Cs231n课堂内容记录-Lecture 8 深度学习框架
Lecture 8 Deep Learning Software
课堂笔记参见:https://blog.csdn.net/u012554092/article/details/78159316
今天我们来介绍深度学习软件,它们的性能、优劣以及应用流程,包括CPU、GPU和一些流行的深度学习框架。

一、 CPU vs GPU
GPU被称作显卡(graphics card),或者图形处理器(Graphics Processing Unit),是一种专门进行图像运算工作的微处理器。这里不得不提到NVIDIA和AMD,深度学习中往往采用NVIDIA。CPU只有少量的核,这意味着它们可以同时运行4到20个线程,且运作相互独立。GPU都有成千上万的核数,NVIDIA Titan Xp有3840个核,GPU的缺点是每一个核的运行速度非常慢,而且它们能够执行的操作没有CPU多,它们没办法独立操作,只能多个核合作完成某项任务。所以我们不能直观地比较CPU和GPU的核数。
在内存上,CPU有高速缓存,但是相对较小,一般是4到32GB,取决于RAM;GPU在芯片中内置了RAM,Titan Xp内置内存有12 GB。GPU同样有自己的缓存系统,在GPU的12个G内存和核之间有多级缓存,实际上和CPU的多层缓存相似。CPU对于通信处理来说是足够的,可以做很多事情,GPU则更加擅长高度并行处理。最典型的算法就是矩阵乘法,矩阵的各行各列的点积运算都是独立的,所以可以进行并行运算。CPU可能会进行串行运算,一个一个地计算矩阵元素,这会导致你的运算速度很慢。
我们可以在GPU上写出可以直接运行的程序,NVIDIA有个叫做CUBA的抽象代码,可以让你写出类C的代码,可以在GPU上直接运行。但是写CUDA代码不太容易,想要写出高性能有充分发挥GPU优势的CUDA代码实际上是很困难的。你必须非常谨慎地管理内存结构并且不遗漏任何一个高速缓存以及分支误预测等等。NVIDIA开源了很多库可以用来实现高度优化的GPU的通用计算功能,比如cuBLAS库可以实现各种各样的矩阵乘法。cuDNN可以实现卷积、前向和反向传播、批归一化、递归神经网络等各种各样的功能。所以在做深度学习项目时你不需要自己编写CUDA代码而是直接调用已经写好的代码。
另一种语言是OpenCL,这种语言更加普及,可以在GPU、CPU以及AMD上运行,但是没有人花费大量的精力优化深度学习代码,所以性能没有CUDA好。在目前看来,NVIDIA有绝对的优势。
二、 Deep Learning Frameworks
1.深度学习框架的优点:
(1) Easily build big computational graphs
(2) Easily compute gradients in computational graphs
(3) Run it all efficiently on GPU (wrap cuDNN, cuBLAS, etc)
2.各个框架:
numpy的缺点是无法提供梯度计算,所以只能自己写。另外不能在GPU上运行,只能在CPU上运行。

之后多数框架的思路大体都是希望前向网络的书写类似于numpy,但是可以在GPU上运行,又能自动计算梯度。tensorflow实现了这一点,另外你可以实现CPU和GPU的转换,比如在前向网络之前加入一行如图的代码。

3.tensorflow:

这里我们定义了一个两层的全连接网络,来作为tf的讲解实例:

这些占位符是计算图的输入结点,我们的数据会输入到这个节点,从而进入计算图中。

maximum定义了一个RELU函数,这几行代码没有做实质性的运算,只是建立图模型。

大多时候tf是从np中接收数据,我们使用字典存储这些数据。

我们告诉模型希望计算w1和w2的loss,并且通过字典参数传递数据字典。
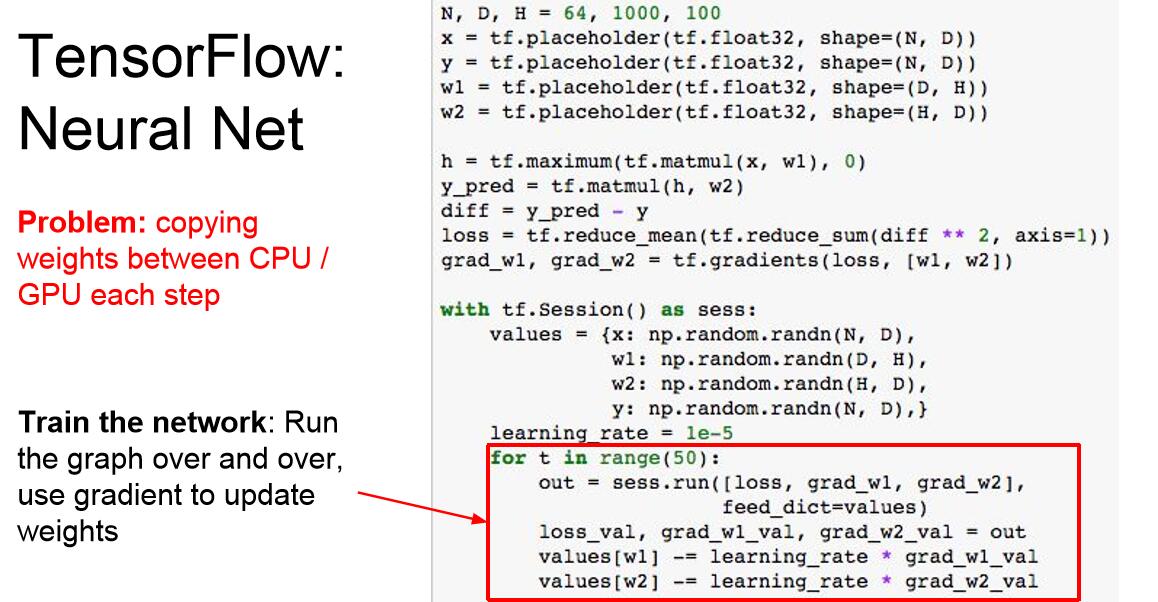
我们每一次运算图都需要从numpy数组中复制权重到tensorflow中才能得到梯度,然后将梯度复制回np数组,如果你的权重值和梯度值非常多,需要在GPU上运行的时候,np到tf的过程就是CPU到GPU的数据传输,而这个过程是极其浪费时间、耗费资源的。

解决方案是我们将w1,w2变为变量而不是输入入口,这样它们就可以存储在tf网络中,这是我们需要在tf网络中初始化这些变量,所以用random_normal初始化,这个语句并没有真正初始化,而是告诉tf应该怎样进行初始化,更新操作也要在tf计算图中进行。

全局参数的初始化操作。

这是因为我们并没有将new_w1和new_w2加入计算图中参与运算。我们只告诉tf说要计算loss,这并不需要执行更新操作,所以tf只执行了要求结果所必须的操作。

但是这里还有一个问题,neww1和neww2都是很大的张量,当我们告诉tf我们需要这些输出时(也就是像loss一样让tf输出它们到np中),每次迭代就会在CPU和GPU之间执行这些操作,这是我们不希望的,所以我们在计算图中添加一个仿制节点,这个节点不输出任何值,只是保证计算图进行了更新操作。
问题1:为什么我们不把x、y也放入计算图中?
TA解释:在这个计算图中,我们每一次迭代都重复使用了同样的X和Y,所以在这个例子中应该被放入计算图中,但是更为常用的情况是x和y是数据集的mini batch,所以它们在每次迭代之后都是变化的。
合理解释:因为w1和w2是与数据无关对的,本身更类似于计算图中可以自我更新的属性,所以我们初始化之后就不用保留传输接口而只让它们在计算图中更新就行。但是x和y是数据集的mini batch,所以它们在每次迭代之后都要重新输入的。
问题2:tf.group返回了什么?
这是tf的一个小trick,当你在计算图中内部执行group的时候,它返回的是一个具体的值,类似于节点内部的操作值,告诉计算图我需要进行更新;而当你执行Session.run的时候,返回的就是None,因为你没有定义计算图要输出的是什么,所以计算图只会执行操作,而不输出值。
问题3:为什么loss的返回值是一个值,而updates就是none呢?
loss是一个值,而updates可以看成是一种特殊的数据类型,它并不返回值,而返回空。实际上是因为tf.reduce.mean的返回值就是一个具体的值,而group的返回是一个操作。
参见官方文档中关于group的说明:
https://www.tensorflow.org/api_docs/python/tf/group?hl=zh-cn

group操作过于麻烦,tf给我们提供了更为便捷的操作,也就是optimizer,它帮助我们进行更新操作。这时它会将w1和w2这些变量在默认情况下被标记为可训练,因此在minimize中会将w1、w2加入计算图中并算出w1和w2的损失梯度,然后执行更新操作,minimize代码中包含了group操作。

tf可以帮助我们实现L2距离的张量计算。

关于权重,偏置和输入值的初始化以及形状设置等等小细节方面,tf也为我们提供了很多库,比如tf.layers.dense(),我们仅仅显式说明了作为占位符的x和y,然后将x作为输入,单元数为H。在这神奇的一行里,自动设置了w1和b1,并用xavier_initializer初始化变量(之前我们用的是randomnormal),这极大地为我们节省了中间过程。
在这里,我们同样传入了tf.nn.relu这个激活函数,表示该层的激活函数是ReLU。我们使用了两次layers.dense来帮助我们构建整个网络,这样方便很多。
4.Keras:
另一个很受欢迎的包是Keras,这是一个非常方便的API,建立在tf的基础上,可以在后端为你处理计算图操作。

这里我们构建了一个序列层的模型,优化器,以及调用model.compile来建立计算图,然后我们调用了model.fit自动为我们完成整个训练过程。

以上是一些官方文档的地址。
5.Pytorch:
Facebook的Pytorch不同于tf,pytorch内部明确定义了三层抽象,pytorch的张量对象就像numpy数组,这是一种基本数组,可以在GPU上运行;我们有变量对象,是计算图中的节点;模对象是一个神经网络层,可以将这些模组合起来建立一个大的网络。

pytorch和tf的对比图。
Cs231n课堂内容记录-Lecture 8 深度学习框架的更多相关文章
- Cs231n课堂内容记录-Lecture 9 深度学习模型
Lecture 9 CNN Architectures 参见:https://blog.csdn.net/qq_29176963/article/details/82882080#GoogleNet_ ...
- Cs231n课堂内容记录-Lecture 3 最优化
Lecture 4 最优化 课程内容记录: (上)https://zhuanlan.zhihu.com/p/21360434?refer=intelligentunit (下)https://zhua ...
- Cs231n课堂内容记录-Lecture 7 神经网络训练2
Lecture 7 Training Neural Networks 2 课堂笔记参见:https://zhuanlan.zhihu.com/p/21560667?refer=intelligent ...
- Cs231n课堂内容记录-Lecture 4-Part1 反向传播及神经网络
反向传播 课程内容记录:https://zhuanlan.zhihu.com/p/21407711?refer=intelligentunit 雅克比矩阵(Jacobian matrix) 参见ht ...
- Cs231n课堂内容记录-Lecture 4-Part2 神经网络
Lecture 7 神经网络二 课程内容记录:https://zhuanlan.zhihu.com/p/21560667?refer=intelligentunit 1.协方差矩阵: 协方差(Cova ...
- Cs231n课堂内容记录-Lecture 6 神经网络训练
Lecture 6 Training Neural Networks 课堂笔记参见:https://zhuanlan.zhihu.com/p/22038289?refer=intelligentun ...
- Cs231n课堂内容记录-Lecture 5 卷积神经网络介绍
Lecture 5 CNN 课堂笔记参见:https://zhuanlan.zhihu.com/p/22038289?refer=intelligentunit 不错的总结笔记:https://blo ...
- Cs231n课堂内容记录-Lecture1 导论
Lecture 1 视频网址:https://www.bilibili.com/video/av17204303/?p=2 https://zhuanlan.zhihu.com/p/21930884? ...
- Cs231n课堂内容记录-Lecture2-Part2 线性分类
Lecture 3 课程内容记录:(上)https://zhuanlan.zhihu.com/p/20918580?refer=intelligentunit (中)https://zhuanlan. ...
随机推荐
- Json数组转换字符串、字符串转换原数组......
<!DOCTYPE html><html lang="en"><head> <meta charset="UTF-8" ...
- 13.Git分支-变基(rebase)、rebase VS merge
1.变基的基本操作 在Git中整合来自不同分支的修改主要有两种方法:merge和rebase. 看下面的例子: 开发任务分叉到了两个不同的分支,并且都有了新的提交. 这时候我们可以使用 git mer ...
- 6.Git基础-远程仓库的使用
远程仓库是指托管在因特网或其他网络中的你的项目的版本库.比如你在GitHub中托管的代码库,就是远程仓库. 1.查看远程仓库 -- git remote git remote 查看已经配置的远程仓 ...
- Hbase篇--Hbase和MapReduce结合Api
一.前述 Mapreduce可以自定义Inputforma对象和OutPutformat对象,所以原理上Mapreduce可以和任意输入源结合. 二.步骤 将结果写会到hbase中去. 2.1 Ma ...
- Django知识点
一.Django pip3 install django C:\Python35\Scripts # 创建Django工程 django-adm ...
- 【3分钟就会系列】使用Ocelot+Consul搭建微服务吧!
一.什么Ocelot? API网关是一个服务器,是系统的唯一入口.API 网关一般放到微服务的最前端,并且要让API 网关变成由应用所发起的每个请求的入口.这样就可以明显的简化客户端实现和微服务应用程 ...
- 说一说MVC的MenuCard(五)
1.数据库设计 create database BookShop go use bookshop go --模块表 create table Module ( ModuleID ,), ModuleN ...
- 『Pushing Boxes 双重bfs』
Pushing Boxes Description Imagine you are standing inside a two-dimensional maze composed of square ...
- 爬虫协议 Tobots
一.简介 Robots 协议(也称为爬虫协议.机器人协议等)的全称是“网络爬虫排除标准”(Robots Exclusion Protocol),网站通过 Robots 协议告诉搜索引擎哪些页面可以抓取 ...
- 滚动 docker 中的 nginx 日志
Nginx 自己没有处理日志的滚动问题,它把这个球踢给了使用者.一般情况下,你可以使用 logrotate 工具来完成这个任务,或者如果你愿意,你可以写各式各样的脚本完成同样的任务.本文笔者介绍如何滚 ...