python爬虫实例——基于python实现有道云翻译接口
# 分析包
# 分析post请求中参数
# 使用python模拟lts、sign、salt参数运算
# 执行结果
> > 1、按F12对网页进行分析,填写内容后自动翻译的功能一般是通过ajax实现的,所以可以有目的的对xhr包进行筛选,如果不知道这个点也可以一个个包进行查看分析,找包里面有需要翻译的内容和翻译结果
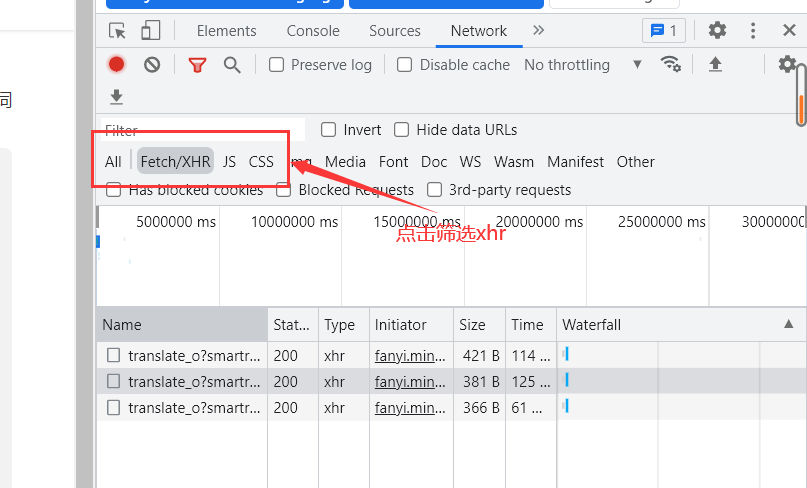
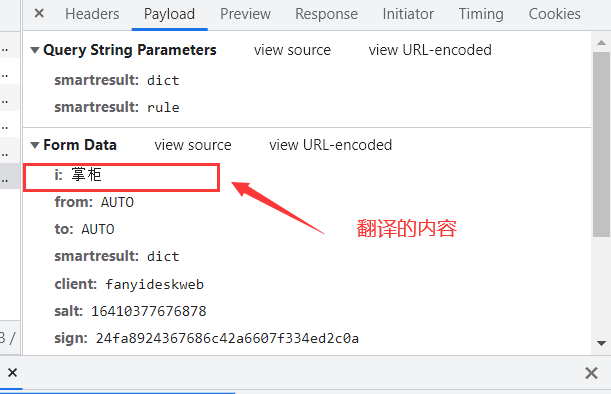
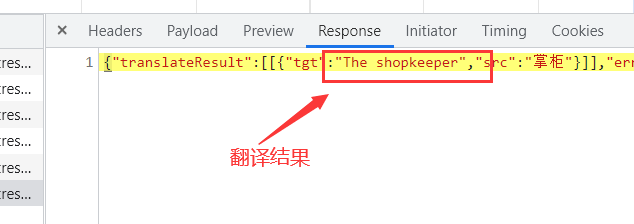
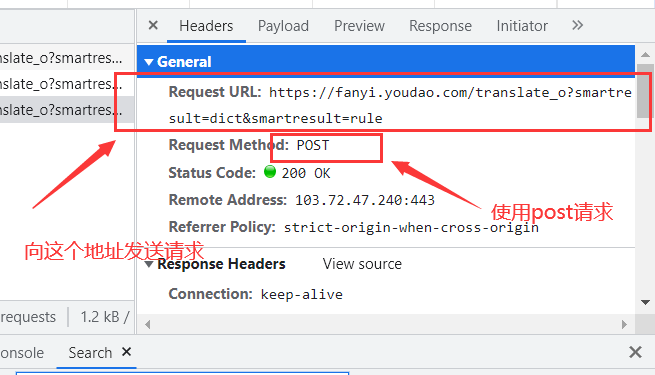
> > 2、分析发送请求中参数的参数,发送两次请求也就是翻译两次,对两次的包进行分析,可以发现每次发送的请求中salt、sign、lts的数据都不同,所以该网站可能是通过js对这些数据进行了处理
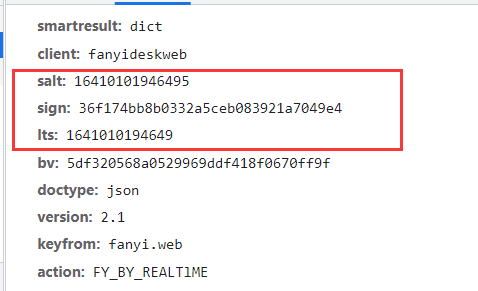
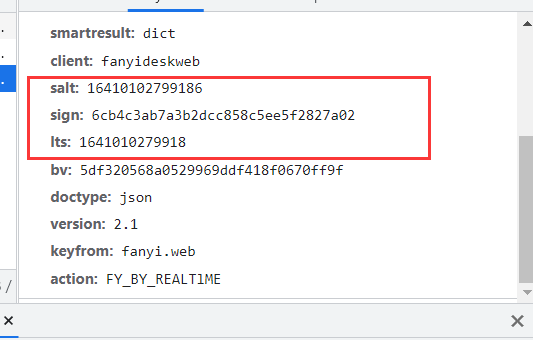
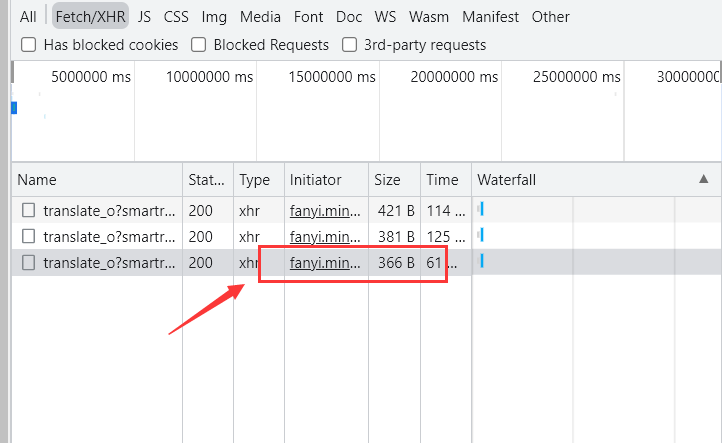
> > 3、寻找到这些参数运算的过程。点击Initiator(表示连接由谁发起),找到另一个包,在该包中分析salt、lts、sign运算过程
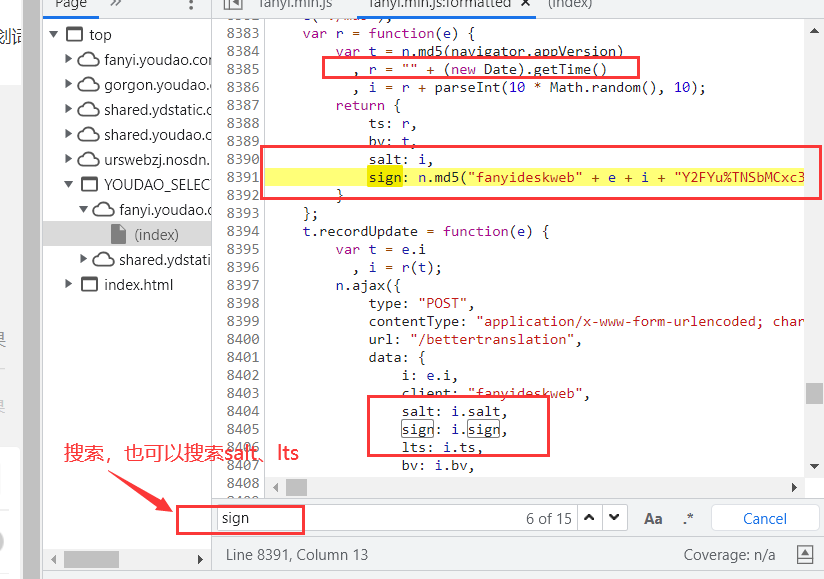
> 这里需要一些js知识,但一般学过其他语言也可以很清楚发现 lts是时间戳
> salt是在==时间戳后面==随机加上一个0-9的数字
> sign是对“fanyideskweb”+ e + i +"Y2FYu%TNSbMCxc3"进行==hash==运算,然后回看发送请求中sign的参数,发现他是16进制,所以最终结果我们也要以16进制展现
> e是我们输入的需要翻译的内容,i和salt相同 看不懂代码的话可以复制代码到console中看运算结果,例:
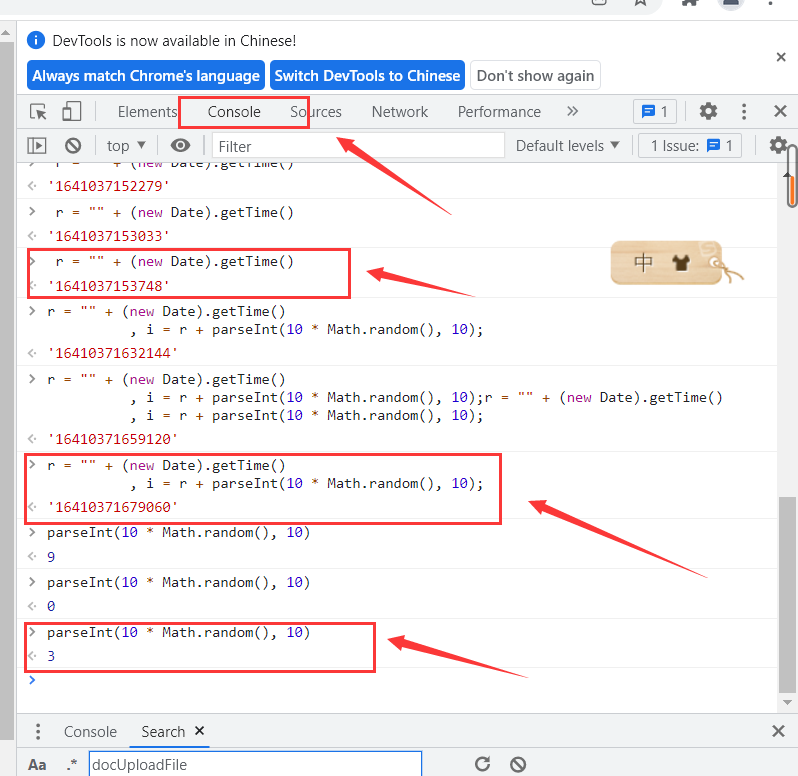
==e==可以通过设置断点来判断,断点设置好后,再翻译一次,然后把鼠标箭头放在e上,可以很明显的发现e的取值与我们输入的内容相同

到现在,我们把发送post请求需要的所有参数找到了,然后就是用python模拟这些参数的运算。
> > 4、模拟lts、salt、sign参数运算
模拟lts,lts是时间戳
使用time模块就行了
```python
lts = int(round(time.time()*1000))
```
模拟salt,salt是时间戳后面加上一个0-9的随机数
```python
salt = str(lts) + str(random.randint(0,9))
```
模拟sign,需要使用到hashlib库(自带的库不用安装)
```python
#创建hash对象
md5 = hashlib.md5()
#向hash对象中加入需要hash运算的字符串
n = 'fanyideskweb' + self.kw + salt + 'Y2FYu%TNSbMCxc3t2u^XT'
md5.update(n.encode())
#转换成16进制
sign = md5.hexdigest()
```
5、执行结果
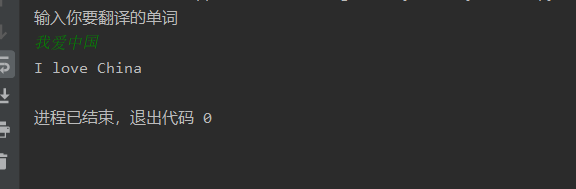
python爬虫实例——基于python实现有道云翻译接口的更多相关文章
- 有道云翻译接口 Show类
package com.yangchong.fanyi; import java.awt.EventQueue;import java.awt.Toolkit; import javax.swing. ...
- Python爬虫实例:爬取B站《工作细胞》短评——异步加载信息的爬取
很多网页的信息都是通过异步加载的,本文就举例讨论下此类网页的抓取. <工作细胞>最近比较火,bilibili 上目前的短评已经有17000多条. 先看分析下页面 右边 li 标签中的就是短 ...
- Python爬虫实例:爬取猫眼电影——破解字体反爬
字体反爬 字体反爬也就是自定义字体反爬,通过调用自定义的字体文件来渲染网页中的文字,而网页中的文字不再是文字,而是相应的字体编码,通过复制或者简单的采集是无法采集到编码后的文字内容的. 现在貌似不少网 ...
- Python爬虫实例:爬取豆瓣Top250
入门第一个爬虫一般都是爬这个,实在是太简单.用了 requests 和 bs4 库. 1.检查网页元素,提取所需要的信息并保存.这个用 bs4 就可以,前面的文章中已经有详细的用法阐述. 2.找到下一 ...
- python爬虫-基础入门-python爬虫突破封锁
python爬虫-基础入门-python爬虫突破封锁 >> 相关概念 >> request概念:是从客户端向服务器发出请求,包括用户提交的信息及客户端的一些信息.客户端可通过H ...
- Python 爬虫实例
下面是我写的一个简单爬虫实例 1.定义函数读取html网页的源代码 2.从源代码通过正则表达式挑选出自己需要获取的内容 3.序列中的htm依次写到d盘 #!/usr/bin/python import ...
- python爬虫实例大全
WechatSogou [1]- 微信公众号爬虫.基于搜狗微信搜索的微信公众号爬虫接口,可以扩展成基于搜狗搜索的爬虫,返回结果是列表,每一项均是公众号具体信息字典. DouBanSpider [2]- ...
- shell及Python爬虫实例展示
1.shell爬虫实例: [root@db01 ~]# vim pa.sh #!/bin/bash www_link=http://www.cnblogs.com/clsn/default.html? ...
- 又面试了Python爬虫工程师,碰到这么几道面试题,Python面试题No9
第1题:动态加载又对及时性要求很高怎么处理? 如何知道一个网站是动态加载的数据? 用火狐或者谷歌浏览器 打开你网页,右键查看页面源代码,ctrl +F 查询输入内容,源代码里面并没有这个值,说明是动态 ...
随机推荐
- 艺恩网内地总票房排名Top100信息及其豆瓣评分详情爬取
前两天用python2写的一个小爬虫 主要实现了从http://www.cbooo.cn/Alltimedomestic这么个网页中爬取每一部电影的票房信息等,以及在豆瓣上该电影的评分信息 代码如下 ...
- ganglia -api
setup 命令: virtualenv ve source ve/bin/activate pip install -r requirements.txt python ganglia/gangli ...
- Mysql B-Tree和B+Tree索引
Mysql B-Tree和B+树索引 Mysql加快数据查找使用B-Tree数据结构存储索引数据,InnoDB存储引擎实际使用B+Tree.下面首先介绍下B-Tree和B+Tree的区别: 一.B树和 ...
- Mysql从头部署多个版本
目录 一.环境准备 二.下载安装包 三.Mysql-5.6单独部署 四.Mysql-5.7单独部署 五.添加到多版本控制 六.muliti使用 一.环境准备 系统:centos7.3一台 软件版本:m ...
- Nginx 中 location 的匹配顺序
nginx中location的匹配模式有以下几种: 精确匹配:以=开头,只有完全匹配才能生效,例子location = /uri 非正则匹配:以^~开头,^表示非.~表示正则,例子location ^ ...
- Linux——配置主从数据库服务
主从数据库 Linux中,数据库服务有三种:互为主主,互为主从,一主一从(主从数据库) 互为主主:数据库时时更新 互为主从:数据库达到一定的的容量再更新 一主一从:在主数据库上面创建的,可以同步到从数 ...
- STL 较详尽总结
STL就是Standard Template Library,标准模板库.这可能是一个历史上最令人兴奋的工具的最无聊的术语.从根本上说,STL是一些"容器"的集合,这些" ...
- [BUUCTF]PWN2——rip
[BUUCTF]PWN2-rip 题目网址:https://buuoj.cn/challenges#rip 步骤: 例行检查附件,64位程序,没有开启任何保护 nc一下,看看输入点的提示字符串,让我们 ...
- 数据类型Table.TransformColumnTypes(Power Query 之 M 语言)
数据源: 任意数据源 目标: 设置适合的数据类型 操作过程: 选取指定列>[主页]>[数据类型]>选取 选取指定列>[转换]>[数据类型]>选取 选取指定列> ...
- 【C语言】Socket发送HTTP-TCP请求,数据有字符串插入
问题描述: 场景:编写Socket接口,向LOKI发送POST请求查询数据 BUG发现位置:通过cJSON读取时间戳,发现被截断. 现象:通过read()去读取返回的数据,数据行中被插入字符:如下 c ...