scrapy爬虫框架爬取招聘网站
目录结构
BossFace.py文件中代码:
# -*- coding: utf-8 -*-
import scrapy
from ..items import BossfaceItem
import json
class BossfaceSpider(scrapy.Spider):
name = 'BossFace'
allowed_domains = ['www.zhipin.com/c101010100-p100109/?page=2']
start_urls = ['https://fe-api.zhaopin.com/c/i/sou?start=90&pageSize=90&cityId=天津&salary=0,0&workExperience=-1&education=-1&companyType=-1&employmentType=-1&jobWelfareTag=-1&kw=Python&kt=3&=0&at=081a4411244a4e9c80d393212650f005&rt=6cc8df0863c944a88cbc303fa5d7dd40&_v=0.56963230&userCode=1041847897&x-zp-page-request-id=1dba50fde35b475b99fc09aa009dbee1-1568818384291-188677&x-zp-client-id=412ece5e-7595-4148-8838-3b957ac4202a']
def parse(self, response): item = BossfaceItem()
rs = json.loads(response.text)['data']
res = dict(rs)
lis = res['results'] for i in range(0,len(lis)):
item['workName'] = lis[i]['jobName']
item['workPay'] = lis[i]['salary']
item['workPosition'] = lis[i]['city']['display']
item['degree'] = lis[i]['eduLevel']['name']
item['Company'] = lis[i]['company']['name']
yield item items.py中的代码:
# -*- coding: utf-8 -*- # Define here the models for your scraped items
#
# See documentation in:
# https://docs.scrapy.org/en/latest/topics/items.html import scrapy class BossfaceItem(scrapy.Item):
# define the fields for your item here like:
# name = scrapy.Field()
workName = scrapy.Field()
workPay = scrapy.Field()
workPosition = scrapy.Field()
degree = scrapy.Field()
Company = scrapy.Field()
workDetail = scrapy.Field()
pass
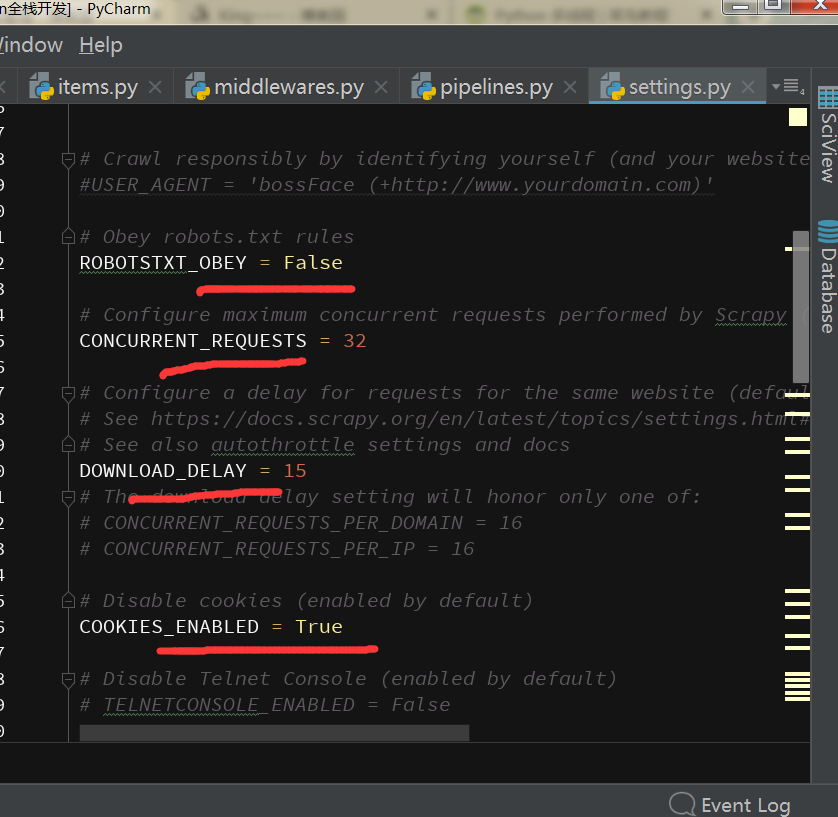
将这些开启,建立延迟,防止服务器封掉ip
在命令行创建的命令依次是:
1.scrapy startproject bossFace
2.scrapy genspider BossFace www.zhipin.com #进入spider中执行
3.scrapy crawl BossFace #进入第二级别的bossFace中执行
4.scrapy crawl BossFace -o item.json #执行目录与3相同
scrapy爬虫框架爬取招聘网站的更多相关文章
- 手把手教大家如何用scrapy爬虫框架爬取王者荣耀官网英雄资料
之前被两个关系很好的朋友拉入了王者荣耀的大坑,奈何技术太差,就想着做一个英雄的随查手册,这样就可以边打边查了.菜归菜,至少得说明咱打王者的态度是没得说的,对吧?大神不喜勿喷!!!感谢!!废话不多说,开 ...
- 初次尝试python爬虫,爬取小说网站的小说。
本次是小阿鹏,第一次通过python爬虫去爬一个小说网站的小说. 下面直接上菜. 1.首先我需要导入相应的包,这里我采用了第三方模块的架包,requests.requests是python实现的简单易 ...
- 初识python 之 爬虫:爬取某网站的壁纸图片
用到的主要知识点:requests.get 获取网页HTMLetree.HTML 使用lxml解析器解析网页xpath 使用xpath获取网页标签信息.图片地址request.urlretrieve ...
- python-scrapy爬虫框架爬取拉勾网招聘信息
本文实例为爬取拉勾网上的python相关的职位信息, 这些信息在职位详情页上, 如职位名, 薪资, 公司名等等. 分析思路 分析查询结果页 在拉勾网搜索框中搜索'python'关键字, 在浏览器地址栏 ...
- Python爬虫学习之使用beautifulsoup爬取招聘网站信息
菜鸟一只,也是在尝试并学习和摸索爬虫相关知识. 1.首先分析要爬取页面结构.可以看到一列搜索的结果,现在需要得到每一个链接,然后才能爬取对应页面. 关键代码思路如下: html = getHtml(& ...
- scrapy入门实战-爬取代理网站
入门scrapy. 学习了有这几点 1.如何使用scrapy框架对网站进行爬虫: 2.如何对网页源代码使用xpath进行解析: 3.如何书写spider爬虫文件,对源代码进行解析: 4.学会使用scr ...
- Scrapy爬虫笔记 - 爬取知乎
cookie是一种本地存储机制,cookie是存储在本地的 session其实就是将用户信息用户名.密码等)加密成一串字符串,返回给浏览器,以后浏览器每次请求都带着这个sessionId 状态码一般是 ...
- 【网络爬虫】【python】网络爬虫(五):scrapy爬虫初探——爬取网页及选择器
在上一篇文章的末尾,我们创建了一个scrapy框架的爬虫项目test,现在来运行下一个简单的爬虫,看看scrapy爬取的过程是怎样的. 一.爬虫类编写(spider.py) from scrapy.s ...
- Scrapy爬虫实战-爬取体彩排列5历史数据
网站地址:http://www.17500.cn/p5/all.php 1.新建爬虫项目 scrapy startproject pfive 2.在spiders目录下新建爬虫 scrapy gens ...
随机推荐
- Dart编程环境
本章讨论在Windows平台上为Dart设置执行环境. 使用DartPad在线执行脚本 您可以使用https://dartpad.dartlang.org/上的在线编辑器在线测试您的脚本.Dart编辑 ...
- Go 转义字符
Go 转义字符 package main import "fmt" func main() { fmt.Printf("Hello\tWorld!") } 本文 ...
- 再学 GDI+文本输出文本样式
代码文件: unit Unit1; interfaceuses Windows, Messages, SysUtils, Variants, Classes, Graphics, Controls ...
- vue中使用腾讯云Im
在vue中使用腾讯云Im 通信时,官方给出的文档及sdk提供的都是es5的写法.我们在vue中使用均需要用es6的方式来改写sdk的js文件及按自己所需要的业务调用对应的api就行了 1.对sdk的j ...
- 2019/11/8 CSP模拟
T1 药品实验 内网#4803 由概率定义,有\[a + b + c = 0\] 变形得到\[1 - b = a + c\] 根据题意有\[p_i = a p _{i - 1} + b p_i + c ...
- java.sql.SQLException: Access denied for user 'root'@'localhost' (using password: YES)
:: - [localhost-startStop-] INFO - Root WebApplicationContext: initialization started -- :: - [local ...
- Async_Study
using System; using System.Collections.Generic; using System.Linq; using System.Text; using System.T ...
- C语言进阶学习第三章
以下记录动态内存分配: 1.malloc和free malloc和free分别用于执行动态内存分配和释放.这些函数维护一个可用内存池,当一个程序需要一些内存时,调用malloc函数,malloc从内存 ...
- Windows环境下安装openface
由于昨天在学习人脸识别,就涉及到了openface 我使用的是Windows环境下的pycharm开发工具,昨天一直安装openface但就是没有相关的教程,使用pip install openfac ...
- 《转》python 12 列表解析
转自 http://www.cnblogs.com/BeginMan/p/3164937.html 一.列表解析 列表解析来自函数式编程语言(haskell),语法如下: [expr for iter ...