的方式再次利用新的类别的样本点更新中心点
如上述步骤:不断迭代直至聚类的中心点不在发生变化,或者每个样本到对应聚类中心的距离之和不再有很大变化即可停止,聚类任务结束
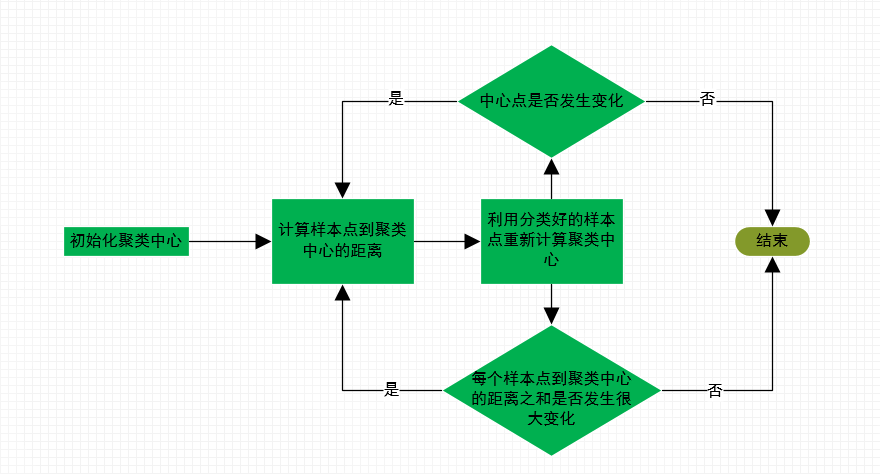
2. k-means算法注意点
2.1 我们在初始化聚类中心时,有如下两种办法:
(1)随机初始化k个和样本点维度相同的向量
(2)随机在选择k个不同的样本点作为初始的聚类中心
我们所选定的初始聚类中心会对我们模型最终的聚类结果有一定的影响,我们可以通过下述方法,将初始聚类中心对聚类结果的影响程度最小
(1)多次初始化,最终参考多次运行的结果取平均
(2)在样本点中选择初始聚类中心时,使得所选择的聚类中心之间离的尽量远
2.2 在面对一些问题的时候,我们并不知道它们的类别,所以k值的确定至关重要
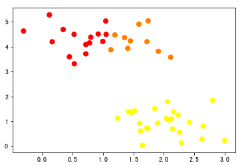

如上图,可以知道k值选择不合适,聚类的结果往往是没有意义的,故我们要选择不同的k值进行测试
2.3 k-means聚类的局限性
如下图所示,此类样本点,k-means无法完成准确聚类,此类样本分布规律,我们可以用DBSCAN算法(即基于高密度连接区域)进行聚类
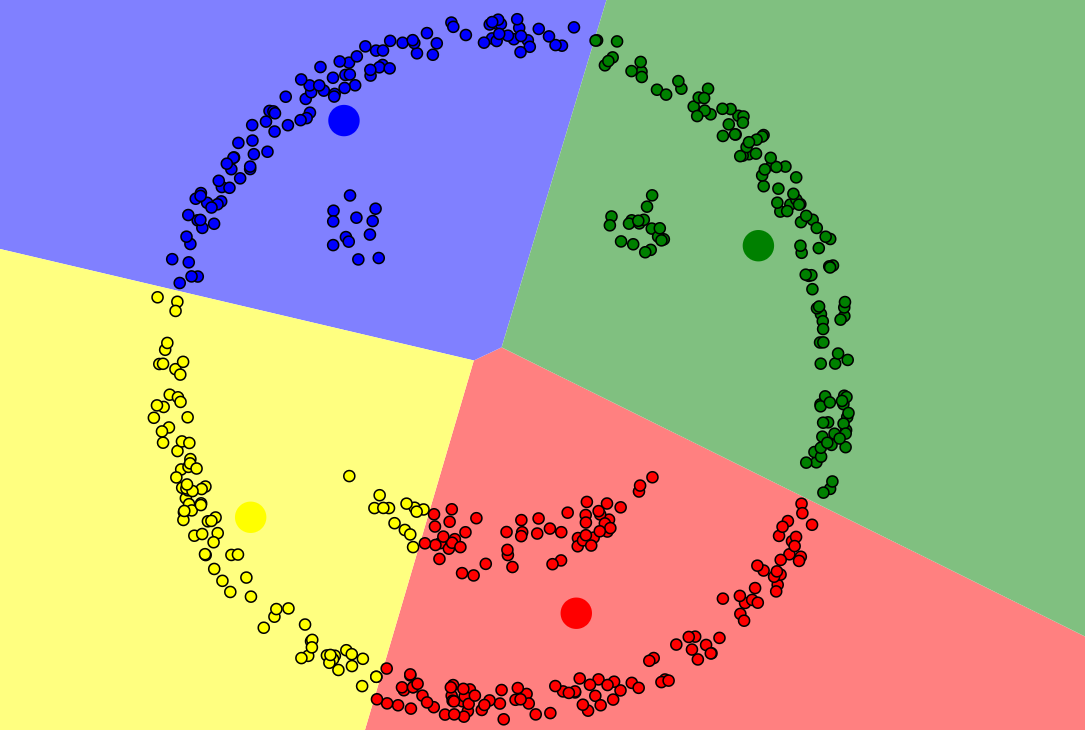
3. k-means原理的python代码实现过程如下:
import numpy as np
import matplotlib.pyplot as plt from sklearn.datasets.samples_generator import make_blobs
'''
利用sklearn随机生成数据,这里注意利用make_blobs生成的原本为分类问题,在此处我们忽略标记y,只考虑X
即为一个聚类问题
'''
X,y = make_blobs(n_samples=50,centers=2,random_state=0,cluster_std=0.5)
# 通过观察散点图,上下各为一个类别
plt.scatter(X[:,0],X[:,1])
# 聚类前样本点的散点图
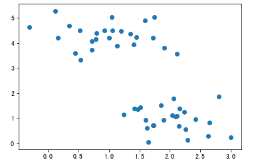
# 测量欧式距离,对样本点依据中心点分类
def sample_classify(sample_data,centerPoint):
'''
sample_classify:计算所有样本点到中心点的距离,并对样本点进行分类
参数:sample_data:某一样本点数据
centerpoint:k-means算法中心点
'''
# 计算样本数据到第一个中心点的欧氏距离
mindist = np.linalg.norm(sample_data-centerPoint[0,:-1])
# n 表示中心点的个数
n = centerPoint.shape[0]
# lagel表示中心点所代表的类别
label = centerPoint[0,-1]
for i in range(1,n):
# 计算样本点到剩余中心点的欧式距离
dist = np.linalg.norm(sample_data-centerPoint[i,:-1])
# 比较剩余中心点到样本距离与第一个中心点到样本点的距离
if dist < mindist:
mindist = dist
label = centerPoint[i,-1]
# 返回类别
return label # 定义模型停止策略
def interation_stop(iterations,centerPoint,oldcenterPoint,maxIt):
'''
interation_stop:定义停止策略,1.迭代次数到达设定值,2.中心点不在移动
参数:iterations:迭代次数
centerPoint:本次中心点
oldcenterPoint:上次中心点
maxIt:预设的迭代次数
'''
# 当迭代次数大于或者等于我们预设的迭代次数时停止
if iterations >= maxIt:
print('-------------')
return True
# 判断两次中心点是否相等
return np.array_equal(oldcenterPoint, centerPoint) # 更新中心点
def get_centerPoint(dataSet,k):
'''
get_centerPoint:更新中心点,当数据被分好类以后,根据已经分好类的数据重新计算中心点,然后再次重复以上的步骤对数据进行
参数:dataSet:已经经过聚类的数据集
k:类别个数
'''
#初始化一个k行,数据维度列的一个array
result = np.zeros((k,dataSet.shape[1]))
for i in range(1,k+1):
# 找出同一类别的数据
oneCluster = dataSet[dataSet[:,-1]==i,:-1]
# 计算同一类别数据各个维度的均值,即计算出新的中心点
result[i-1,:-1] = np.mean(oneCluster,axis=0)
# 给定类别
result[i-1,-1] = i
return result def main():
#orig_data = np.array([[1,1],[2,1],[4,3],[5,4]])
# 初始化数据
orig_data = X
# 将数据形式又array转化成matrix
data = np.mat(orig_data)
# 初始化k值即类别
k = 2
# num表示样本个数,dim表示每一个样本的维度
num,dim = data.shape
# 初始化一个新的数组用于存放原数据与对应类别
dataSet = np.zeros((num,dim+1))
# 将原始数据填入新的数据
dataSet[:,:-1] = data
# 随机选取的中心点
centerPoint = dataSet[np.random.randint(num,size=k),:]
centerPoint[:,-1] = range(1,k+1)
oldcenterPoint = None
iterations = 0
# 指定迭代次数
maxIt = 1000
# 停止策略未false时循环
while not interation_stop(iterations,centerPoint,oldcenterPoint,maxIt):
for i in range(num):
# 取出样本点
sample_data = dataSet[i,:-1]
# 利用之前定义好的函数计算每一个样本点到中心点距离,并对样本点进行分类
dataSet[i,-1] = sample_classify(sample_data,centerPoint)
# 记录此次计算的中心点
oldcenterPoint = np.copy(centerPoint)
# 更新中心点
centerPoint = get_centerPoint(dataSet,k)
# 记录迭代次数
iterations += 1
#print(dataSet)
# y表示已经确定好的类别
y = dataSet[:,2]
# 画出散点图,观察聚类效果
plt.scatter(dataSet[:,0],dataSet[:,1],c=y,s=50,cmap='autumn') if __name__ == '__main__':
main()
# 聚类后样本点的散点图
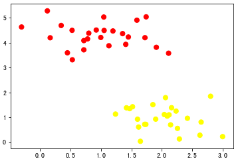
5.聚类算法k-means的更多相关文章
- ML: 聚类算法-K均值聚类
基于划分方法聚类算法R包: K-均值聚类(K-means) stats::kmeans().fpc::kmeansruns() K-中心点聚类(K-Medoids) ...
- 聚类算法:K均值、凝聚层次聚类和DBSCAN
聚类分析就仅根据在数据中发现的描述对象及其关系的信息,将数据对象分组(簇).其目标是,组内的对象相互之间是相似的,而不同组中的对象是不同的.组内相似性越大,组间差别越大,聚类就越好. 先介绍下聚类的不 ...
- 常见聚类算法——K均值、凝聚层次聚类和DBSCAN比较
聚类分析就仅根据在数据中发现的描述对象及其关系的信息,将数据对象分组(簇).其目标是,组内的对象相互之间是相似的,而不同组中的对象是不同的.组内相似性越大,组间差别越大,聚类就越好. 先介绍下聚类的不 ...
- 软件——机器学习与Python,聚类,K——means
K-means是一种聚类算法: 这里运用k-means进行31个城市的分类 城市的数据保存在city.txt文件中,内容如下: BJ,2959.19,730.79,749.41,513.34,467. ...
- 【机器学习】聚类算法——K均值算法(k-means)
一.聚类 1.基于划分的聚类:k-means.k-medoids(每个类别找一个样本来代表).Clarans 2.基于层次的聚类:(1)自底向上的凝聚方法,比如Agnes (2)自上而下的分裂方法,比 ...
- 数据挖掘十大算法--K-均值聚类算法
一.相异度计算 在正式讨论聚类前,我们要先弄清楚一个问题:怎样定量计算两个可比較元素间的相异度.用通俗的话说.相异度就是两个东西区别有多大.比如人类与章鱼的相异度明显大于人类与黑猩猩的相异度,这是能 ...
- 第十三篇:K-Means 聚类算法原理分析与代码实现
前言 在前面的文章中,涉及到的机器学习算法均为监督学习算法. 所谓监督学习,就是有训练过程的学习.再确切点,就是有 "分类标签集" 的学习. 现在开始,将进入到非监督学习领域.从经 ...
- 机器学习六--K-means聚类算法
机器学习六--K-means聚类算法 想想常见的分类算法有决策树.Logistic回归.SVM.贝叶斯等.分类作为一种监督学习方法,要求必须事先明确知道各个类别的信息,并且断言所有待分类项都有一个类别 ...
- k-means均值聚类算法(转)
4.1.摘要 在前面的文章中,介绍了三种常见的分类算法.分类作为一种监督学习方法,要求必须事先明确知道各个类别的信息,并且断言所有待分类项都有一个类别与之对应.但是很多时候上述条件得不到满足,尤其是在 ...
- K-means聚类算法(转)
K-means聚类算法 想想常见的分类算法有决策树.Logistic回归.SVM.贝叶斯等.分类作为一种监督学习方法,要求必须事先明确知道各个类别的信息,并且断言所有待分类项都有一个类别与之对应.但是 ...
随机推荐
- 解决The total number of locks exceeds the lock table size错误
参考:https://blog.csdn.net/weixin_40683253/article/details/80762583 mysql在进行大批量的数据操作时,会报“The total num ...
- 大型软件公司.Net面试常见题(含答案)
1.a=10,b=15,在不用第三方变量的前提下,吧a.b互换 2.已知数组int[] max={6,5,2,9,7,4,0};用快速排序算法按降序对其进行排列,并返回数组 3.请简述面向对象的多态的 ...
- ASP.NET Core WebApi使用Swagger生成API说明文档【特性版】
⒈新建ASP.NET Core WebAPi项目 ⒉添加 NuGet 包 Install-Package Swashbuckle.AspNetCore ⒊Startup中配置 using System ...
- 面试40-一个数组,有2个数字出现奇数次,其余都是偶数次,求这两个数字O(n) O(1)
#include<iostream> using namespace std; // 题目:数组中只有不多于两个数字出现次数是奇数次,其他都是偶数次,求出出现奇数次的数字(不含0的数组) ...
- Django之cookie与session、中间件
目录 cookie与session 为什么会有cookie和session cookie 设置cookie 获取cookie 删除cookie 实例:cookie版登录校验 session 设置ses ...
- 分布式锁的几种实现方法:redis实现分布式锁
使用失效的方式实现分布式锁(推荐) import redis.clients.jedis.Jedis; /** * 使用redis实现分布式锁(推荐) * */ public class JedLoc ...
- awk--基本操作
二:awk--将一行分为数个字段处理 PS:awk [option] '条件类型 {动作1} 条件类型{动作2} ...' filename PS: awk 'Pattern {action}' fi ...
- gitlab操作笔记
基本命令 准备 1. 安装所需命令 sudo yum install curl openssh-server openssh-clients postfix cronie -y2. 安装SSH sud ...
- 如何去除List集合中的重复元素? a,b,c,a,c,b,d,,,,,,
package com.fs.test; import java.util.ArrayList; import java.util.List; public class Listdemo { publ ...
- 【转】CNN+BLSTM+CTC的验证码识别从训练到部署
[转]CNN+BLSTM+CTC的验证码识别从训练到部署 转载地址:https://www.jianshu.com/p/80ef04b16efc 项目地址:https://github.com/ker ...