手把手使用Python语音识别,进行语音转文字
0. 太长不看系列,直接使用
在1.2官网注册后拿到APISecret和APIKey,直接复制文章2.4demo代码,确定音频为wav格式,采样率为16K,在命令行执行
python single_sentence_recognition.py -client_secret=你的client_secret -client_id=你的client_id -file_path=test.wav
识别结果


使用中有任何问题,欢迎留言提问。
1. Python调用标贝科技语音识别接口,实现语音转文字
1.1 环境准备:
Python 3
1.2 获取权限
标贝科技 https://ai.data-baker.com/#/index
填写邀请码fwwqgs,每日免费调用量还可以翻倍


1.2.1 登录
点击产品地址进行登录,支持短信、密码、微信三种方式登录。

1.2.2 创建新应用
登录后进入【首页概览】,各位开发者可以进行创建多个应用。包括一句话识别、长语音识别、录音文件识别;在线合成、离线合成、长文本合成。
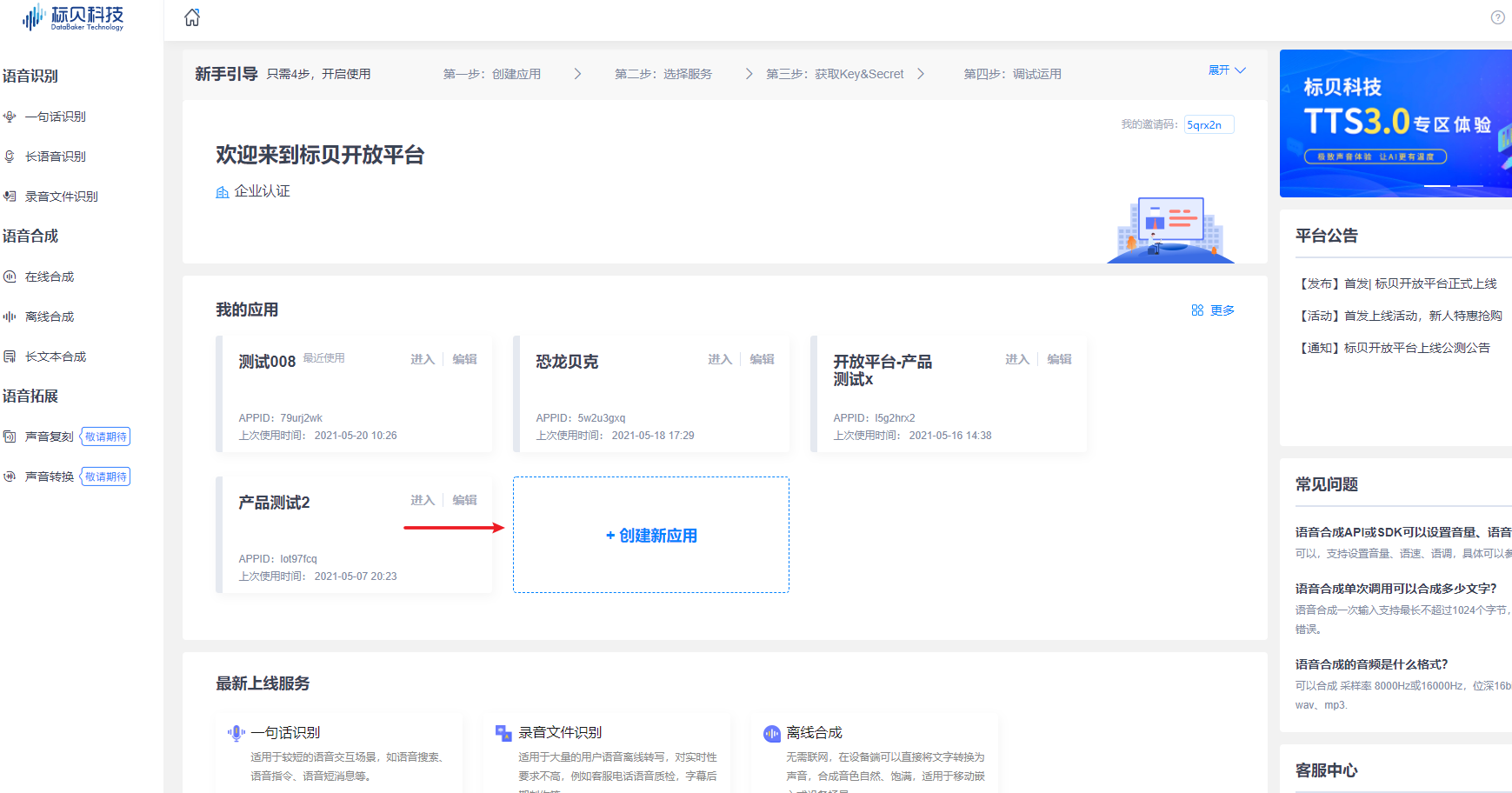
1.2.3 选择服务
进入【已创建的应用】,左侧选择您需调用的AI技术服务,右侧展示对应服务页面概览(您可查询用量、管理套餐、购买服务量、自主获取授权、预警管理)。
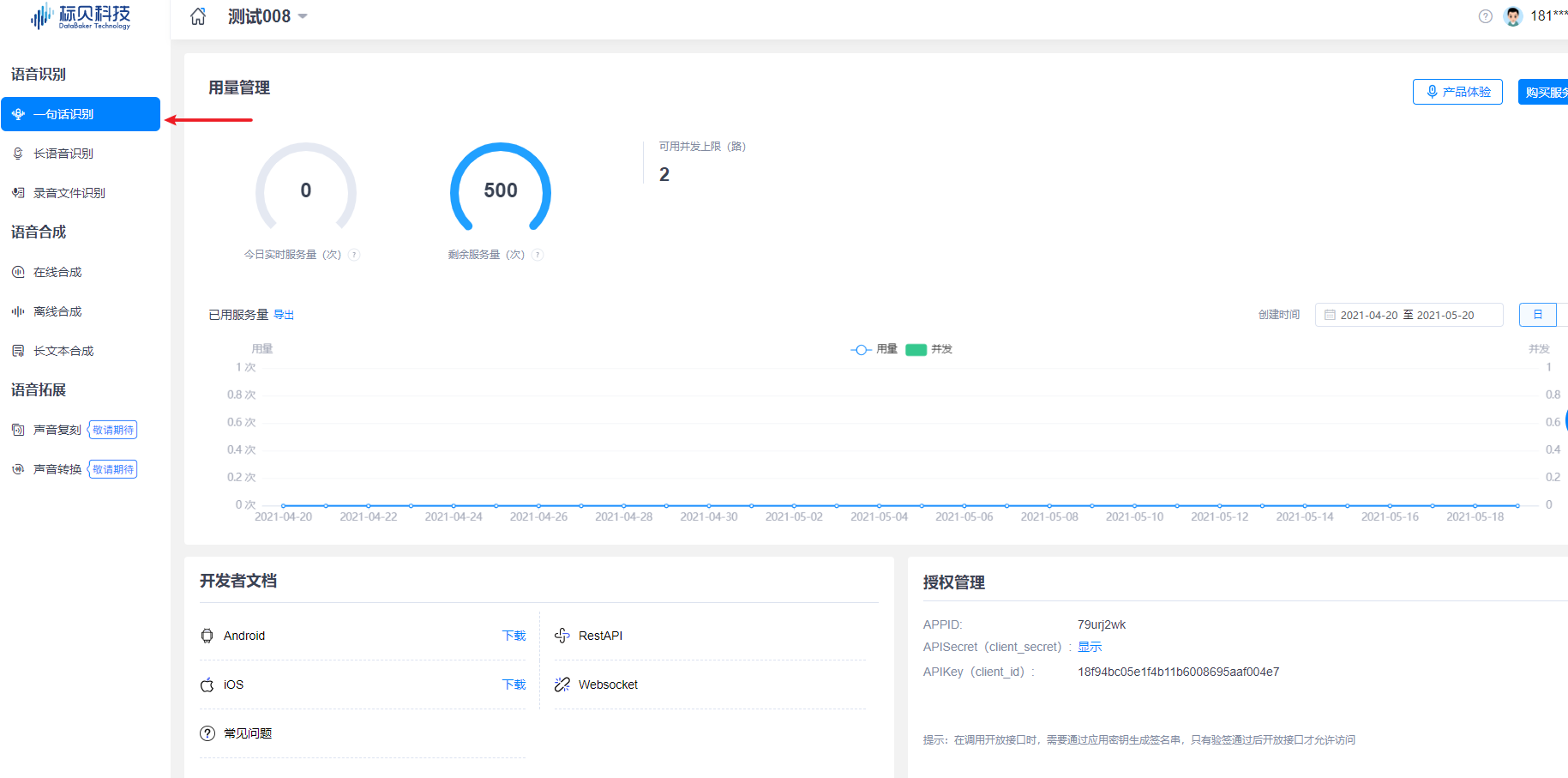
1.2.4 获取Key&Secret
通过服务 / 授权管理,获取对应参数,进行开发配置(获取访问令牌token)
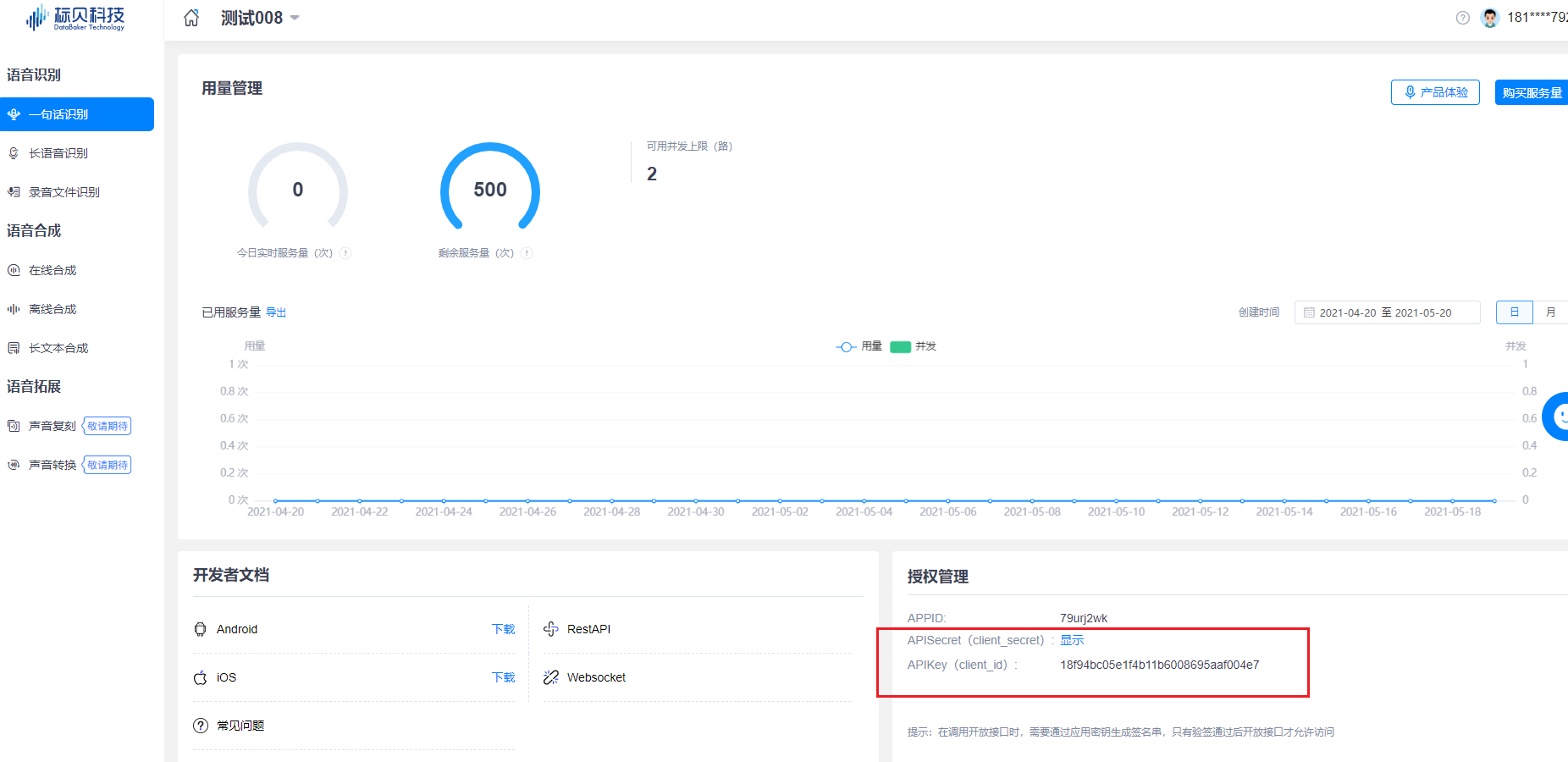
拿到Key和Secret就可以正式使用啦!
2. 代码实现
2.1 获取access_token
在拿到Key和Secret后,我们还需要调用授权接口获取access_token,这个access_token有效时长是24小时。
# 获取access_token用于鉴权
def get_access_token(client_secret, client_id):
grant_type = "client_credentials"
url = "https://openapi.data-baker.com/oauth/2.0/token?grant_type={}&client_secret={}&client_id={}"\
.format(grant_type, client_secret, client_id) try:
response = requests.post(url)
response.raise_for_status()
except Exception as e:
print(e)
return
else:
access_token = json.loads(response.text).get('access_token') return access_token
2.2 获取识别文本
拿到access_token后,调用语音识别接口,就可以获得识别后文本
# 获取识别后文本
def get_text(file, headers):
url = "https://asr.data-baker.com/asr/api?"
response = requests.post(url, data=file, headers=headers)
code = json.loads(response.text).get("code")
text = json.loads(response.text).get("text")
if code != 20000:
print(response.text) return text
2.3 配置接口参数
client_secret和client_id:在文章1.2的官网获取,必填
file_path:文件保存路径,必填
audio_format:音频格式,默认wav,根据文件可以自己选填
sample_rate:采样率,默认16000,根据文件可以自己选填
add_pct:是否在静音处添加标点,默认true
# 获取命令行输入参数
def get_args():
parser = argparse.ArgumentParser(description='ASR')
parser.add_argument('-client_secret', type=str, required=True)
parser.add_argument('-client_id', type=str, required=True)
parser.add_argument('-file_path', type=str, required=True)
parser.add_argument('--audio_format', type=str, default='wav')
parser.add_argument('--sample_rate', type=str, default='16000')
parser.add_argument('--add_pct', type=str, default='true')
args = parser.parse_args() return args
2.4 完整demo
#!/usr/bin/env python
# coding: utf-8 import requests
import json
import argparse # 获取access_token用于鉴权
def get_access_token(client_secret, client_id):
grant_type = "client_credentials"
url = "https://openapi.data-baker.com/oauth/2.0/token?grant_type={}&client_secret={}&client_id={}"\
.format(grant_type, client_secret, client_id) try:
response = requests.post(url)
response.raise_for_status()
except Exception as e:
print(e)
return
else:
access_token = json.loads(response.text).get('access_token') return access_token # 获取识别后文本
def get_text(file, headers):
url = "https://asr.data-baker.com/asr/api?"
response = requests.post(url, data=file, headers=headers)
code = json.loads(response.text).get("code")
text = json.loads(response.text).get("text")
if code != 20000:
print(response.text) return text # 获取命令行输入参数
def get_args():
parser = argparse.ArgumentParser(description='ASR')
parser.add_argument('-client_secret', type=str, required=True)
parser.add_argument('-client_id', type=str, required=True)
parser.add_argument('-file_path', type=str, required=True)
parser.add_argument('--audio_format', type=str, default='wav')
parser.add_argument('--sample_rate', type=str, default='16000')
parser.add_argument('--add_pct', type=str, default='true')
args = parser.parse_args() return args if __name__ == '__main__':
args = get_args() # 获取access_token
client_secret = args.client_secret
client_id = args.client_id
access_token = get_access_token(client_secret, client_id) # 读取音频文件
with open(args.file_path, 'rb') as f:
file = f.read() # 填写Header信息
audio_format = args.audio_format
sample_rate = args.sample_rate
add_pct = args.add_pct
headers = {'access_token': access_token, 'audio_format': audio_format, 'sample_rate': sample_rate,
'add_pct': add_pct}
text = get_text(file, headers)
print(text)
2.5 执行
复制所有代码,确定音频为wav格式,采样率为16K,在命令行执行
python single_sentence_recognition.py -client_secret=你的client_secret -client_id=你的client_id -file_path=test.wav
结果

手把手使用Python语音识别,进行语音转文字的更多相关文章
- Python使用websocket调用语音识别,语音转文字
@ 目录 0. 太长不看系列,直接使用 1. Python调用标贝科技语音识别websocket接口,实现语音转文字 1.1 环境准备: 1.2 获取权限 1.2.1 登录 1.2.2 创建新应用 1 ...
- 语音识别(语音转文字)&& 语音合成(文字转语音)
[语音合成API]SpeechSynthesisUtterance是HTML5中新增的API,用于将指定文字合成为对应的语音.也包含一些配置项,指定如何去阅读(语言,音量,音调)等 // 语音播报 s ...
- C# 语音识别(文字to语音、语音to文字)
最近打算研究一下语音识别,但是发现网上很少有C#的完整代码,就把自己的学习心得放上来,和大家分享一下. 下载API: 1)SpeechSDK51.exe (67.0 ...
- 机器人之路的第一小步:录音+语音识别(语音转文字),大小600K(免费下载)!
机器人之路的第一小步:录音+语音识别(语音转文字),大小600K,本人出品! 机器人之路的第一小步:录音+语音识别,准确率还不是特别高,不过普通话标准的话,识别准确率还是不错的,大家可以体验一下,请下 ...
- 语音识别系统:有免费实用的"语音到文字"的软件么?
自从看了<李开复自传>,就对"语音识别系统"产生了非常深刻的印象. 根据自己的判断,语音识别系统还是非常有用的. 以自己的实际需求来看: 1.中国象棋中的应用. 中国象 ...
- Python 语音识别
调用科大讯飞语音听写,使用Python实现语音识别,将实时语音转换为文字. 参考这篇博客实现的录音,首先在官网下载了关于语音听写的SDK,然后在文件夹内新建了两个.py文件,分别是get_audio. ...
- 基于百度语音识别API的Python语音识别小程序
一.功能概述 实现语音为文字,可以扩展到多种场景进行工作,这里只实现其基本的语言接收及转换功能. 在语言录入时,根据语言内容的多少与停顿时间,自动截取音频进行转换. 工作示例: 二.软件环境 操作系统 ...
- iOS 10中如何搭建一个语音转文字框架
在2016WWDC大会上,Apple公司介绍了一个很好的语音识别的API,那就是Speech framework.事实上,这个Speech Kit就是Siri用来做语音识别的框架.如今已经有一些可用的 ...
- iOS语音播报文字
记得大学的时候学微软Window Phone时,有语音识别类似苹果的嘿,Siri.今天无聊百度搜了一下,搜到苹果语音播报文字.自己试了下还挺好玩. 1.引入框架#import <AVFounda ...
随机推荐
- 【】maven 配置启动tomcat版本,修改默认的6.x.x版本
<build> <plugins> <!-- 配置Tomcat插件 ,用于启动项目 --> <plugin> <groupId>org.ap ...
- Asp.NetCore Web开发之模型验证
在开发中,验证表单数据是很重要的一环,如果对用户输入的数据不加限制,那么当错误的数据提交到后台后,轻则破坏数据的有效性,重则会导致服务器瘫痪,这是很致命的. 所以进行数据有效性验证是必要的,我们一般通 ...
- UI设计师、平面设计师常用的网站大全,初学者必备,大家都在用!
UI设计师.平面设计师常用的网站大全,初学者必备,大家都在用! 国外的花瓣--Pinterest • The world's catalog of ideas 颜格视觉--app界面设计大全--电商. ...
- Java虚拟机栈和PC寄存器
PC Register介绍 JVM中的程序计数寄存器(Program Counter Register)中,Register 的命名源于CPU的寄存器,寄存器存储指令相关的现场信息.CPU只有把数据装 ...
- mysql整型后面的()宽度
int(5)这个5表示显示宽度 如果超出宽度则正常显示,所以人为指定显示宽度意义不大
- Docker——Registry搭建私有镜像仓库
前言 在 Docker 中,当我们执行 docker pull xxx 的时候,它实际上是从 registry.hub.docker.com 这个地址去查找,这就是Docker公司为我们提供的公共仓库 ...
- 【转载】CentOS 7 系统区域(语言)和键盘设置
CentOS 7 系统区域(语言)和键盘设置 即使是在window中,平常说的语言设置这一项也是归类为系统区域,CentOS可以通过修改/etc/locale.conf配置文件或使用localec ...
- 003.Ansible配置文件管理
一 配置文件的优先级 ansible的配置文件名为ansible.cfg,它一般会存在于四个地方: ANSIBLE_CONFIG:首先,Ansible命令会检查该环境变量,及这个环境变量将指向的配置文 ...
- 实例:使用playbook实现httpd安装、配置、以及虚拟主机的配置
一.安装环境配置 1.在控制节点给受控主机配置本地仓库文件 [root@ansible ~]# vim /etc/yum.repos.d/dvd.repo [AppStream] name=appst ...
- 华为鲲鹏处理器实现商用,Arm服务器又添砝码
华为鲲鹏处理器实现商用,Arm服务器又添砝码 鲲鹏920就是华为海思1620 鲲鹏920面向 服务器CPU就是 华为海思162064core 武汉华为PC不是海思1620是另一个cpu 深圳华为PC的 ...