Python爬虫爬取网页图片
没想到python是如此强大,令人着迷,以前看见图片总是一张一张复制粘贴,现在好了,学会python就可以用程序将一张张图片,保存下来。
今天逛贴吧看见好多美图,可是图片有点多,不想一张一张地复制粘贴,怎么办呢?办法总是有的,即便没有我们也可以创造一个办法。

下面就看看我今天写的程序:
#coding=utf-8 #urllib模块提供了读取Web页面数据的接口
import urllib.request
#re模块主要包含了正则表达式
import re
#定义一个getHtml()函数
def getHtml(url):
page = urllib.request.urlopen(url) #urllib.request.urlopen()方法用于打开一个URL地址
html = page.read() #read()方法用于读取URL上的数据
return html def getImg(html):
reg = r'src="(.+?\.jpg)" pic_ext' #正则表达式,得到图片地址
imgre = re.compile(reg) #re.compile() 可以把正则表达式编译成一个正则表达式对象.
html = html.decode('utf-8') #python3
imglist = re.findall(imgre,html) #re.findall() 方法读取html 中包含 imgre(正则表达式)的数据
#把筛选的图片地址通过for循环遍历并保存到本地
#核心是urllib.request.urlretrieve()方法,直接将远程数据下载到本地,图片通过x依次递增命名
x = 0 for imgurl in imglist:
urllib.request.urlretrieve(imgurl,'D:\E\%s.jpg' % x)
x += 1 html = getHtml("https://tieba.baidu.com/p/xxxxxxxx")
print(getImg(html))
运行程序后,下面就是见证奇迹的时刻,打开对应文件夹:
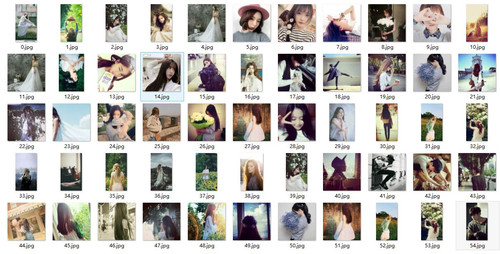
哇!图片全部保存了下来,so nice! :-)
2019年1月更新备注:
此前代码为2015年Python2.x环境测试,现在已将代码更新,测试环境为Python3.7 ,注意请在D盘新建一个文件夹重命名为E
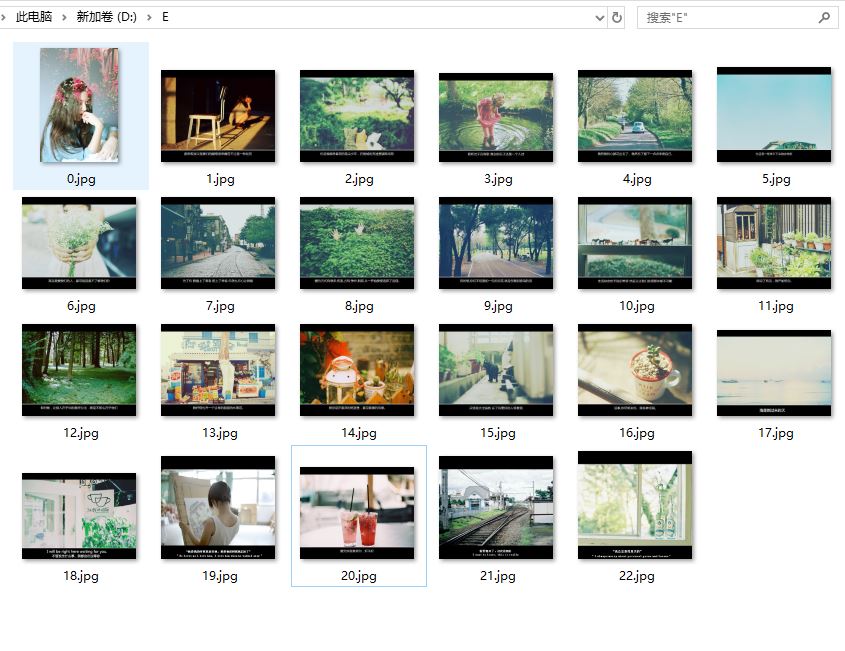
测试网址:https://tieba.baidu.com/p/2555125530
测试结果如图:
Python爬虫爬取网页图片的更多相关文章
- node:爬虫爬取网页图片
代码地址如下:http://www.demodashi.com/demo/13845.html 前言 周末自己在家闲着没事,刷着微信,玩着手机,发现自己的微信头像该换了,就去网上找了一下头像,看着图片 ...
- python爬虫-爬取百度图片
python爬虫-爬取百度图片(转) #!/usr/bin/python# coding=utf-8# 作者 :Y0010026# 创建时间 :2018/12/16 16:16# 文件 :spider ...
- erlang 爬虫——爬取网页图片
说起爬虫,大家第一印象就是想到了python来做爬虫.其实,服务端语言好些都可以来实现这个东东. 在我们日常上网浏览网页的时候,经常会看到一些好看的图片,我们就希望把这些图片保存下载,或者用户用来做桌 ...
- Python多线程爬虫爬取网页图片
临近期末考试,但是根本不想复习!啊啊啊啊啊啊啊!!!! 于是做了一个爬虫,网址为 https://yande.re,网页图片为动漫美图(图片带点颜色........宅男福利 github项目地址为:h ...
- python爬虫——爬取网页数据和解析数据
1.网络爬虫的基本概念 网络爬虫(又称网络蜘蛛,机器人),就是模拟客户端发送网络请求,接收请求响应,一种按照一定的规则,自动地抓取互联网信息的程序.只要浏览器能够做的事情,原则上,爬虫都能够做到. 2 ...
- 1.记我的第一次python爬虫爬取网页视频
It is my first time to public some notes on this platform, and I just want to improve myself by reco ...
- Python:爬取网站图片并保存至本地
Python:爬取网页图片并保存至本地 python3爬取网页中的图片到本地的过程如下: 1.爬取网页 2.获取图片地址 3.爬取图片内容并保存到本地 实例:爬取百度贴吧首页图片. 代码如下: imp ...
- 使用Python爬虫爬取网络美女图片
代码地址如下:http://www.demodashi.com/demo/13500.html 准备工作 安装python3.6 略 安装requests库(用于请求静态页面) pip install ...
- java爬虫-简单爬取网页图片
刚刚接触到“爬虫”这个词的时候是在大一,那时候什么都不明白,但知道了百度.谷歌他们的搜索引擎就是个爬虫. 现在大二.再次燃起对爬虫的热爱,查阅资料,知道常用java.python语言编程,这次我选择了 ...
随机推荐
- V8引擎的垃圾回收策略
V8 的垃圾回收策略主要基于分代式垃圾回收机制.所谓分代式,就是将内存空间分为新生代和老生代两种,然后采用不同的回收算法进行回收. 新生代空间 新生代空间中的对象为存活时间较短的对象,大多数的对象被分 ...
- Open ID Connect(OIDC)在 ASP.NET Core中的应用
我们在<ASP.NET Core项目实战的课程>第一章里面给identity server4做了一个全面的介绍和示例的练习 ,这篇文章是根据大家对OIDC遇到的一些常见问题整理得出. 本文 ...
- Vue(day5)
一.监听数据变化的三种形式 假设我们需要提供两个输入框,分别输入姓和名,然后自动拼接为姓名.这样,我们就需要监听输入框的数据变化,让完整的姓名跟随输入的变动而变化.我们可以使用以下三种方式: 1.结合 ...
- 为什么要重写 hashcode 和 equals 方法?
引言 以前面试的时候被面试官问到过这样一个问题: 你有没有重写过 hashCode 方法? 心里想着我没事重写哪玩意干啥,能不写就不写.嘴上当然没敢这么说,只能略表遗憾的说抱歉,我没写过. 撇了面试官 ...
- 如何在ASP.NET Core程序启动时运行异步任务(1)
原文:Running async tasks on app startup in ASP.NET Core (Part 1) 作者:Andrew Lock 译者:Lamond Lu 背景 当我们做项目 ...
- DotNetCore跨平台~EFCore2.0连接Mysql的烦恼-已解决
回到目录 对于传统的nuget包,我们习惯上用官方或者大型组织的,因为它们比较考靠谱,但就在前两天.net core2.0发布后,我把efcore也升级到2.0了,mysql.EfCore也升级到支持 ...
- LindDotNetCore~docker里图像上生成中文乱码问题
回到目录 因为docker上的大部分镜像都是基于linux系统的,所以在向图像中写中文时需要考虑中文字体问题,例如在microsoft/aspnetcore2.0这个镜像,它是基于debian系统的, ...
- JSP 内置对象(上)
JSP 内置对象是 Web 容器创建的一组对象,不使用 new 关键字就可以直接使用的对象.如上一章中使用脚本实现打印九九乘法表中的out对象 <%-- 脚本:out对象是JSPWriter类的 ...
- Asp.Net.Identity认证不依赖Entity Framework实现方式
Asp.Net.Identity为何物请自行搜索,也可转向此文章http://www.cnblogs.com/shanyou/p/3918178.html 本来微软已经帮我们将授权.认证以及数据库存储 ...
- 在React中使用Typescript的实践问题总结
1.布尔值的大小写问题: 声明变量类型的时候,使用小写boolean 2. 对于从父组件传递过来的函数,子组件在模版中调用时,如果采用原来的写法,会报错: 改变写法后是如下这样,如果有参数和函数返回值 ...