Spark DAGSheduler生成Stage过程分析实验
RDD.Action触发SparkContext.run,这里举最简单的例子rdd.count()
/**
* Return the number of elements in the RDD.
*/
def count(): Long = sc.runJob(this, Utils.getIteratorSize _).sum
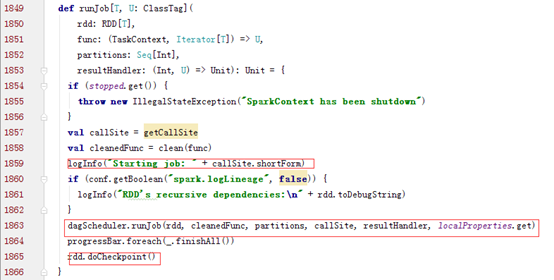
Spark Action会触发SparkContext类的runJob,而runJob会继续调用DAGSchduler类的runJob

DAGSchduler类的runJob方法调用submitJob方法,并根据返回的completionFulture的value判断Job是否完成。
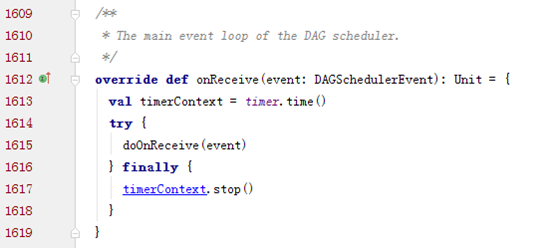
onReceive用于DAGScheduler不断循环的处理事件,其中submitJob()会产生JobSubmitted事件,进而触发handleJobSubmitted方法。

正常情况下会根据finalStage创建一个ActiveJob。而finalStage就是由spark action对应的finalRDD生成的,而该stage要确认所有依赖的stage都执行完,才可以执行。也就是通过getMessingParentStages方法判断的。

这个方法用一个栈来实现递归的切分stage,然后返回一个宽依赖的HashSet,如果是宽依赖类型就会调用
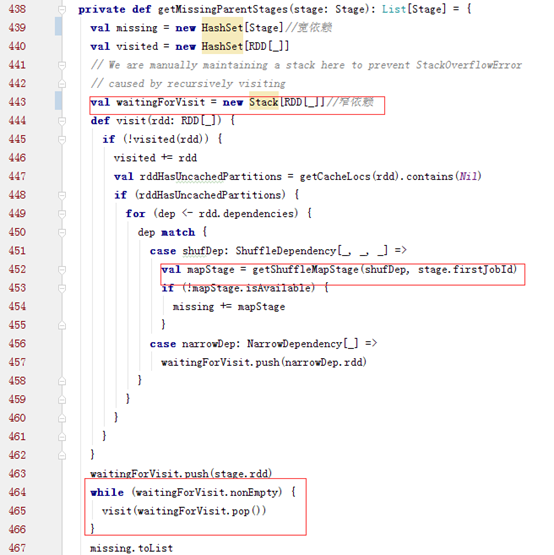
之后提交stage,根据missingStage执行各个stage。划分DAG结束

submitStage会依次执行这个DAG中的stage,如果有父stage就先执行父stage,否则就提交这个stage,加入watingstages中。

示例:
scala> sc.makeRDD(Seq(1,2,3)).count
16/10/28 17:54:59 [INFO] [org.apache.spark.SparkContext:59] - Starting job: count at <console>:13
16/10/28 17:54:59 [INFO] [org.apache.spark.scheduler.DAGScheduler:59] - Got job 0 (count at <console>:13) with 22 output partitions (allowLocal=false)
16/10/28 17:54:59 [INFO] [org.apache.spark.scheduler.DAGScheduler:59] - Final stage: Stage 0(count at <console>:13)
16/10/28 17:54:59 [INFO] [org.apache.spark.scheduler.DAGScheduler:59] - Parents of final stage: List()
16/10/28 17:54:59 [INFO] [org.apache.spark.scheduler.DAGScheduler:59] - Missing parents: List()
16/10/28 17:54:59 [INFO] [org.apache.spark.scheduler.DAGScheduler:59] - Submitting Stage 0 (ParallelCollectionRDD[0] at makeRDD at <console>:13), which has no missing parents
scala> sc.makeRDD(Seq(1,2,3)).map(l =>(l,1)).reduceByKey((v1,v2) => v1+v2).collect
16/10/28 18:00:07 [INFO] [org.apache.spark.SparkContext:59] - Starting job: collect at <console>:13
16/10/28 18:00:07 [INFO] [org.apache.spark.scheduler.DAGScheduler:59] - Registering RDD 2 (map at <console>:13)
16/10/28 18:00:07 [INFO] [org.apache.spark.scheduler.DAGScheduler:59] - Got job 1 (collect at <console>:13) with 22 output partitions (allowLocal=false)
16/10/28 18:00:07 [INFO] [org.apache.spark.scheduler.DAGScheduler:59] - Final stage: Stage 2(collect at <console>:13)
16/10/28 18:00:07 [INFO] [org.apache.spark.scheduler.DAGScheduler:59] - Parents of final stage: List(Stage 1)
16/10/28 18:00:07 [INFO] [org.apache.spark.scheduler.DAGScheduler:59] - Missing parents: List(Stage 1)
16/10/28 18:00:07 [INFO] [org.apache.spark.scheduler.DAGScheduler:59] - Submitting Stage 1 (MappedRDD[2] at map at <console>:13), which has no missing parents
collect依赖于reduceByKey,reduceByKey依赖于map,而reduceByKey是一个Shuffle操作,故会先提交map (Stage 1 (MappedRDD[2] at map at <console>:13))
Spark DAGSheduler生成Stage过程分析实验的更多相关文章
- Spark2.2+ES6.4.2(三十一):Spark下生成测试数据,并在Spark环境下使用BulkProcessor将测试数据入库到ES
Spark下生成2000w测试数据(每条记录150列) 使用spark生成大量数据过程中遇到问题,如果sc.parallelize(fukeData, 64);的记录数特别大比如500w,1000w时 ...
- Spark 资源调度包 stage 类解析
spark 资源调度包 Stage(阶段) 类解析 Stage 概念 Spark 任务会根据 RDD 之间的依赖关系, 形成一个DAG有向无环图, DAG会被提交给DAGScheduler, DAGS ...
- spark job, stage ,task介绍。
1. spark 如何执行程序? 首先看下spark 的部署图: 节点类型有: 1. master 节点: 常驻master进程,负责管理全部worker节点. 2. worker 节点: 常驻wor ...
- Spark Streaming应用启动过程分析
本文为SparkStreaming源码剖析的第三篇,主要分析SparkStreaming启动过程. 在调用StreamingContext.start方法后,进入JobScheduler.start方 ...
- spark 中划分stage的思路
窄依赖指父RDD的每一个分区最多被一个子RDD的分区所用,表现为 一个父RDD的分区对应于一个子RDD的分区 两个父RDD的分区对应于一个子RDD 的分区. 宽依赖指子RDD的每个分区都要依赖于父RD ...
- spark中job stage task关系
1.1 例子,美国 1880 - 2014 年新生婴儿数据统计 目标:用美国 1880 - 2014 年新生婴儿的数据来做做简单的统计 数据源:https://catalog.data.gov 数据格 ...
- Spark Streaming和Flume-NG对接实验
Spark Streaming是一个新的实时计算的利器,而且还在快速的发展.它将输入流切分成一个个的DStream转换为RDD,从而可以使用Spark来处理.它直接支持多种数据源:Kafka, Flu ...
- Spark(四十八):Spark MetricsSystem信息收集过程分析
MetricsSystem信息收集过程 参考: <Apache Spark源码走读之21 -- WEB UI和Metrics初始化及数据更新过程分析> <Spark Metrics配 ...
- spark 笔记 8: Stage
Stage 是一组独立的任务,他们在一个job中执行相同的功能(function),功能的划分是以shuffle为边界的.DAG调度器以拓扑顺序执行同一个Stage中的task. /** * A st ...
随机推荐
- From cls答辩
我没有想过有一天会因为wjmzbmr而开一篇. 因为看到了cls答辩的链接而震撼或是感动. 可能也跟最近身心比较疲惫有关...容易产生这样那样的感触... cls可能已不是我们这代OIER所能膜到的了 ...
- Java并发编程基础--基本线程方法详解
什么是线程 线程是操作系统调度的最小单位,一个进程中可以有多个线程,这些线程可以各自的计数器,栈,局部变量,并且能够访问共享的内存变量.多线程的优势是可以提高响应时间和吞吐量. 使用多线程 一个进程正 ...
- Jedis 使用范例
public class RedisUtil { Logger logger = LoggerFactory.getLogger(RedisUtil.class); private JedisPool ...
- linux kernel elv_queue_empty野指针访问内核故障定位与解决
1. 故障描述 故障操作步骤: 单板上插了一个U盘,出问题前正在通过FTP往单板上拷贝文件,拷贝的过程中单板自动重启. 故障现象: Entering kdb (current=0xc000000594 ...
- Print a Binary Tree in Vertical Order
http://www.geeksforgeeks.org/print-binary-tree-vertical-order/ package algorithms; import java.util. ...
- PHP浮点数精度问题
这一段时间维护一个类似团购的系统,需要处理订单,也就难免会处理金额 所以有很多PHP的坑 被我狠狠的踩了~~ 首先我们要知道浮点数的表示(IEEE 754): 简言之 就是 埋下了一个大坑 等着你跳 ...
- CruiseControl.Net <buildpublisher>部署到远程机器报错的解决办法
CruiseControl.Net ,使用<buildpublisher>将编译后的程序部署到远程机器时,使用以下配置 <buildpublisher> <sourceD ...
- C# webBrowser 开新窗口保持Session(转)
首先为项目添加引用 Microsoft Internet Controls public Form1() { InitializeComponent(); this.webBrowser1.Allow ...
- CSS居中demo
<!DOCTYPE html> <html lang="en"> <head> <meta charset="UTF-8&q ...
- sqlserver2008附加数据库时提示“无法为该请求检索数据。 (Microsoft.SqlServer.Management.Sdk.Sfc)”
解决方案: 右击SQL Server Management Studio以管理员身份运行,选择与脱机数据库时相同的登陆方式(win还是sa),进入后再附加就是ok了.