biancheng-Python爬虫教程
http://c.biancheng.net/python_spider/
网络爬虫又称网络蜘蛛、网络机器人,它是一种按照一定的规则自动浏览、检索网页信息的程序或者脚本。网络爬虫能够自动请求网页,并将所需要的数据抓取下来。通过对抓取的数据进行处理,从而提取出有价值的信息。
认识爬虫
我们所熟悉的一系列搜索引擎都是大型的网络爬虫,比如百度、搜狗、360浏览器、谷歌搜索等等。每个搜索引擎都拥有自己的爬虫程序,比如 360 浏览器的爬虫称作 360Spider,搜狗的爬虫叫做 Sogouspider。

百度搜索引擎,其实可以更形象地称之为百度蜘蛛(Baiduspider),它每天会在海量的互联网信息中爬取优质的信息,并进行收录。当用户通过百度检索关键词时,百度首先会对用户输入的关键词进行分析,然后从收录的网页中找出相关的网页,并按照排名规则对网页进行排序,最后将排序后的结果呈现给用户。在这个过程中百度蜘蛛起到了非常想关键的作用。
百度的工程师们为“百度蜘蛛”编写了相应的爬虫算法,通过应用这些算法使得“百度蜘蛛”可以实现相应搜索策略,比如筛除重复网页、筛选优质网页等等。应用不同的算法,爬虫的运行效率,以及爬取结果都会有所差异。
爬虫分类
爬虫可分为三大类:通用网络爬虫、聚焦网络爬虫、增量式网络爬虫。
通用网络爬虫:是搜索引擎的重要组成部分,上面已经进行了介绍,这里就不再赘述。通用网络爬虫需要遵守 robots 协议,网站通过此协议告诉搜索引擎哪些页面可以抓取,哪些页面不允许抓取。
robots 协议:是一种“约定俗称”的协议,并不具备法律效力,它体现了互联网人的“契约精神”。行业从业者会自觉遵守该协议,因此它又被称为“君子协议”。
聚焦网络爬虫:是面向特定需求的一种网络爬虫程序。它与通用爬虫的区别在于,聚焦爬虫在实施网页抓取的时候会对网页内容进行筛选和处理,尽量保证只抓取与需求相关的网页信息。聚焦网络爬虫极大地节省了硬件和网络资源,由于保存的页面数量少所以更新速度很快,这也很好地满足一些特定人群对特定领域信息的需求。
增量式网络爬虫:是指对已下载网页采取增量式更新,它是一种只爬取新产生的或者已经发生变化网页的爬虫程序,能够在一定程度上保证所爬取的页面是最新的页面。
爬虫应用
随着网络的迅速发展,万维网成为大量信息的载体,如何有效地提取并利用这些信息成为一个巨大的挑战,因此爬虫应运而生,它不仅能够被使用在搜索引擎领域,而且在大数据分析,以及商业领域都得到了大规模的应用。
1) 数据分析
在数据分析领域,网络爬虫通常是搜集海量数据的必备工具。对于数据分析师而言,要进行数据分析,首先要有数据源,而学习爬虫,就可以获取更多的数据源。在采集过程中,数据分析师可以按照自己目的去采集更有价值的数据,而过滤掉那些无效的数据。
2) 商业领域
对于企业而言,及时地获取市场动态、产品信息至关重要。企业可以通过第三方平台购买数据,比如贵阳大数据交易所、数据堂等,当然如果贵公司有一个爬虫工程师的话,就可通过爬虫的方式取得想要的信息。
爬虫是一把双刃剑
爬虫是一把双刃剑,它给我们带来便利的同时,也给网络安全带来了隐患。有些不法分子利用爬虫在网络上非法搜集网民信息,或者利用爬虫恶意攻击他人网站,从而导致网站瘫痪的严重后果。关于爬虫的如何合法使用,推荐阅读《中华人民共和国网络安全法》。
为了限制爬虫带来的危险,大多数网站都有良好的反爬措施,并通过 robots.txt 协议做了进一步说明,下面是淘宝网 robots.txt 的内容:
User-agent: Baiduspider
Disallow: /baidu Disallow: /s?
Disallow: /ulink?
Disallow: /link?
Disallow: /home/news/data/
Disallow: /bh
.....
User-agent: *
Disallow: /
从协议内容可以看出,淘宝网对不能被抓取的页面做了规定。因此大家在使用爬虫的时候,要自觉遵守 robots 协议,不要非法获取他人信息,或者做一些危害他人网站的事情。
为什么用Python做爬虫
首先您应该明确,不止 Python 这一种语言可以做爬虫,诸如 PHP、Java、C/C++ 都可以用来写爬虫程序,但是相比较而言 Python 做爬虫是最简单的。下面对它们的优劣势做简单对比:
PHP:对多线程、异步支持不是很好,并发处理能力较弱;Java 也经常用来写爬虫程序,但是 Java 语言本身很笨重,代码量很大,因此它对于初学者而言,入门的门槛较高;C/C++ 运行效率虽然很高,但是学习和开发成本高。写一个小型的爬虫程序就可能花费很长的时间。
而 Python 语言,其语法优美、代码简洁、开发效率高、支持多个爬虫模块,比如 urllib、requests、Bs4 等。Python 的请求模块和解析模块丰富成熟,并且还提供了强大的 Scrapy 框架,让编写爬虫程序变得更为简单。因此使用 Python 编写爬虫程序是个非常不错的选择。
编写爬虫的流程
爬虫程序与其他程序不同,它的的思维逻辑一般都是相似的, 所以无需我们在逻辑方面花费大量的时间。下面对 Python 编写爬虫程序的流程做简单地说明:
- 先由 urllib 模块的 request 方法打开 URL 得到网页 HTML 对象。
- 使用浏览器打开网页源代码分析网页结构以及元素节点。
- 通过 Beautiful Soup 或则正则表达式提取数据。
- 存储数据到本地磁盘或数据库。
当然也不局限于上述一种流程。编写爬虫程序,需要您具备较好的 Python 编程功底,这样在编写的过程中您才会得心应手。爬虫程序需要尽量伪装成人访问网站的样子,而非机器访问,否则就会被网站的反爬策略限制,甚至直接封杀 IP,相关知识会在后续内容介绍。
网页是怎样构成的
爬虫程序之所以可以抓取数据,是因为爬虫能够对网页进行分析,并在网页中提取出想要的数据。在学习 Python 爬虫模块前,我们有必要先熟悉网页的基本结构,这是编写爬虫程序的必备知识。
如果您熟悉前端语言,那么您可以轻松地掌握本节知识。
网页一般由三部分组成,分别是 HTML(超文本标记语言)、CSS(层叠样式表)和 JavaScript(简称“JS”动态脚本语言),它们三者在网页中分别承担着不同的任务。
- HTML 负责定义网页的内容
- CSS 负责描述网页的布局
- JavaScript 负责网页的行为
HTML
HTML 是网页的基本结构,它相当于人体的骨骼结构。网页中同时带有“<”、“>”符号的都属于 HTML 标签。常见的 HTML 标签如下所示:
<!DOCTYPE html> 声明为 HTML5 文档
<html>..</html> 是网页的根元素
<head>..</head> 元素包含了文档的元(meta)数据,如 <meta charset="utf-8"> 定义网页编码格式为 utf-8。
<title>..<title> 元素描述了文档的标题
<body>..</body> 表示用户可见的内容
<div>..</div> 表示框架
<p>..</p> 表示段落
<ul>..</ul> 定义无序列表
<ol>..</ol>定义有序列表
<li>..</li>表示列表项
<img src="" alt="">表示图片
<h1>..</h1>表示标题
<a href="">..</a>表示超链接
静态网页和动态网页
静态网页
静态网页是标准的 HTML 文件,通过 GET 请求方法可以直接获取,文件的扩展名是.html、.htm等,网面中可以包含文本、图像、声音、FLASH 动画、客户端脚本和其他插件程序等。静态网页是网站建设的基础,早期的网站一般都是由静态网页制作的。静态并非静止不动,它也包含一些动画效果,这一点不要误解。
我们知道,当网站信息量较大的时,网页的生成速度会降低,由于静态网页的内容相对固定,且不需要连接后台数据库,因此响应速度非常快。但静态网页更新比较麻烦,每次更新都需要重新加载整个网页。
静态网页的数据全部包含在 HTML 中,因此爬虫程序可以直接在 HTML 中提取数据。通过分析静态网页的 URL,并找到 URL 查询参数的变化规律,就可以实现页面抓取。与动态网页相比,并且静态网页对搜索引擎更加友好,有利于搜索引擎收录。
动态网页
动态网页指的是采用了动态网页技术的页面,比如 AJAX(是指一种创建交互式、快速动态网页应用的网页开发技术)、ASP(是一种创建动态交互式网页并建立强大的 web 应用程序)、JSP(是 Java 语言创建动态网页的技术标准) 等技术,它不需要重新加载整个页面内容,就可以实现网页的局部更新。
动态页面使用“动态页面技术”与服务器进行少量的数据交换,从而实现了网页的异步加载。下面看一个具体的实例:打开百度图片(https://image.baidu.com/)并搜索 Python,当滚动鼠标滑轮时,网页会从服务器数据库自动加载数据并渲染页面,这是动态网页和静态网页最基本的区别。
如何审查网页元素
检查百度首页
下面以检查百度首页为例:首先使用 Chrome 浏览器打开百度,然后在百度首页的空白处点击鼠标右键(或者按快捷键:F12),在出现的会话框中点击“检查”,并进行如图所示操作:
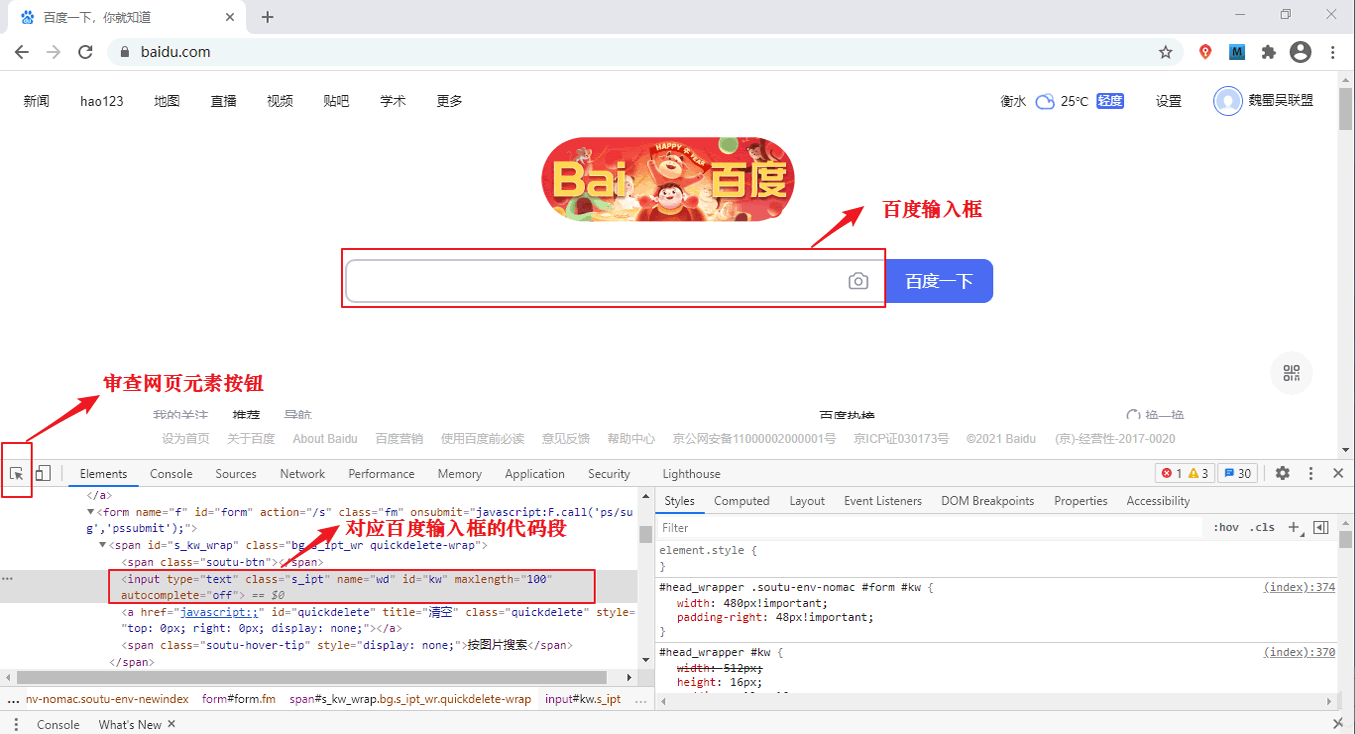
点击审查元素按钮,然后将鼠标移动至您想检查的位置,比如百度的输入框,然后单击,此时就会将该位置的代码段显示出来(如图 1 所示)。最后在该代码段处点击右键,在出现的会话框中选择 Copy 选项卡,并在二级会话框内选择“Copy element”,如下所示:
百度输入框的代码如下所示:
- <input type="text" class="s_ipt" name="wd" id="kw" maxlength="100" autocomplete="off">
依照上述方法,您可以检查页面内的所有元素。
第一个Python爬虫程序
获取网页html信息
1) 获取响应对象
向百度(http://www.baidu.com/)发起请求,获取百度首页的 HTML 信息,代码如下:
- #导包,发起请求使用urllib库的request请求模块
- import urllib.request
- # urlopen()向URL发请求,返回响应对象,注意url必须完整
- response=urllib.request.urlopen('http://www.baidu.com/')
- print(response)
上述代码会返回百度首页的响应对象, 其中 urlopen() 表示打开一个网页地址。注意:请求的 url 必须带有 http 或者 https 传输协议。
输出结果,如下所示:
<http.client.HTTPResponse object at 0x032F0F90>
上述代码也有另外一种导包方式,也就是使用 from,代码如下所示:
- #发起请求使用urllib库的request请求模块
- from urllib import request
- response=request.urlopen('http://www.baidu.com/')
- print(response)
2) 输出HTML信息
在上述代码的基础上继续编写如下代码:
- #提取响应内容
- html = response.read().decode('utf-8')
- #打印响应内容
- print(html)
输出结果如下,由于篇幅过长,此处只做了简单显示:
- <!DOCTYPE html><!--STATUS OK--> <html><head><meta http-equiv="Content-Type" content="text/html;charset=utf-8"><meta http-equiv="X-UA-Compatible" content="IE=edge,chrome=1"><meta content="always" name="referrer"><meta name="theme-color" content="#2932e1"><meta name="description" content="全球最大的中文搜索引擎、致力于让网民更便捷地获取信息,找到...">...</html>
通过调用 response 响应对象的 read() 方法提取 HTML 信息,该方法返回的结果是字节串类型(bytes),因此需要使用 decode() 转换为字符串。程序完整的代码程序如下:
- import urllib.request
- # urlopen()向URL发请求,返回响应对象
- response=urllib.request.urlopen('http://www.baidu.com/')
- # 提取响应内容
- html = response.read().decode('utf-8')
- # 打印响应内容
- print(html)
通过上述代码获取了百度首页的 html 信息,这是最简单、最初级的爬虫程序。后续我们还学习如何分析网页结构、解析网页数据,以及存储数据等。
常用方法
在本节您认识了第一个爬虫库 urllib,下面关于 urllib 做简单总结。
1) urlopen()
表示向网站发起请求并获取响应对象,如下所示:
urllib.request.urlopen(url,timeout)
urlopen() 有两个参数,说明如下:
- url:表示要爬取数据的 url 地址。
- timeout:设置等待超时时间,指定时间内未得到响应则抛出超时异常。
2) Request()
该方法用于创建请求对象、包装请求头,比如重构 User-Agent(即用户代理,指用户使用的浏览器)使程序更像人类的请求,而非机器。重构 User-Agent 是爬虫和反爬虫斗争的第一步。在下一节会做详细介绍。
urllib.request.Request(url,headers)
参数说明如下:
- url:请求的URL地址。
- headers:重构请求头。
3) html响应对象方法
- bytes = response.read() # read()返回结果为 bytes 数据类型
- string = response.read().decode() # decode()将字节串转换为 string 类型
- url = response.geturl() # 返回响应对象的URL地址
- code = response.getcode() # 返回请求时的HTTP响应码
4) 编码解码操作
#字符串转换为字节码
string.encode("utf-8")
#字节码转换为字符串
bytes.decode("utf-8")
User-Agent(用户代理)是什么
User-Agent 即用户代理,简称“UA”,它是一个特殊字符串头。网站服务器通过识别 “UA”来确定用户所使用的操作系统版本、CPU 类型、浏览器版本等信息。而网站服务器则通过判断 UA 来给客户端发送不同的页面。
我们知道,网络爬虫使用程序代码来访问网站,而非人类亲自点击访问,因此爬虫程序也被称为“网络机器人”。绝大多数网站都具备一定的反爬能力,禁止网爬虫大量地访问网站,以免给网站服务器带来压力。本节即将要讲解的 User-Agent 就是反爬策略的第一步。
网站通过识别请求头中 User-Agent 信息来判断是否是爬虫访问网站。如果是,网站首先对该 IP 进行预警,对其进行重点监控,当发现该 IP 超过规定时间内的访问次数, 将在一段时间内禁止其再次访问网站。
常见的 User-Agent 请求头,如下所示:
| 系统 | 浏览器 | User-Agent字符串 |
|---|---|---|
| Mac | Chrome | Mozilla/5.0 (Macintosh; Intel Mac OS X 10_12_6) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/73.0.3683.75 Safari/537.36 |
| Mac | Firefox | Mozilla/5.0 (Macintosh; Intel Mac OS X 10.12; rv:65.0) Gecko/20100101 Firefox/65.0 |
| Mac | Safari | Mozilla/5.0 (Macintosh; Intel Mac OS X 10_12_6) AppleWebKit/605.1.15 (KHTML, like Gecko) Version/12.0.3 Safari/605.1.15 |
| Windows | Edge | Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/64.0.3282.140 Safari/537.36 Edge/18.17763 |
| Windows | IE | Mozilla/5.0 (Windows NT 10.0; WOW64; Trident/7.0; rv:11.0) like Gecko |
| Windows | Chrome | Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/72.0.3626.121 Safari/537.36 |
| iOS | Chrome | Mozilla/5.0 (iPhone; CPU iPhone OS 7_0_4 like Mac OS X) AppleWebKit/537.51.1 (KHTML, like Gecko) CriOS/31.0.1650.18 Mobile/11B554a Safari/8536.25 |
| iOS | Safari | Mozilla/5.0 (iPhone; CPU iPhone OS 8_3 like Mac OS X) AppleWebKit/600.1.4 (KHTML, like Gecko) Version/8.0 Mobile/12F70 Safari/600.1.4 |
| Android | Chrome | Mozilla/5.0 (Linux; Android 4.2.1; M040 Build/JOP40D) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/31.0.1650.59 Mobile Safari/537.36 |
| Android | Webkit | Mozilla/5.0 (Linux; U; Android 4.4.4; zh-cn; M351 Build/KTU84P) AppleWebKit/534.30 (KHTML, like Gecko) Version/4.0 Mobile Safari/534.30 |
使用上表中的浏览器 UA,我们可以很方便的构建出 User-Agent。通过在线识别工具,可以查看本机的浏览器版本以及 UA 信息,如下所示:
| 浏览器名称 | Chrome |
|---|---|
| 浏览器版本 | 88.0.4324.182 |
| 系统平台 | Windows |
| UA信息 | Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/88.0.4324.182 Safari/537.36 |
若想更多地了解浏览器 UA 信息(包含移动端、PC端)可参考《常用浏览器User-Agent》。
爬虫程序UA信息
下面,通过向 HTTP 测试网站(http://httpbin.org/)发送 GET 请求来查看请求头信息,从而获取爬虫程序的 UA。代码如下所示:
- #导入模块
- import urllib.request
- #向网站发送get请求
- response=urllib.request.urlopen('http://httpbin.org/get')
- html = response.read().decode()
- print(html)
程序运行后,输出的请求头信息如下所示:
{
"args": {},
#请求头信息
"headers": {
"Accept-Encoding": "identity",
"Host": "httpbin.org",
"User-Agent": "Python-urllib/3.7", #UserAgent信息包含在请求头中!
"X-Amzn-Trace-Id": "Root=1-6034954b-1cb061183308ae920668ec4c"
},
"origin": "121.17.25.194",
"url": "http://httpbin.org/get"
}
从输出结果可以看出,User-Agent 竟然是 Python-urllib/3.7,这显然是爬虫程序访问网站。因此就需要重构 User-Agent,将其伪装成“浏览器”访问网站。
注意:httpbin.org这个网站能测试 HTTP 请求和响应的各种信息,比如 cookie、IP、headers 和登录验证等,且支持 GET、POST 等多种方法,对 Web 开发和测试很有帮助。
重构爬虫UA信息
下面使用urllib.request.Request()方法重构 User-Agent 信息,代码如下所示:
- from urllib import request
- # 定义变量:URL 与 headers
- url = 'http://httpbin.org/get' #向测试网站发送请求
- #重构请求头,伪装成 Mac火狐浏览器访问,可以使用上表中任意浏览器的UA信息
- headers = {
- 'User-Agent':'Mozilla/5.0 (Macintosh; Intel Mac OS X 10.12; rv:65.0) Gecko/20100101 Firefox/65.0'}
- # 1、创建请求对象,包装ua信息
- req = request.Request(url=url,headers=headers)
- # 2、发送请求,获取响应对象
- res = request.urlopen(req)
- # 3、提取响应内容
- html = res.read().decode('utf-8')
- print(html)
构建User-Agnet代理池
自定义UA代理池
构建代理池的方法也非常简单,在您的 Pycharm 工作目录中定义一个 ua_info.py 文件,并将以下 UA 信息以列表的形式粘贴到该文件中,如下所示:
ua_list = [
'Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 5.1; Maxthon 2.0',
'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_7_0) AppleWebKit/535.11 (KHTML, like Gecko) Chrome/17.0.963.56 Safari/535.11',
'User-Agent:Opera/9.80 (Windows NT 6.1; U; en) Presto/2.8.131 Version/11.11',
'Mozilla/5.0 (Windows NT 6.1; rv:2.0.1) Gecko/20100101 Firefox/4.0.1',
'Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 6.0)',
'Mozilla/5.0 (Windows; U; Windows NT 6.1; en-us) AppleWebKit/534.50 (KHTML, like Gecko) Version/5.1 Safari/534.50',
'Mozilla/5.0 (compatible; MSIE 9.0; Windows NT 6.1; Trident/5.0',
' Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 5.1',
'Mozilla/4.0 (compatible; MSIE 6.0; Windows NT 5.1',
' Mozilla/5.0 (Macintosh; Intel Mac OS X 10.6; rv:2.0.1) Gecko/20100101 Firefox/4.0.1',
]
模块随机获取UA
您也可以使用专门第三方的模块来随机获取浏览器 UA 信息,不过该模块需要单独安装,安装方式如下:
pip install fake-useragent
下载安装成功后,演示如下代码:
- from fake_useragent import UserAgent
- #实例化一个对象
- ua=UserAgent()
- #随机获取一个ie浏览器ua
- print(ua.ie)
- print(ua.ie)
- #随机获取一个火狐浏览器ua
- print(ua.firefox)
- print(ua.firefox)
URL编码/解码详解
URL基本组成
URL 是由一些简单的组件构成,比如协议、域名、端口号、路径和查询字符串等,示例如下:
http://www.biancheng.net/index?param=10
路径和查询字符串之间使用问号?隔开。上述示例的域名为 www.biancheng.net,路径为 index,查询字符串为 param=1。
URL 中规定了一些具有特殊意义的字符,常被用来分隔两个不同的 URL 组件,这些字符被称为保留字符。例如:
- 冒号:用于分隔协议和主机组件,斜杠用于分隔主机和路径
?:用于分隔路径和查询参数等。=用于表示查询参数中的键值对。&符号用于分隔查询多个键值对。
其余常用的保留字符有:/ . ... # @ $ + ; %
哪些字符需要编码
URL 之所以需要编码,是因为 URL 中的某些字符会引起歧义,比如 URL 查询参数中包含了”&”或者”%”就会造成服务器解析错误;再比如,URL 的编码格式采用的是 ASCII 码而非 Unicode 格式,这表明 URL 中不允许包含任何非 ASCII 字符(比如中文),否则就会造成 URL 解析错误。
URL 编码协议规定(RFC3986 协议):URL 中只允许使用 ASCII 字符集可以显示的字符,比如英文字母、数字、和- _ . ~ ! *这 6 个特殊字符。当在 URL 中使用不属于 ASCII 字符集的字符时,就要使用特殊的符号对该字符进行编码,比如空格需要用%20来表示。
除了无法显示的字符需要编码外,还需要对 URL 中的部分保留字符和不安全字符进行编码。下面列举了部分不安全字符:
[ ] < > " " { } | \ ^ * · ‘ ’ 等
下面示例,查询字符串中包含一些特殊字符,这些特殊字符不需要编码:
http://www.biancheng.net/index?param=10!*¶m1=20!-~_
下表对 URL 中部分保留字符和不安全字符进行了说明:
| 字符 | 含义 | 十六进制值编码 |
|---|---|---|
| + | URL 中 + 号表示空格 | %2B |
| 空格 | URL中的空格可以编码为 + 号或者 %20 | %20 |
| / | 分隔目录和子目录 | %2F |
| ? | 分隔实际的 URL 和参数 | %3F |
| % | 指定特殊字符 | %25 |
| # | 表示书签 | %23 |
| & | URL 中指定的参数间的分隔符 | %26 |
| = | URL 中指定参数的值 | %3D |
下面简单总结一下,哪些字符需要编码,分为以下三种情况:
- ASCII 表中没有对应的可显示字符,例如,汉字。
- 不安全字符,包括:# ”% <> [] {} | \ ^ ` 。
- 部分保留字符,即 & / : ; = ? @ 。
Python实现编码与解码
Python 的标准库urllib.parse模块中提供了用来编码和解码的方法,分别是 urlencode() 与 unquote() 方法。
| 方法 | 说明 |
|---|---|
| urlencode() | 该方法实现了对 url 地址的编码操作 |
| unquote() | 该方法将编码后的 url 地址进行还原,被称为解码 |
1) 编码urlencode()
下面以百度搜索为例进行讲解。首先打开百度首页,在搜索框中输入“爬虫”,然后点击“百度一下”。当搜索结果显示后,此时地址栏的 URL 信息,如下所示:
https://www.baidu.com/s?wd=爬虫&rsv_spt=1&rsv_iqid=0xa3ca348c0001a2ab&issp=1&f=8&rsv_bp=1&rsv_idx=2&ie=utf-8&tn=baiduhome_pg&rsv_enter=1&rsv_dl=ib&rsv_sug3=8&rsv_sug1=7&rsv_sug7=101
可以看出 URL 中有很多的查询字符串,而第一个查询字符串就是“wd=爬虫”,其中 wd 表示查询字符串的键,而“爬虫”则代表您输入的值。
在网页地址栏中删除多余的查询字符串,最后显示的 URL 如下所示:
https://www.baidu.com/s?wd=爬虫
使用搜索修改后的 URL 进行搜索,依然会得到相同页面。因此可知“wd”参数是百度搜索的关键查询参数。下面编写爬虫程序对 “wd=爬虫”进行编码,如下所示:
- #导入parse模块
- from urllib import parse
- #构建查询字符串字典
- query_string = {
- 'wd' : '爬虫'
- }
- #调用parse模块的urlencode()进行编码
- result = parse.urlencode(query_string)
- #使用format函数格式化字符串,拼接url地址
- url = 'http://www.baidu.com/s?{}'.format(result)
- print(url)
输出结果,如下所示:
wd=%E7%88%AC%E8%99%AB
http://www.baidu.com/s?wd=%E7%88%AC%E8%99%AB
编码后的 URL 地址依然可以通过地网页址栏实现搜索功能。
除了使用 urlencode() 方法之外,也可以使用 quote(string) 方法实现编码,代码如下:
- from urllib import parse
- #注意url的书写格式,和 urlencode存在不同
- url = 'http://www.baidu.com/s?wd={}'
- word = input('请输入要搜索的内容:')
- #quote()只能对字符串进行编码
- query_string = parse.quote(word)
- print(url.format(query_string))
输出结果如下:
输入:请输入要搜索的内容:编程帮www.biancheng.net
输出:http://www.baidu.com/s?wd=%E7%BC%96%E7%A8%8B%E5%B8%AEwww.biancheng.net
注意:quote() 只能对字符串编码,而 urlencode() 可以直接对查询字符串字典进行编码。因此在定义 URL 时,需要注意两者之间的差异。方法如下:
- # urllib.parse
- urllib.parse.urlencode({'key':'value'}) #字典
- urllib.parse.quote(string) #字符串
2) 解码unquote(string)
解码是对编码后的 URL 进行还原的一种操作,示例代码如下:
- from urllib import parse
- string = '%E7%88%AC%E8%99%AB'
- result = parse.unquote(string)
- print(result)
输出结果:
爬虫
3) URL地址拼接方式
最后,给大家介绍三种拼接 URL 地址的方法。除了使用 format() 函数外,还可以使用字符串相加,以及字符串占位符,总结如下:
Python爬虫抓取网页
首先我们对要编写的爬虫程序进行简单地分析,该程序可分为以下三个部分:
- 拼接 url 地址
- 发送请求
- 将照片保存至本地
明确逻辑后,我们就可以正式编写爬虫程序了。
导入所需模块
本节内容使用 urllib 库来编写爬虫,下面导入程序所用模块:
from urllib import request
from urllib import parse
拼接URL地址
定义 URL 变量,拼接 url 地址。代码如下所示:
- url = 'http://www.baidu.com/s?wd={}'
- #想要搜索的内容
- word = input('请输入搜索内容:')
- params = parse.quote(word)
- full_url = url.format(params)
向URL发送请求
发送请求主要分为以下几个步骤:
- 创建请求对象-Request
- 获取响应对象-urlopen
- 获取响应内容-read
代码如下所示:
保存为本地文件
把爬取的照片保存至本地,此处需要使用 Python 编程的文件 IO 操作,代码如下:
- filename = word + '.html'
- with open(filename,'w', encoding='utf-8') as f:
- f.write(html)
Python爬虫抓取百度贴吧数据
判断页面类型
通过简单的分析可以得知,待抓取的百度贴吧页面属于静态网页,分析方法非常简单:打开百度贴吧,搜索“Python爬虫”,在出现的页面中复制任意一段信息,比如“爬虫需要 http 代理的原因”,然后点击右键选择查看源码,并使用 Ctrl+F 快捷键在源码页面搜索刚刚复制的数据,如下所示:
由上图可知,页面内的所有信息都包含在源码页中,数据并不需要从数据库另行加载,因此该页面属于静态页面。
寻找URL变化规律
接下来寻找要爬取页面的 URL 规律,搜索“Python爬虫”后,此时贴吧第一页的的 url 如下所示:
https://tieba.baidu.com/f?ie=utf-8&kw=python爬虫&fr=search
点击第二页,其 url 信息如下:
https://tieba.baidu.com/f?kw=python爬虫&ie=utf-8&pn=50
点击第三页,url 信息如下:
https://tieba.baidu.com/f?kw=python爬虫&ie=utf-8&pn=100
重新点击第一页,url 信息如下:
https://tieba.baidu.com/f?kw=python爬虫&ie=utf-8&pn=0
如果还不确定,您可以继续多浏览几页。最后您发现 url 具有两个查询参数,分别是 kw 和 pn,并且 pn 参数具有规律性,如下所示:
第n页:pn=(n-1)*50 #参数params
pn=(page-1)*50
params={
'kw':name,
'pn':str(pn)
}
url 地址可以简写为:
https://tieba.baidu.com/f?kw=python爬虫&pn=450
以面向对象方法编写爬虫程序时,思路简单、逻辑清楚,非常容易理解,上述代码主要包含了四个功能函数,它们分别负责了不同的功能,总结如下:
1) 请求函数
请求函数最终的结果是返回一个 HTML 对象,以方便后续的函数调用它。
2) 解析函数
解析函数用来解析 HTML 页面,常用的解析模块有正则解析模块、bs4 解析模块。通过分析页面,提取出所需的数据,在后续内容会做详细介绍。
3) 保存数据函数
该函数负责将抓取下来的数据保至数据库中,比如 MySQL、MongoDB 等,或者将其保存为文件格式,比如 csv、txt、excel 等。
4) 入口函数
入口函数充当整个爬虫程序的桥梁,通过调用不同的功能函数,实现数据的最终抓取。入口函数的主要任务是组织数据,比如要搜索的贴吧名、编码 url 参数、拼接 url 地址、定义文件保存路径。
爬虫程序结构
用面向对象的方法编写爬虫程序时,逻辑结构较为固定,总结如下:
- # 程序结构
- class xxxSpider(object):
- def __init__(self):
- # 定义常用变量,比如url或计数变量等
- def get_html(self):
- # 获取响应内容函数,使用随机User-Agent
- def parse_html(self):
- # 使用正则表达式来解析页面,提取数据
- def write_html(self):
- # 将提取的数据按要求保存,csv、MySQL数据库等
- def run(self):
- # 主函数,用来控制整体逻辑
- if __name__ == '__main__':
- # 程序开始运行时间
- spider = xxxSpider()
- spider.run()
正则表达式基本语法
正则表达式元字符
下表列出了常用的正则表达式元字符:
1) 元字符
| 元字符 | 匹配内容 |
|---|---|
| . | 匹配除换行符以外的任意字符 |
| \w | 匹配所有普通字符(数字、字母或下划线) |
| \s | 匹配任意的空白符 |
| \d | 匹配数字 |
| \n | 匹配一个换行符 |
| \t | 匹配一个制表符 |
| \b | 匹配一个单词的结尾 |
| ^ | 匹配字符串的开始位置 |
| $ | 匹配字符串的结尾位置 |
| \W | 匹配非字母或数字或下划线 |
| \D | 匹配非数字 |
| \S | 匹配非空白符 |
| a|b | 匹配字符 a 或字符 b |
| () | 正则表达式分组所用符号,匹配括号内的表达式,表示一个组。 |
| [...] | 匹配字符组中的字符 |
| [^...] | 匹配除了字符组中字符的所有字符 |
2) 量词
| 量词 | 用法说明 |
|---|---|
| * | 重复零次或者更多次 |
| + | 重复一次或者更多次 |
| ? | 重复0次或者一次 |
| {n} | 重复n次 |
| {n,} | 重复n次或者更多次 |
| {n,m} | 重复n到m次 |
3) 字符组
有时也会出现各种字符组成的字符组,这在正则表达式中使用[]表示,如下所示:
| 正则 | 待匹配字符 | 匹配结果 | 说明 |
|---|---|---|---|
| [0123456789] | 8 | True | 在一个字符组里枚举所有字符,字符组里的任意一个字符 和"待匹配字符"相同都视为可以匹配。 |
| [0123456789] | a | False | 由于字符组中没有 "a" 字符,所以不能匹配。 |
| [0-9] | 7 | True | 也可以用-表示范围,[0-9] 就和 [0123456789] 是一个意思。 |
| [a-z] | s | True | 同样的如果要匹配所有的小写字母,直接用 [a-z] 就可以表示。 |
| [A-Z] | B | True | [A-Z] 就表示所有的大写字母。 |
| [0-9a-fA-F] | e | True | 可以匹配数字,大小写形式的 a~f,用来验证十六进制字符。 |
贪婪模式非贪婪模式
正则表达式默认为贪婪匹配,也就是尽可能多的向后匹配字符,比如 {n,m} 表示匹配前面的内容出现 n 到 m 次(n 小于 m),在贪婪模式下,首先以匹配 m 次为目标,而在非贪婪模式是尽可能少的向后匹配内容,也就是说匹配 n 次即可。
贪婪模式转换为非贪婪模式的方法很简单,在元字符后添加“?”即可实现,如下所示:
| 元字符(贪婪模式) | 非贪婪模式 |
|---|---|
| * | *? |
| + | +? |
| ? | ?? |
| {n,m} | {n,m}? |
正则表达式转义
如果使用正则表达式匹配特殊字符时,则需要在字符前加\表示转意。常见的特殊字符如下:
* + ? ^ $ [] () {} | \
Python re模块用法详解
re模块常用方法
1) re.compile()
该方法用来生成正则表达式对象,其语法格式如下:
regex=re.compile(pattern,flags=0)
参数说明:
- pattern:正则表达式对象。
- flags:代表功能标志位,扩展正则表达式的匹配。
2) re.findall()
根据正则表达式匹配目标字符串内容。
re.findall(pattern,string,flags=0)
该函数的返回值是匹配到的内容列表,如果正则表达式有子组,则只能获取到子组对应的内容。参数说明如下:
- pattern:正则表达式对象。
- string:目标字符串
- flags:代表功能标志位,扩展正则表达式的匹配。
3) regex.findall()
该函数根据正则表达式对象匹配目标字符串内容。其语法格式如下:
regex.findall(string,pos,endpos)
参数说明:
- string 目标字符串。
- pos 截取目标字符串的开始匹配位置。
- endpos 截取目标字符串的结束匹配位置。
4) re.split()
该函数使用正则表达式匹配内容,切割目标字符串。返回值是切割后的内容列表。参数说明:
re.split(pattern,string,flags = 0)
参数说明:
- pattern:正则表达式。
- string:目标字符串。
- flags:功能标志位,扩展正则表达式的匹配。
5) re.sub
该函数使用一个字符串替换正则表达式匹配到的内容。返回值是替换后的字符串。其语法格式如下:
re.sub(pattern,replace,string,max,flags = 0)
其参数说明:
- pattern:正则表达式。
- replace:替换的字符串。
- string:目标字符串。
- max:最多替换几处,默认替换全部,
- flags:功能标志位,扩展正则表达式的匹配。
5) re.search()
匹配目标字符串第一个符合的内容,返回值为匹配的对象。语法格式如下:
re.search(pattern,string,flags=0)
参数说明:
- pattern:正则表达式
- string:目标字符串
flags功能标志位
功能标志位的作用是扩展正则表达的匹配功能。常用的 flag 如下所示:
| 缩写元字符 | 说明 |
|---|---|
| A | 元字符只能匹配 ASCII码。 |
| I | 匹配忽略字母大小写。 |
| S | 使得.元字符可以匹配换行符。 |
| M | 使 ^ $ 可以匹配每一行的开头和结尾位置。 |
注意:可以同时使用福多个功能标志位,比如 flags=re.I|re.S。
Python csv模块(读写文件)
CSV文件写入
1) csv.writer()
csv 模块中的 writer 类可用于读写序列化的数据,其语法格式如下:
writer(csvfile, dialect='excel', **fmtparams)
参数说明:
- csvfile:必须是支持迭代(Iterator)的对象,可以是文件(file)对象或者列表(list)对象。
- dialect:编码风格,默认为 excel 的风格,也就是使用逗号
,分隔。 - fmtparam:格式化参数,用来覆盖之前 dialect 对象指定的编码风格。
示例如下:
- import csv
- # 操作文件对象时,需要添加newline参数逐行写入,否则会出现空行现象
- with open('eggs.csv', 'w', newline='') as csvfile:
- # delimiter 指定分隔符,默认为逗号,这里指定为空格
- # quotechar 表示引用符
- # writerow 单行写入,列表格式传入数据
- spamwriter = csv.writer(csvfile, delimiter=' ',quotechar='|')
- spamwriter.writerow(['www.biancheng.net'] * 5 + ['how are you'])
- spamwriter.writerow(['hello world', 'web site', 'www.biancheng.net'])
eggs.csv 文件内容如下:
www.biancheng.net www.biancheng.net www.biancheng.net www.biancheng.net www.biancheng.net |how are you|
|hello world| |web site| www.biancheng.net
其中,quotechar 是引用符,当一段话中出现分隔符的时候,用引用符将这句话括起来,以能排除歧义。
如果想同时写入多行数据,需要使用 writerrows() 方法,代码如下所示:
- import csv
- with open('aggs.csv', 'w', newline='') as f:
- writer = csv.writer(f)
- # 注意传入数据的格式为列表元组格式
- writer.writerows([('hello','world'), ('I','love','you')])
aggs.csv文件内容:
hello,world
I,love,you
2) csv.DictWriter()
当然也可使用 DictWriter 类以字典的形式读写数据,使用示例如下:
- import csv
- with open('names.csv', 'w', newline='') as csvfile:
- #构建字段名称,也就是key
- fieldnames = ['first_name', 'last_name']
- writer = csv.DictWriter(csvfile, fieldnames=fieldnames)
- # 写入字段名,当做表头
- writer.writeheader()
- # 多行写入
- writer.writerows([{'first_name': 'Baked', 'last_name': 'Beans'},{'first_name': 'Lovely', 'last_name': 'Spam'}])
- # 单行写入
- writer.writerow({'first_name': 'Wonderful', 'last_name': 'Spam'})
name.csv 文件内容,如下所示:
first_name,last_name
Baked,Beans
Lovely,Spam
Wonderful,Spam
CSV文件读取
1) csv,reader()
csv 模块中的 reader 类和 DictReader 类用于读取文件中的数据,其中 reader() 语法格式如下:
csv.reader(csvfile, dialect='excel', **fmtparams)
应用示例如下:
- import csv
- with open('eggs.csv', 'r', newline='') as csvfile:
- spamreader = csv.reader(csvfile, delimiter=' ', quotechar='|')
- for row in spamreader:
- print(', '.join(row))
输出结果:
www.biancheng.net, www.biancheng.net, www.biancheng.net, www.biancheng.net, www.biancheng.net, how are you
hello world, web site, www.biancheng.net
2) csv.DictReader()
应用示例如下:
- import csv
- with open('names.csv', newline='') as csvfile:
- reader = csv.DictReader(csvfile)
- for row in reader:
- print(row['first_name'], row['last_name'])
输出结果:
Baked Beans
Lovely Spam
Wonderful Spam
Python爬虫抓取猫眼电影排行榜
确定url规律
想要确定 url 规律,需要您多浏览几个页面,然后才可以总结出 url 规律,如下所示:
第一页:https://maoyan.com/board/4?offset=0
第二页:https://maoyan.com/board/4?offset=10
第三页:https://maoyan.com/board/4?offset=20
...
第n页:https://maoyan.com/board/4?offset=(n-1)*10
确定正则表达式
通过分析网页元素结构来确定正则表达式,如下所示:
使用 Chrome 开发者调试工具来精准定位要抓取信息的元素结构。之所以这样做,是因为这能避免正则表达式的冗余,提高编写正则表达式的速度。正则表达式如下所示:
<div class="movie-item-info">.*?title="(.*?)".*?class="star">(.*?)</p>.*?releasetime">(.*?)</p>
Python Pymysql实现数据存储
创建存储数据表
首先您应该确定您的计算机上已经安装了 MySQL 数据库,然后再进行如下操作:
# 1. 连接到mysql数据库
mysql -h127.0.0.1 -uroot -p123456
# 2. 建库
create database maoyandb charset utf8;
# 3. 切换数据库
use maoyandb;
# 4. 创建数据表
create table filmtab(
name varchar(100),
star varchar(400),
time varchar(30)
);
Pymysql基本使用
1) 连接数据库
- db = pymysql.connect('localhost','root','123456','maoyandb')
参数说明:
- localhost:本地 MySQL 服务端地址,也可以是远程数据库的 IP 地址。
- root:连接数据所使用的用户名。
- password:连接数据库使用的密码,本机 MySQL 服务端密码“123456”。
- db:连接的数据库名称。
2) 创建cursor对象
cursor = db.cursor()
3) 执行sql命令
execute() 方法用来执行 SQL 语句。如下所示:
- #第一种方法:编写sql语句,使用占位符传入相应数据
- sql = "insert into filmtab values('%s','%s','%s')" % ('刺杀,小说家','雷佳音','2021')
- cursor.excute(sql)
- 第二种方法:编写sql语句,使用列表传参方式
- sql = 'insert into filmtab values(%s,%s,%s)'
- cursor.execute(sql,['刺杀,小说家','雷佳音','2021'])
4) 提交数据
db.commit()
5) 关闭数据库
cursor.close()
db.close()
完整的代码如下所示:
- # -*-coding:utf-8-*-
- import pymysql
- #创建对象
- db = pymysql.connect('localhost','root','123456','maoyandb')
- cursor = db.cursor()
- # sql语句执性,单行插入
- info_list = ['刺杀,小说家','雷佳音,杨幂','2021-2-12']
- sql = 'insert into movieinfo values(%s,%s,%s)'
- #列表传参
- cursor.execute(sql,info_list)
- db.commit()
- # 关闭
- cursor.close()
- db.close()
查询数据结果,如下所示:
mysql> select * from movieinfo;
+-------------+-------------------+-----------+
| name | star | time |
+-------------+-------------------+-----------+
| 刺杀,小说家 | 雷佳音,杨幂 | 2021-2-12 |
+-------------+-------------------+-----------+
1 rows in set (0.01 sec)
还有一种效率较高的方法,使用 executemany() 可以同时插入多条数据。示例如下:
- db = pymysql.connect('localhost','root','123456','maoyandb',charset='utf8')
- cursor = db.cursor()
- # sql语句执性,列表元组
- info_list = [('我不是药神','徐峥','2018-07-05'),('你好,李焕英','贾玲','2021-02-12')]
- sql = 'insert into movieinfo values(%s,%s,%s)'
- cursor.executemany(sql,info_list)
- db.commit()
- # 关闭
- cursor.close()
- db.close()
查询插入结果,如下所示:
mysql> select * from movieinfo;
+-------------+-------------------+------------+
| name | star | time |
+-------------+-------------------+------------+
| 我不是药神 | 徐峥 | 2018-07-05 |
| 你好,李焕英 | 贾玲 | 2021-02-12 |
+-------------+-------------------+------------+
2 rows in set (0.01 sec)
Python爬虫:抓取多级页面数据
在爬虫的过程中,多级页面抓取是经常遇见的。下面以抓取二级页面为例,对每级页面的作用进行说明:
- 一级页面提供了获取二级页面的访问链接。
- 二级页面作为详情页用来提取所需数据。
一级页面以<a>标签的形式链接到二级页面,只有在二级页面才可以提取到所需数据。
1) 寻找url规律
通过简单分析可以得知一级与二级页面均为静态页面,接下来分析 url 规律,通过点击第 1 页,第 2 页 ...,其规律如下:
第1页 :https://www.dytt8.net/html/gndy/dyzz/list_23_1.html
第2页 :https://www.dytt8.net/html/gndy/dyzz/list_23_2.html
第n页 :https://www.dytt8.net/html/gndy/dyzz/list_23_n.html
2) 确定正则表达式
通过元素审查可知一级页面的元素结构如下:
其正则表达式如下:
<table width="100%".*?<td width="5%".*?<a href="(.*?)".*?ulink">.*?</table>
点击二级页面进入详情页,通过开发者工具分析想要数据的网页元素,即电影名称,和下载链接,其正则表达式如下:
<div class="title_all"><h1><font color=#07519a>(.*?)</font></h1></div>.*?<div><a href="(.*?)">.*?</a>
爬虫增量抓取
爬虫是一种效率很低的程序,非常消耗计算机资源。对于聚焦爬虫程序而言,需要每天对特定的网站进行数据抓取,如果每次都去抓取之前已经抓取过的数据,就会白白消耗了时间和资源。而增量爬虫是指通过监测网站更新的情况,只抓取最新数据的一种方式,这样就大大降低了资源的消耗。
对于本节案例来说,电影天堂网站每天都会更新内容,因此编写一个增量抓取的爬虫程序是非常合适的。
那么要如何判断爬虫程序是否已抓取过二级页面的 url 呢?其实,当您第一次运行爬虫程序时,爬虫会将所有的 url 抓取下来,然后将这些 url 放入数据库中。为了提高数据库的查询效率,您可以为每一个 url 生成专属的“指纹”。当网站更新后,第二次运行爬虫程序时,程序只会对数据库中不存在的指纹进行抓取。
Python Requests库安装和使用
常用请求方法
1) requests.get()
该方法用于 GET 请求,表示向网站发起请求,获取页面响应对象。语法如下:
res = requests.get(url,headers=headers,params,timeout)
参数说明如下:
- url:要抓取的 url 地址。
- headers:用于包装请求头信息。
- params:请求时携带的查询字符串参数。
- timeout:超时时间,超过时间会抛出异常。
具体使用示例如下:
- import requests
- url = 'http://baidu.com'
- response = requests.get(url)
- print(response)
2) requests.post()
该方法用于 POST 请求,先由用户向目标 url 提交数据,然后服务器返回一个 HttpResponse 响应对象,语法如下:
response=requests.post(url,data={请求体的字典})
示例如下所示:
- import requests
- #百度翻译
- url = 'https://fanyi.baidu.com'
- #post请求体携带的参数,可通过开发者调试工具查看
- #查看步骤:NetWork选项->Headers选项->Form Data
- data = {'from': 'zh',
- 'to': 'en',
- 'query': '编程帮www.biancheng.net你好'
- }
- response = requests.post(url, data=data)
- print(response)
对象属性
当我们使用 Requests 模块向一个 URL 发起请求后会返回一个 HttpResponse 响应对象,该对象具有以下常用属性:
| 常用属性 | 说明 |
|---|---|
| encoding | 查看或者指定响应字符编码 |
| status_code | 返回HTTP响应码 |
| url | 查看请求的 url 地址 |
| headers | 查看请求头信息 |
| cookies | 查看cookies 信息 |
| text | 以字符串形式输出 |
| content | 以字节流形式输出,若要保存下载图片需使用该属性。 |
Python爬虫抓取网络照片
分析url规律
打开百度图片翻页版(点击访问),该翻页版网址要妥善保留。其 url 规律如下:
第一页:https://image.baidu.com/search/flip?tn=baiduimage&word=python&pn=0
第二页:https://image.baidu.com/search/flip?tn=baiduimage&word=python&pn=20
第三页:https://image.baidu.com/search/flip?tn=baiduimage&word=python&pn=40
第n页:https://image.baidu.com/search/flip?tn=baiduimage&word=python&pn=20*(n-1)
百度为了限制爬虫,将原来的翻页版变为了“瀑布流”浏览形式,也就是通过滚动滑轮自动加载图片,此种方式在一定程度上限制了爬虫程序。
写正则表达式
通过上一节可以得知每一张图片有一个源地址如下所示:
data-imgurl="图片源地址"
Requests库常用方法及参数介绍
Requests 库中定义了七个常用的请求方法,这些方法各自有着不同的作用,在这些请求方法中 requests.get() 与 requests.post() 方法最为常用。请求方法如下所示:
| 方法 | 说明 |
|---|---|
| requests.request() | 构造一个请求对象,该方法是实现以下各个方法的基础。 |
| requests.get() | 获取HTML网页的主要方法,对应于 HTTP 的 GET 方法。 |
| requests.head() | 获取HTML网页头信息的方法,对应于 HTTP 的 HEAD 方法。 |
| requests.post() | 获取 HTML 网页提交 POST请求方法,对应于 HTTP 的 POST。 |
| requests.put() | 获取HTML网页提交PUT请求方法,对应于 HTTP 的 PUT。 |
| requests.patch() | 获取HTML网页提交局部修改请求,对应于 HTTP 的 PATCH。 |
| requests.delete() | 获取HTML页面提交删除请求,对应于 HTTP 的 DELETE。 |
上述方法都提供了相同的参数,其中某些参数已经使用过,比如headers和params,前者用来构造请求头,后者用来构建查询字符串。这些参数对于编写爬虫程序有着至关重要的作用。本节对其他常用参数做重点介绍。
代理IP-proxies参数
一些网站为了限制爬虫从而设置了很多反爬策略,其中一项就是针对 IP 地址设置的。比如,访问网站超过规定次数导致流量异常,或者某个时间段内频繁地更换浏览器访问,存在上述行为的 IP 极有可能被网站封杀掉。
代理 IP 就是解决上述问题的,它突破了 IP 地址的访问限制,隐藏了本地网络的真实 IP,而使用第三方 IP 代替自己去访问网站。
1) 代理IP池
通过构建代理 IP 池可以让你编写的爬虫程序更加稳定,从 IP 池中随机选择一个 IP 去访问网站,而不使用固定的真实 IP。总之将爬虫程序伪装的越像人,它就越不容易被网站封杀。当然代理 IP 也不是完全不能被察觉,通过端口探测技等术识仍然可以辨别。其实爬虫与反爬虫永远相互斗争的,就看谁的技术更加厉害。
2) proxies参数
Requests 提供了一个代理 IP 参数proxies,该参数的语法结构如下:
proxies = {
'协议类型(http/https)':'协议类型://IP地址:端口号'
}
下面构建了两个协议版本的代理 IP,示例如下:
proxies = {
'http':'http://IP:端口号',
'https':'https://IP:端口号'
}
3) 代理IP使用
下面通过简单演示如何使用proxies参数,示例如下:
- import requests
-
- url = 'http://httpbin.org/get'
- headers = {
- 'User-Agent':'Mozilla/5.0'
- }
- # 网上找的免费代理ip
- proxies = {
- 'http':'http://191.231.62.142:8000',
- 'https':'https://191.231.62.142:8000'
- }
- html = requests.get(url,proxies=proxies,headers=headers,timeout=5).text
- print(html)
Proxy SwitchyOmega安装和使用
Proxy SwitchyOmega 是一款非常优秀的浏览器插件,适用于 Chrome 和 Firefox,它可以轻松快捷地管理和切换 IP 代理。
Xpath简明教程(十分钟入门)
Xpath表达式
XPath(全称:XML Path Language)即 XML 路径语言,它是一门在 XML 文档中查找信息的语言,最初被用来搜寻 XML 文档,同时它也适用于搜索 HTML 文档。因此,在爬虫过程中可以使用 XPath 来提取相应的数据。
提示:XML 是一种遵守 W3C 标椎的标记语言,类似于 HTML,但两者的设计目的是不同,XML 通常被用来传输和存储数据,而 HTML 常用来显示数据。
您可以将 Xpath 理解为在XML/HTML文档中检索、匹配元素节点的工具。
Xpath 使用路径表达式来选取XML/HTML文档中的节点或者节点集。Xpath 的功能十分强大,它除了提供了简洁的路径表达式外,还提供了100 多个内建函数,包括了处理字符串、数值、日期以及时间的函数。因此 Xpath 路径表达式几乎可以匹配所有的元素节点。
Python 第三方解析库 lxml 对 Xpath 路径表达式提供了良好的支持,能够解析 XML 与 HTML 文档。
Xpath节点
XPath 提供了多种类型的节点,常用的节点有:元素、属性、文本、注释以及文档节点。如下所示:
- <?xml version="1.0" encoding="utf-8"?>
- <website>
- <site>
- <title lang="zh-CN">website name</title>
- <name>编程帮</name>
- <year>2010</year>
- <address>www.biancheng.net</address>
- </site>
- </website>
上面的 XML 文档中的节点例子:
<website></website> (文档节点)
<name></name> (元素节点)
lang="zh-CN" (属性节点)
节点关系
XML 文档的节点关系和 HTML 文档相似,同样有父、子、同代、先辈、后代节点。如下所示:
- <?xml version="1.0" encoding="utf-8"?>
- <website>
- <site>
- <title lang="zh-CN">website name</title>
- <name>编程帮</name>
- <year>2010</year>
- <address>www.biancheng.net</address>
- </site>
- </website>
上述示例分析后,会得到如下结果:
title name year address 都是 site 的子节点
site 是 title name year address 父节点
title name year address 属于同代节点
title 元素的先辈节点是 site website
website 的后代节点是 site title name year address
Xpath基本语法
1) 基本语法使用
Xpath 使用路径表达式在文档中选取节点,下表列出了常用的表达式规则:
| 表达式 | 描述 |
|---|---|
| node_name | 选取此节点的所有子节点。 |
| / | 绝对路径匹配,从根节点选取。 |
| // | 相对路径匹配,从所有节点中查找当前选择的节点,包括子节点和后代节点,其第一个 / 表示根节点。 |
| . | 选取当前节点。 |
| .. | 选取当前节点的父节点。 |
| @ | 选取属性值,通过属性值选取数据。常用元素属性有 @id 、@name、@type、@class、@tittle、@href。 |
下面以下述代码为例讲解 Xpath 表达式的基本应用,代码如下所示:
- <ul class="BookList">
- <li class="book1" id="book_01" href="http://www.biancheng.net/">
- <p class="name">c语言小白变怪兽</p>
- <p class="model">纸质书</p>
- <p class="price">80元</p>
- <p class="color">红蓝色封装</p>
- </li>
- <li class="book2" id="book_02" href="http://www.biancheng.net/">
- <p class="name">Python入门到精通</p>
- <p class="model">电子书</p>
- <p class="price">45元</p>
- <p class="color">蓝绿色封装</p>
- </li>
- </ul>
2) xpath通配符
Xpath 表达式的通配符可以用来选取未知的节点元素,基本语法如下:
| 通配符 | 描述说明 |
|---|---|
| * | 匹配任意元素节点 |
| @* | 匹配任意属性节点 |
| node() | 匹配任意类型的节点 |
示例如下:
Xpath内建函数
Xpath 提供 100 多个内建函数,这些函数给我们提供了很多便利,比如实现文本匹配、模糊匹配、以及位置匹配等,下面介绍几个常用的内建函数。
| 函数名称 | xpath表达式示例 | 示例说明 |
|---|---|---|
| text() | ./text() | 文本匹配,表示值取当前节点中的文本内容。 |
| contains() | //div[contains(@id,'stu')] | 模糊匹配,表示选择 id 中包含“stu”的所有 div 节点。 |
| last() | //*[@class='web'][last()] | 位置匹配,表示选择@class='web'的最后一个节点。 |
| position() | //*[@class='site'][position()<=2] | 位置匹配,表示选择@class='site'的前两个节点。 |
| start-with() | "//input[start-with(@id,'st')]" | 匹配 id 以 st 开头的元素。 |
| ends-with() | "//input[ends-with(@id,'st')]" | 匹配 id 以 st 结尾的元素。 |
| concat(string1,string2) | concat('C语言中文网',.//*[@class='stie']/@href) | C语言中文与标签类别属性为"stie"的 href 地址做拼接。 |
想要了解更多关于 Xpath 的知识可访问官方网站:https://www.w3.org/TR/xpath/
Python lxml库的安装和使用
安装lxml库
lxml 属于 Python 第三方库,因此需要使用如下方法安装:
pip3 install lxml
在 CMD 命令行验证是否安装成功。若引入模块,不返回错误则说明安装成功。
>>> import lxml
>>>
lxml使用流程
lxml 库提供了一个 etree 模块,该模块专门用来解析 HTML/XML 文档,下面我们简单介绍一下 lxml 库的使用流程,如下所示:
1) 导入模块
from lxml import etree
2) 创建解析对象
调用 etree 模块的 HTML() 方法来创建 HTML 解析对象。如下所示:
parse_html = etree.HTML(html)
上述 HTML 字符串存在缺少标签的情况,比如“C语言中文网”缺少一个 </li> 闭合标签,当使用了 HTML() 方法后,会将其自动转换为符合规范的 HTML 文档格式。
3) 调用xpath表达式
最后使用第二步创建的解析对象调用 xpath() 方法,完成数据的提取,如下所示:
r_list = parse_html.xpath('xpath表达式')
Python lxml解析库实战应用
基准表达式
因为每一个节点对象都使用相同 Xpath 表达式去匹配信息,所以很容易想到 for 循环。我们将 10 个<dd>节点放入一个列表中,然后使用 for 循环的方式去遍历每一个节点对象,这样就大大提高了编码的效率。
通过<dd>节点的父节点<dl>可以同时匹配 10 个<dd>节点,并将这些节点对象放入列表中。我们把匹配 10个<dd>节点的 Xpath 表达式称为“基准表达式”。如下所示:
xpath_bds='//dl[@class="board-wrapper"]/dd'
分析上述代码段,写出待抓取信息的 Xpath 表达式,如下所示:
提取电影名信息:xpath('.//p[@class="name"]/a/text()')
提取主演信息:xpath('.//p[@class="star"]/text()')
提取上映时间信息:xpath('.//p[@class="releasetime"]/text()')
- # 匹配10个dd节点对象
- xpath_bds='//dl[@class="board-wrapper"]/dd'
- dd_list=parse_html.xpath(xpath_bds)
Python爬虫抓取链家二手房数据
编写程序流程分析
打开链家网站后,第一步,确定网站是否为静态网站,通过在网页源码内搜索关键字的方法,可以确定其为静态网站;第二步,确定要抓取页面的 URL 规律,第三步,根据要抓取的数据确定 Xpath 表达式;最后一步,编写 Python 爬虫程序。
通过简单的分析可知 URL 具有以下规律:
第一页:https://bj.lianjia.com/ershoufang/pg1/
第二页:https://bj.lianjia.com/ershoufang/pg2/
第三页:https://bj.lianjia.com/ershoufang/pg3/
第n页:https://bj.lianjia.com/ershoufang/pgn/
浏览器实现抓包过程详解
首先访问有道翻译网站,然后使用快捷键 F12 打开控制台,并找到Network选项卡,最后在有道翻译的输入框内输入“hello world”进行翻译,控制台主界面如下所示:
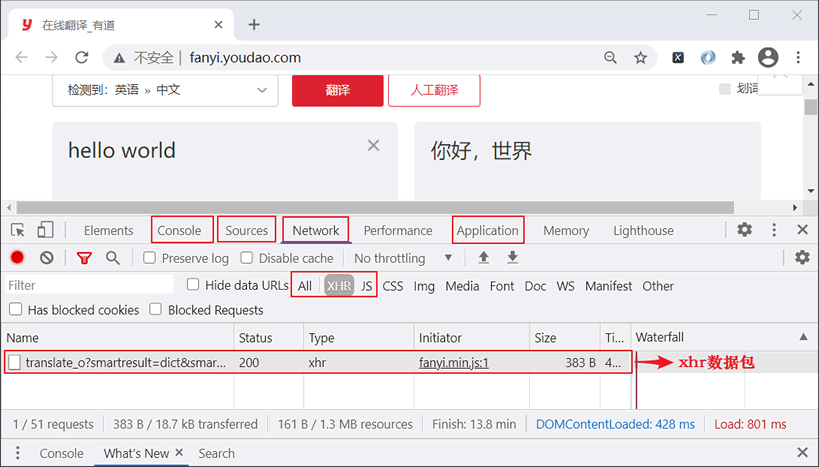
下面对上图 1 中控制台的常用选项做简单介绍:
1) NetWork
该选项主要用于抓取网络数据包,比如查看请求信息、响应信息等。它有三个常用选项卡,分别是 All、XHR、JS,其作用如下:
- All:抓取所有的网络数据包
- XHR:抓取所有异步加载的网络数据包
- JS:抓取所有的JS文件
2) Sources
该选项主要用于查看页面的 HTML 、JavaScript 、CSS 的源代码,除此之外,最重要的是它还可以调试 JS 源代码,可以给 JS 代码打断点调试,有助于分析爬虫程序中的一些参数。
3) Console
交互模式,能够执行 JavaScript 代码,一般用于对当前程序中 JS 代码进行测试,同时也可以查看 JavaScript 对象,或者调试日志、异常信息等。
4) Application
该选项用于查看、修改本地存储(Local Storage)以及会话存储(Session Stroage)等,同时它也可以用来查看 Cookie 信息。
Cookie 是网站服务器为了辨别用户身份,而储存在客户端浏览器上一段加密字符串。某些网站需要用户登录后才可以看到相应的数据。如果想要爬取此类网站的数据,就需要使用 Cookie 模拟用户登录。
Python爬虫实现Cookie模拟登录
在使用爬虫采集数据的规程中,我们会遇到许多不同类型的网站,比如一些网站需要用户登录后才允许查看相关内容,如果遇到这种类型的网站,又应该如何编写爬虫程序呢?Cookie 模拟登录技术成功地解决了此类问题。
Cookie 是一个记录了用户登录状态以及用户属性的加密字符串。当你第一次登陆网站时,服务端会在返回的 Response Headers 中添加 Cookie, 浏览器接收到响应信息后,会将 Cookie 保存至浏览器本地存储中,当你再次向该网站发送请求时,请求头中就会携带 Cookie,这样服务器通过读取 Cookie 就能识别登陆用户了。
提示:我们所熟知的“记住密码”功能,以及“老用户登陆”欢迎语,这些都是通过 Cookie 实现的。
下面介绍如何实现 Cookie 模拟登录,本节以模拟登录人人网(http://life.renren.com/)为例进行讲解。
Python多线程爬虫详解
多线程使用流程
Python 提供了两个支持多线程的模块,分别是 _thread 和 threading。其中 _thread 模块偏底层,它相比于 threading 模块功能有限,因此推荐大家使用 threading 模块。 threading 中不仅包含了 _thread 模块中的所有方法,还提供了一些其他方法,如下所示:
- threading.currentThread() 返回当前的线程变量。
- threading.enumerate() 返回一个所有正在运行的线程的列表。
- threading.activeCount() 返回正在运行的线程数量。
线程的具体使用方法如下所示:
- from threading import Thread
- #线程创建、启动、回收
- t = Thread(target=函数名) # 创建线程对象
- t.start() # 创建并启动线程
- t.join() # 阻塞等待回收线程
创建多线程的具体流程:
- t_list = []
- for i in range(5):
- t = Thread(target=函数名)
- t_list.append(t)
- t.start()
- for t in t_list:
- t.join()
除了使用该模块外,您也可以使用 Thread 线程类来创建多线程。
在处理线程的过程中要时刻注意线程的同步问题,即多个线程不能操作同一个数据,否则会造成数据的不确定性。通过 threading 模块的 Lock 对象能够保证数据的正确性。
比如,使用多线程将抓取数据写入磁盘文件,此时,就要对执行写入操作的线程加锁,这样才能够避免写入的数据被覆盖。当线程执行完写操作后会主动释放锁,继续让其他线程去获取锁,周而复始,直到所有写操作执行完毕。具体方法如下所示:
- from threading import Lock
- lock = Lock()
- # 获取锁
- lock.acquire()
- wirter.writerows("线程锁问题解决")
- # 释放锁
- lock.release()
Queue队列模型
对于 Python 多线程而言,由于 GIL 全局解释器锁的存在,同一时刻只允许一个线程占据解释器执行程序,当此线程遇到 IO 操作时就会主动让出解释器,让其他处于等待状态的线程去获取解释器来执行程序,而该线程则回到等待状态,这主要是通过线程的调度机制实现的。
由于上述原因,我们需要构建一个多线程共享数据的模型,让所有线程都到该模型中获取数据。queue(队列,先进先出) 模块提供了创建共享数据的队列模型。比如,把所有待爬取的 URL 地址放入队列中,每个线程都到这个队列中去提取 URL。queue 模块的具体使用方法如下:
Python Selenium的下载和安装
Selenium 是一个用于测试 Web 应用程序的自动化测试工具,它直接运行在浏览器中,实现了对浏览器的自动化操作,它支持所有主流的浏览器,包括 IE,Firefox,Safari,Chrome 等。
Selenium 支持所有主流平台(如,Windows、Linux、IOS、Android、Edge、Opera等),同时,它也实现了诸多自动化功能,比如软件自动化测试,检测软件与浏览器兼容性,自动录制、生成不同语言的测试脚本,以及自动化爬虫等。本节及后续两节主要围绕自动化爬虫展开讲解。

图1:Python Selenium
Selenium 提供了一个工具集,包括 Selenium WebDriver(浏览器驱动)、Selenium IDE(录制测试脚本)、Selenium Grid(执行测试脚本)。后面两个主要用于测试脚本的录制、执行,因此不做介绍。我们只对 Selenium WebDriver 做重点讲解。
关于 Selenium IDE/Grid 的相关知识可参考官网文档https://www.selenium.dev/。
Selenium下载安装
Selenium 安装非常简单,Linux、Mac 用户执行以下命令即可:
sudo pip install Selenium
Windows 用户执行以下命令即可实现安装:
python -m pip install selenium
除了使用上述命令安装外,您也可以通过官方网站下载 Selenium WebDriver 安装包,点击前往下载。
安装浏览器驱动
若想使 Selenium 能够调用浏览器,那么必须通过 webdriver 驱动来实现。不同的浏览器需要使用不同驱动程序,下面列出了不同浏览器驱动程序的下载地址:
- 谷歌浏览器 chromedrive:http://chromedriver.storage.googleapis.com/index.html
- 火狐浏览器 geckodriver:https://github.com/mozilla/geckodriver/releases
- IE 浏览器 IEDriver:http://selenium-release.storage.googleapis.com/index.html
定位节点
Selenium 提供了 8 种定位单个节点的方法,如下所示:
| 方法 | 说明 |
|---|---|
| find_element_by_id() | 通过 id 属性值定位 |
| find_element_by_name() | 通过 name 属性值定位 |
| find_element_by_class_name() | 通过 class 属性值定位 |
| find_element_by_tag_name() | 通过 tag 标签名定位 |
| find_element_by_link_text() | 通过<a>标签内文本定位,即精准定位。 |
| find_element_by_partial_link_text() | 通过<a>标签内部分文本定位,即模糊定位。 |
| find_element_by_xpath() | 通过 xpath 表达式定位 |
| find_element_by_css_selector() | 通过 css 选择器定位 |
假设下面代码某个页面的代码片段,如下所示:
- <html>
- <head>
- <body link="#cc0916">
- <a id="logo" href="http://c.biancheng.net" onclick="">
- <form id="form" class="fm" name="f" action="c.biancheng.net">
- <span class="btn"></span>
- <input id="kw" class="s_ipt_wr" name="wd" value="" maxlength="255" autocomplete="off">
- </body>
- </head>
- </html>
下面使用表格中提供的方法定位 input 输出框。如下所示:
- #创建browser是浏览器对象
- browser = webdriver.Chrome()
- #访问某个url得到上述代码片段
- browser.get('url')
- #通过id定义输入框
- browser.dr.find_element_by_id("kw")
- #通过class定义
- browser.find_element_by_class_name("s_ipt_wr")
- #通过name定位
- browser.find_element_by_name("wd")
- #通过tag name定位:
- browser.find_element_by_tag_name("input")
- #通过xpath定位
- browser.find_element_by_xpath("//*[@id='kw']")
- #通过css选择器定位
- browser.find_element_by_css_selector("#kw")
通过 a 标签内的文本内容定位节点,如下所示:
<a class="vip" href="http://c.baincheng.net">C语言中文网</a>
<a class="search" href="http://www.baidu.com">hao123</a>
示例如下:
- #使用全部文本内容定位链接
- browser.find_element_by_link_text("c语言中文网")
- #使用部分文本内容定位链接
- browser.find_element_by_partial_link_text("123")
如果您想定位一组元素,方法如下所示:
find_elements_by_id()
find_elements_by_name()
find_elements_by_class_name()
find_elements_by_tag_name()
find_elements_by_link_text()
find_elements_by_partial_link_text()
find_elements_by_xpath()
find_elements_by_css_selector()
定位一组元素的方法与定位单个元素类似,唯一的区别就是 element 后面多了一个 s(表示复数),因此上述方法的返回值是一个列表,您可以使用 for 循环拿到所有的元素节点。
控制浏览器
Selenium 可以操控浏览器的窗口大小、刷新页面,以及控制浏览器的前进、后退等
1) 设置浏览器窗口大小、位置
- from selenium import webdriver
- driver = webdriver.Chrome()
- driver.get("http://www.baidu.com")
- #参数数字为像素点
- driver.set_window_size(480, 800)
- #设置窗口位置
- driver.set_window_position(100,200)
- #同时设置窗口的大小和坐标
- driver.set_window_rect(450,300,32,50)
- #退出浏览器
- driver.quit()
2) 控制网页前进、后退、刷新页面
- from selenium import webdriver
- driver = webdriver.Chrome()
- # 访问C语言中文网首页
- first_url= 'http://c.biancheng.net'
- driver.get(first_url)
- # 访问c语言教程
- second_url='http://c.biancheng.net/c/'
- driver.get(second_url)
- # 返回(后退)到c语言中文网首页
- driver.back()
- # 前进到C语言教程页
- driver.forward()
- # 刷新当前页面相当于F5
- driver.refresh()
- # 退出/关闭浏览器
- driver.quit()
WebDriver常用方法
上文中介绍了如何定位元素,以及如何设置浏览的大小、位置。 定位元素节点只是第一步, 定位之后还需要对这个元素进行操作, 比如单击按钮,或者在输入框输入文本 , 下面介绍 WebDriver 中的最常用方法:
# 请求url
get(url)
# 模拟键盘输入文本
send_keys (value)
# 清除已经输入的文本
clear():
# 单击已经定位的元素
click():
# 用于提交表单,比如百度搜索框内输入关键字之后的“回车” 操作
submit():
#返回属性的属性值,返回元素的属性值,可以是id、name、type 或其他任意属性
get_attribute(name)
# 返回布尔值,检查元素是否用户可见,比如 display属性为hidden或者none
is_displayed()
示例如下:
- from selenium import webdriver
- import time
- driver = webdriver.Chrome()
- driver.get("https://www.baidu.com")
- #模拟键盘,输出文本
- driver.find_element_by_id("kw").send_keys("C语言中文网")
- #单击“百度”一下查找
- driver.find_element_by_id("su").click()
- time.sleep(3)
- #退出浏览器
- driver.quit()
除了上述方法外, WebDriver 还有一些常用属性,如下所示:
- from selenium import webdriver
- driver = webdriver.Chrome()
- # 获取HTML结构源码
- driver.page_source
- #在源码中查找指定的字符串
- driver.page_source.find('字符串')
- # 返回百度页面底部备案信息
- text = driver.find_element_by_id("cp").text
- print(text)
- # 获取输入框的尺寸
- size = driver.find_element_by_id('kw').size
- print(size)
输出结果:
2015 Baidu 使用百度前必读 意见反馈 京 ICP 证 030173 号
{'width': 500, 'height': 22}
Selenium事件处理
Selenium WebDriver 提供了一些事件处理函数(鼠标、键盘等),下面我们对常用的事件函数做简单介绍。
1) 鼠标事件
Selenium WebDriver 将关于鼠标的操作方法都封装在 ActionChains 类中,使用时需要引入 ActionChains 类,如下所示:
from selenium.webdriver.common.action_chains import ActionChains
该类包含了鼠标操作的常用方法:
| 方法 | 说明 |
|---|---|
| ActionChains(driver) | 构造 ActionChains 鼠标对象。 |
| click() | 单击 |
| click_and_hold(on_element=None) | 单击鼠标左键,不松开 |
| context_click() | 右击 |
| double_click() | 双击 |
| drag_and_drop() | 拖动 |
| move_to_element(above) | 执行鼠标悬停操作 |
| context_click() | 用于模拟鼠标右键操作, 在调用时需要指定元素定位。 |
| perform() | 将所有鼠标操作提交执行。 |
示例如下:
- from selenium import webdriver
- #导入 ActionChains 类
- from selenium.webdriver.common.action_chains import ActionChains
- driver = webdriver.Chrome()
- driver.get("http://c.biancheng.net")
- # 通过xpath表达式定位到要悬停的元素
- above = driver.find_element_by_xpath('//ul[@id="ad-link-top"]/li[1]')
- # 对定位到的元素执行鼠标悬停操作
- ActionChains(driver).move_to_element(above).perform()
2) 键盘事件
Selenium WebDriver 的 Keys 模块提供了模拟键盘输入的 send_keys() 方法,除此之外,该模块也提供了操作键盘的其他方法,比如复制、粘贴等等。
在使用之前,首先需要导入 Keys 类,如下所示:
from selenium.webdriver.common.keys import Keys
下面列举了一些常用方法:
| 方法 | 说明 |
|---|---|
| send_keys(Keys.BACK_SPACE) | 删除键(BackSpace) |
| send_keys(Keys.SPACE) | 空格键(Space) |
| send_keys(Keys.TAB) | 制表键(Tab) |
| send_keys(Keys.ESCAPE) | 回退键(Esc) |
| send_keys(Keys.ENTER) | 回车键(Enter) |
| send_keys(Keys.CONTROL,'a') | 全选(Ctrl+A) |
| send_keys(Keys.CONTROL,'c') | 复制(Ctrl+C) |
| send_keys(Keys.CONTROL,'x') | 剪切(Ctrl+X) |
| send_keys(Keys.CONTROL,'v') | 粘贴(Ctrl+V) |
| send_keys(Keys.F1…Fn) | 键盘 F1…Fn |
| keys.down(value,element=None) | 按下键盘上的某个键 |
| keys.up(value,element=None) | 松开键盘上的某个键 |
示例如下:
- from selenium import webdriver
- # 引入 Keys 模块
- from selenium.webdriver.common.keys import Keys
- driver = webdriver.Chrome()
- driver.get("http://www.baidu.com")
- # 输入框输入内容
- driver.find_element_by_id("kw").send_keys("C语言中文网H")
- # 删除多输入的一个H
- driver.find_element_by_id("kw").send_keys(Keys.BACK_SPACE)
- #单击“百度”一下查找
- driver.find_element_by_id("su").click()
- time.sleep(3)
- driver.quit()
其它键盘操作方法,如下所示:
- # 输入空格键 + “Python教程”
- driver.find_element_by_id("kw").send_keys(Keys.SPACE)
- driver.find_element_by_id("kw").send_keys("Python教程")
- # ctrl+a 全选输入框内容
- driver.find_element_by_id("kw").send_keys(Keys.CONTROL, 'a')
- # ctrl+x 剪切输入框内容
- driver.find_element_by_id("kw").send_keys(Keys.CONTROL, 'x')
- # ctrl+v 粘贴内容到输入框
- driver.find_element_by_id("kw").send_keys(Keys.CONTROL, 'v')
- # 使用回车键来代替单击操作click
- driver.find_element_by_id("su").send_keys(Keys.ENTER)
无界面浏览器
Chromedriver 每一次运行都要打开浏览器,并执行相应的输入、搜索等操作,这样会导致浏览器交互能力变差,浪费许多时间。 Selenium 为了增强浏览器的交互能力,允许您使用无头浏览器模式,也就是无界面浏览器,它被广泛的应用于爬虫和自动化测试中。通过以下代码可以设置无头浏览器模式:
- from selenium import webdriver
- import time
- options=webdriver.ChromeOptions()
- options.add_argument('--headless')#无界面浏览
- driver=webdriver.Chrome(options=options)
- driver.get('https://www.baidu.com')
- kw1=driver.find_element_by_id('kw')
- print(driver.title)
- time.sleep(3)
- #关闭当前界面,只有一个窗口
- driver.close()
- #关闭所有界面
- driver.quit()
除了可以设置无头界面之外,Selenium 还支持其他一些浏览器参数设置,如下所示:
opption.add_argument('--window-size=600,600') #设置窗口大小
opption.add_argument('--incognito') #无痕模式
opption.add_argument('--disable-infobars') #去掉chrome正受到自动测试软件的控制的提示
opption.add_argument('user-agent="XXXX"') #添加请求头
opption.add_argument("--proxy-server=http://200.130.123.43:3456")#代理服务器访问
opption.add_experimental_option('excludeSwitches', ['enable-automation'])#开发者模式
opption.add_argument('blink-settings=imagesEnabled=false') #禁止加载图片
opption.add_argument('lang=zh_CN.UTF-8') #设置默认编码为utf-8
opption.add_extension(create_proxyauth_extension(
proxy_host='host',
proxy_port='port',
proxy_username="username",
proxy_password="password"
))# 设置有账号密码的代理
opption.add_argument('--disable-gpu') # 这个参数可以规避谷歌的部分bug
opption.add_argument('--disable-javascript') # 禁用javascript
opption.add_argument('--hide-scrollbars') # 隐藏滚动条
执行JS脚本
WebDriver 提供了 execute_script() 方法来执行 JavaScript 代码,比如控制浏览器的滚动条。示例如下:
- from selenium import webdriver
- from time import sleep
- # 访问百度
- driver=webdriver.Chrome()
- driver.get("http://www.baidu.com")
- # 最大化浏览器窗口
- driver.maximize_window()
- # 搜索
- driver.find_element_by_id("kw").send_keys("C语言中文网")
- driver.find_element_by_id("su").click()
- sleep(3)
- # 通过js代码设置滚动条位置,数值代表(左边距,上边距)
- js="window.scrollTo(100,500);"
- #执行js代码
- driver.execute_script(js)
- sleep(5)
- driver.quit()
biancheng-Python爬虫教程的更多相关文章
- Python爬虫教程-11-proxy代理IP,隐藏地址(猫眼电影)
Python爬虫教程-11-proxy代理IP,隐藏地址(猫眼电影) ProxyHandler处理(代理服务器),使用代理IP,是爬虫的常用手段,通常使用UserAgent 伪装浏览器爬取仍然可能被网 ...
- Python爬虫教程-10-UserAgent和常见浏览器UA值
Python爬虫教程-10-UserAgent和常见浏览器UA值 有时候使用爬虫会被网站封了IP,所以需要去模拟浏览器,隐藏用户身份, UserAgent 包含浏览器信息,用户身份,设备系统信息 Us ...
- Python爬虫教程-09-error 模块
Python爬虫教程-09-error模块 今天的主角是error,爬取的时候,很容易出现错,所以我们要在代码里做一些,常见错误的处,关于urllib.error URLError URLError ...
- Python爬虫教程-08-post介绍(百度翻译)(下)
Python爬虫教程-08-post介绍(下) 为了更多的设置请求信息,单纯的通过urlopen已经不太能满足需求,此时需要使用request.Request类 构造Request 实例 req = ...
- Python爬虫教程-07-post介绍(百度翻译)(上)
Python爬虫教程-07-post介绍(百度翻译)(上) 访问网络两种方法 get: 利用参数给服务器传递信息 参数为dict,使用parse编码 post :(今天给大家介绍的post) 一般向服 ...
- Python爬虫教程-01-爬虫介绍
Spider-01-爬虫介绍 Python 爬虫的知识量不是特别大,但是需要不停和网页打交道,每个网页情况都有所差异,所以对应变能力有些要求 爬虫准备工作 参考资料 精通Python爬虫框架Scrap ...
- Python爬虫教程-00-写在前面
鉴于好多人想学Python爬虫,缺没有简单易学的教程,我将在CSDN和大家分享Python爬虫的学习笔记,不定期更新 基础要求 Python 基础知识 Python 的基础知识,大家可以去菜鸟教程进行 ...
- Python爬虫教程-34-分布式爬虫介绍
Python爬虫教程-34-分布式爬虫介绍 分布式爬虫在实际应用中还算是多的,本篇简单介绍一下分布式爬虫 什么是分布式爬虫 分布式爬虫就是多台计算机上都安装爬虫程序,重点是联合采集.单机爬虫就是只在一 ...
- Python爬虫教程-33-scrapy shell 的使用
本篇详细介绍 scrapy shell 的使用,也介绍了使用 xpath 进行精确查找 Python爬虫教程-33-scrapy shell 的使用 scrapy shell 的使用 条件:我们需要先 ...
- Python爬虫教程-32-Scrapy 爬虫框架项目 Settings.py 介绍
本篇介绍项目开发的过程中,对 Setting 文件的配置和使用 Python爬虫教程-32-Scrapy 爬虫框架项目 Settings.py 介绍 settings.py 文件的使用 想要详细查看 ...
随机推荐
- 基于Java+SpringBoot+Mysql实现的古诗词平台功能设计与实现九
一.前言介绍: 1.1 项目摘要 随着信息技术的迅猛发展和数字化时代的到来,传统文化与现代科技的融合已成为一种趋势.古诗词作为中华民族的文化瑰宝,具有深厚的历史底蕴和独特的艺术魅力.然而,在现代社会中 ...
- 2023NOIP A层联测26 T3 tour
2023NOIP A层联测26 T3 tour 有意思的树上主席树. 思路 首先考虑一个点 \(p\) 能计入答案的情况,就是 \(dis(x,p)-a_p \ge a_p\). 我们把 \(x \t ...
- 记录个Java/Groovy的小问题:空字符串调用split函数返回非空数组
问题复现 最近写了一个groovy替换程序增量流水线脚本(会Java也能看懂),示意脚本如下: //获取文件列表方法 def listFiles(folder) { def output = sh(s ...
- gh-ost工具在线改表过程的详细解析
gh-ost,是github开源的一款在线修改MySQL表结构的工具https://github.com/github/gh-ost/,它不使用pt-osc的触发器机制,而是使用解析binlog来实现 ...
- 优秀的 Java 程序员所应该知道的 Java 知识
JDK 相关知识 JDK 的使用 JDK 源代码 JDK 相应技术背后的原理 JVM 相关知识 服务器端开发需要重点熟悉的 Java 技术 Java 并发 Java IO 开源框架 Java 之外的知 ...
- Java深度历险(六)——Java注解——(七)——Java反射与动态代理
在开发Java程序,尤其是Java EE应用的时候,总是免不了与各种配置文件打交道.以Java EE中典型的S(pring)S(truts)H(ibernate)架构来说,Spring.Struts和 ...
- 基于Docker搭建PHP开发环境
Docker 是这几年非常火的一项技术,作为一名软件开发人员,应该及时的接触和掌握. 镜像加速: 可以在阿里云上免费的获取,然后进行配置即可使用.阿里云 Docker 加速器,没有阿里云账号注册一个即 ...
- Celery之监控与管理
Celery两种监控工具: 命令行实用工具和Web实时监控工具Flower 一.命令行工具 1)进入shell环境 celery -A myCeleryProj.app shell Python 3. ...
- Nuxt.js 应用中的 request 事件钩子
title: Nuxt.js 应用中的 request 事件钩子 date: 2024/12/4 updated: 2024/12/4 author: cmdragon excerpt: 在构建现代 ...
- ecognition server注意事项
1.4002端口是节点管理界面,默认密码admin. 2.8184端口是任务管理界面. 3.节点在线状态下,查看提交的影像矢量路径是否正确. 4.看服务器读取各个文件是否有误. 5.用develope ...