在Spark中尽量少使用GroupByKey函数(转)
原文链接:在Spark中尽量少使用GroupByKey函数
为什么建议尽量在Spark中少用GroupByKey,让我们看一下使用两种不同的方式去计算单词的个数,第一种方式使用reduceByKey ;另外一种方式使用groupByKey,代码如下:
01 |
# User: 过往记忆 |
02 |
# Date: 2015-05-18 |
03 |
# Time: 下午22:26 |
04 |
# bolg: http://www.iteblog.com |
05 |
# 本文地址:http://www.iteblog.com/archives/1357 |
06 |
# 过往记忆博客,专注于hadoop、hive、spark、shark、flume的技术博客,大量的干货 |
07 |
# 过往记忆博客微信公共帐号:iteblog_hadoop |
08 |
09 |
val words = Array("one", "two", "two", "three", "three", "three") |
10 |
val wordPairsRDD = sc.parallelize(words).map(word => (word, 1)) |
11 |
12 |
val wordCountsWithReduce = wordPairsRDD |
13 |
.reduceByKey(_ + _) |
14 |
.collect() |
15 |
16 |
val wordCountsWithGroup = wordPairsRDD |
17 |
.groupByKey() |
18 |
.map(t => (t._1, t._2.sum)) |
19 |
.collect() |
虽然两个函数都能得出正确的结果, 但reduceByKey函数更适合使用在大数据集上。 这是因为Spark知道它可以在每个分区移动数据之前将输出数据与一个共用的 key 结合。
借助下图可以理解在reduceByKey里发生了什么。 注意在数据对被搬移前同一机器上同样的 key 是怎样被组合的(reduceByKey中的 lamdba 函数)。然后 lamdba 函数在每个区上被再次调用来将所有值 reduce成一个最终结果。整个过程如下:
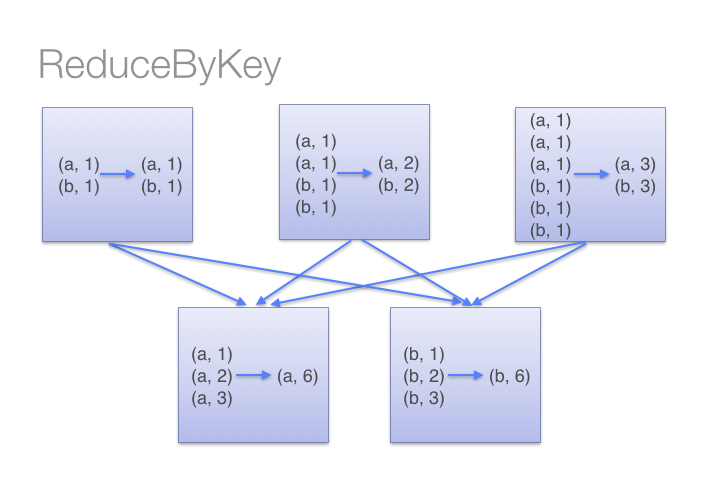
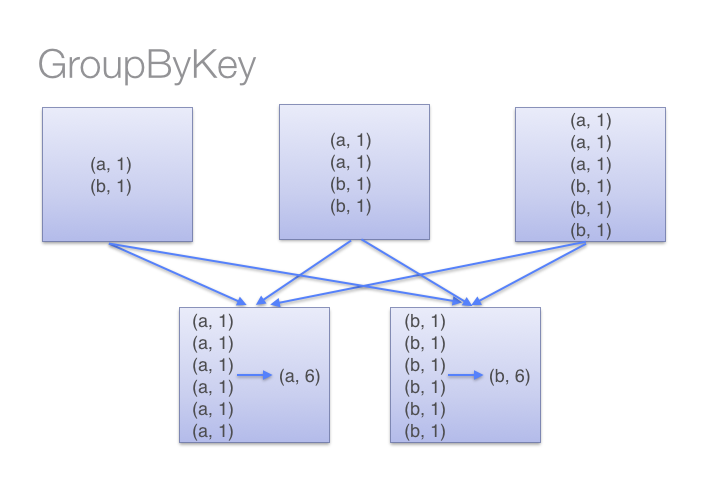
另一方面,当调用 groupByKey时,所有的键值对(key-value pair) 都会被移动。在网络上传输这些数据非常没有必要。避免使用 GroupByKey。
为了确定将数据对移到哪个主机,Spark会对数据对的 key 调用一个分区算法。 当移动的数据量大于单台执行机器内存总量时 Spark 会把数据保存到磁盘上。 不过在保存时每次会处理一个 key 的数据,所以当单个 key 的键值对超过内存容量会存在内存溢出的异常。 这将会在之后发行的 Spark 版本中更加优雅地处理,这样的工作还可以继续完善。 尽管如此,仍应避免将数据保存到磁盘上,这会严重影响性能。
如果想及时了解Spark、Hadoop或者Hbase相关的文章,欢迎关注微信公共帐号:iteblog_hadoop
你可以想象一个非常大的数据集,在使用 reduceByKey 和 groupByKey 时他们的差别会被放大更多倍。以下函数应该优先于 groupByKey :
(1)、combineByKey组合数据,但是组合之后的数据类型与输入时值的类型不一样。
(2)、foldByKey 合并每一个 key 的所有值,在级联函数和“零值”中使用。
在Spark中尽量少使用GroupByKey函数(转)的更多相关文章
- Effective Objective-C 2.0 — 第二条:类的头文件中尽量少引入其他头文件
第二条:类的头文件中尽量少引入其他头文件 使用向前声明(forward declaring) @class EOCEmployer 1, 将引入头文件的实际尽量延后,只在确有需要时才引入,这样就可以减 ...
- Spark中groupBy groupByKey reduceByKey的区别
groupBy 和SQL中groupby一样,只是后面必须结合聚合函数使用才可以. 例如: hour.filter($"version".isin(version: _*)).gr ...
- Spark 中 GroupByKey 相对于 combineByKey, reduceByKey, foldByKey 的优缺点
避免使用GroupByKey 我们看一下两种计算word counts 的方法,一个使用reduceByKey,另一个使用 groupByKey: val words = Array("on ...
- Spark学习笔记之RDD中的Transformation和Action函数
总算可以开始写第一篇技术博客了,就从学习Spark开始吧.之前阅读了很多关于Spark的文章,对Spark的工作机制及编程模型有了一定了解,下面把Spark中对RDD的常用操作函数做一下总结,以pys ...
- Scala 深入浅出实战经典 第42讲:scala 泛型类,泛型函数,泛型在spark中的广泛应用
王家林亲授<DT大数据梦工厂>大数据实战视频 Scala 深入浅出实战经典(1-64讲)完整视频.PPT.代码下载:百度云盘:http://pan.baidu.com/s/1c0noOt6 ...
- DELPHI语法基础学习笔记-Windows 句柄、回调函数、函数重载等(Delphi中很少需要直接使用句柄,因为句柄藏在窗体、 位图及其他Delphi 对象的内部)
函数重载重载的思想很简单:编译器允许你用同一名字定义多个函数或过程,只要它们所带的参数不同.实际上,编译器是通过检测参数来确定需要调用的例程.下面是从VCL 的数学单元(Math Unit)中摘录的一 ...
- Spark中的IsNotNull函数怎么用
Spark中的IsNotNull函数怎么用 在这里看到的这个函数,就是判断是否为空,但是开始不知道怎么用,后来找到了,要在View中用,也就是SparkSQL中.如下: spark.sql(" ...
- BigData进阶--Spark中的函数与符号
转自:https://blog.csdn.net/YSC1123/article/details/78905090 1.Character.isDigit() 判断是否为数字 2.Character. ...
- Spark中shuffle的触发和调度
Spark中的shuffle是在干嘛? Shuffle在Spark中即是把父RDD中的KV对按照Key重新分区,从而得到一个新的RDD.也就是说原本同属于父RDD同一个分区的数据需要进入到子RDD的不 ...
随机推荐
- Loadrunner报错“Too many local variablesAction.c”解决方法
问题描述,在Action.c里定义数组时如果数组长度过长,如char a[1024*1024]运行时即会报错: 意思为:太多的局部变量 问题原因及解决方法如下: 1. VuGen对于局部变量可以分配的 ...
- sublimetext3-实用快捷键整理
实用快捷键 Ctrl+Shift+P:打开命令面板Ctrl+P:搜索项目中的文件Ctrl+G:跳转到第几行Ctrl+W:关闭当前打开文件Ctrl+Shift+W:关闭所有打开文件Ctrl+Shift+ ...
- (10) go 错误
没有 try catch..f.. 自定义错误
- Java多线程编程——wait()和notify()、notifyAll()
1.源码 wait() notify() notifyAll()都是Object类中方法.源码如下所示: public final native void notify(); public final ...
- 图形管线之旅 Part5
原文:<A trip through the Graphics Pipeline 2011> 翻译:往昔之剑 转载请注明出处 在上一篇关于纹理采样器之后,我们现在回到了3D前端.那 ...
- COMP COMP-3
Comp (Computational) Comp (with no suffix) leaves the choice of the data type to the compiler writer ...
- shell 遍历
for file in $1/* do if [ -f $file ] then SUFFIX=${file#*BK} PREFIX=${SUFFIX%%_*} CURRENT=`date -d -7 ...
- hdu dp 1257 最小拦截系统
最少拦截系统 Time Limit:1000MS Memory Limit:32768KB 64bit IO Format:%I64d & %I64u Submit Statu ...
- Hibernate 基于外键的双向一对一关联映射
之前简单介绍了基于外键的单项一对一的关联映射关系,本文简单介绍基于外键的双向一对一的关联映射. 1.设计表结构 表结构对于双向一对一来说没有多少改变,只是双向都可以获取到对方. 2.创建Person对 ...
- [SPOJ SEQN] [hdu3439]Sequence
题目就是求C(n,k)*H(n - k)%m 0<= k<= n <=10^9, 1 <= m <= 10^5, n != 0 其中H(n)是错排第n项. 对于C(n,k ...