极大既然估计和高斯分布推导最小二乘、LASSO、Ridge回归
最小二乘法可以从Cost/Loss function角度去想,这是统计(机器)学习里面一个重要概念,一般建立模型就是让loss function最小,而最小二乘法可以认为是 loss function = (y_hat -y )^2的一个特例,类似的像各位说的还可以用各种距离度量来作为loss function而不仅仅是欧氏距离。所以loss function可以说是一种更一般化的说法。
最大似然估计是从概率角度来想这个问题,直观理解,似然函数在给定参数的条件下就是观测到一组数据realization的概率(或者概率密度)。最大似然函数的思想就是什么样的参数才能使我们观测到目前这组数据的概率是最大的。
类似的从概率角度想的估计量还有矩估计(moment estimation)。就是通过一阶矩 二阶矩等列方程,来反解出参数。
有人提到了正态分布。最大似然估计和最小二乘法还有一大区别就是,最大似然估计是需要有分布假设的,属于参数统计,如果连分布函数都不知道,又怎么能列出似然函数呢? 而最小二乘法则没有这个假设。 二者的相同之处是都把估计问题变成了最优化问题。但是最小二乘法是一个凸优化问题,最大似然估计不一定是。
注:
从优化的角度上来讲,负的log likelihood 就是求MLE(最大似然估计)要优化的目标函数。
那么为啥MLE需要设置分布这么麻烦,还有这么多应用,因为当likelihood设置正确的时候,这个目标函数给出的解最efficient。
那么为啥有这么多人把MLE和LOSE搞混,因为当likelihood用的是gaussian的时候,由于gaussian kernel里有个类似于Euclidean distance的东西,一求log就变成square loss了,导致解和OLSE是一样的。而碰巧刚接触MLE的时候基本都是gaussian假设,这才导致很多人分不清楚。
从概率论的角度:
Least Square 的解析解可以用 Gaussian 分布以及最大似然估计求得
Ridge 回归可以用 Gaussian 分布和最大后验估计解释
LASSO 回归可以用 Laplace 分布和最大后验估计解释
-------------------------------------------------------------------
下面是上述三种的推导
注意:
首先知道什么是:高斯分布、拉普拉斯分布、最大似然估计,最大后验估计(MAP)。
按照李航博士的观点,机器学习三要素为:模型、策略、算法。
一种模型可以有多种求解策略,每一种求解策略可能最终又有多种计算方法。
以下只推导模型策略,不讲算法。


区别:
最大似然估计不考虑先验后验的问题,纯粹是选择一个参数能最大化模型似然度
最大后验概率是贝叶斯方法,引入参数的先验概率,结合似然度选择最佳参数或模型

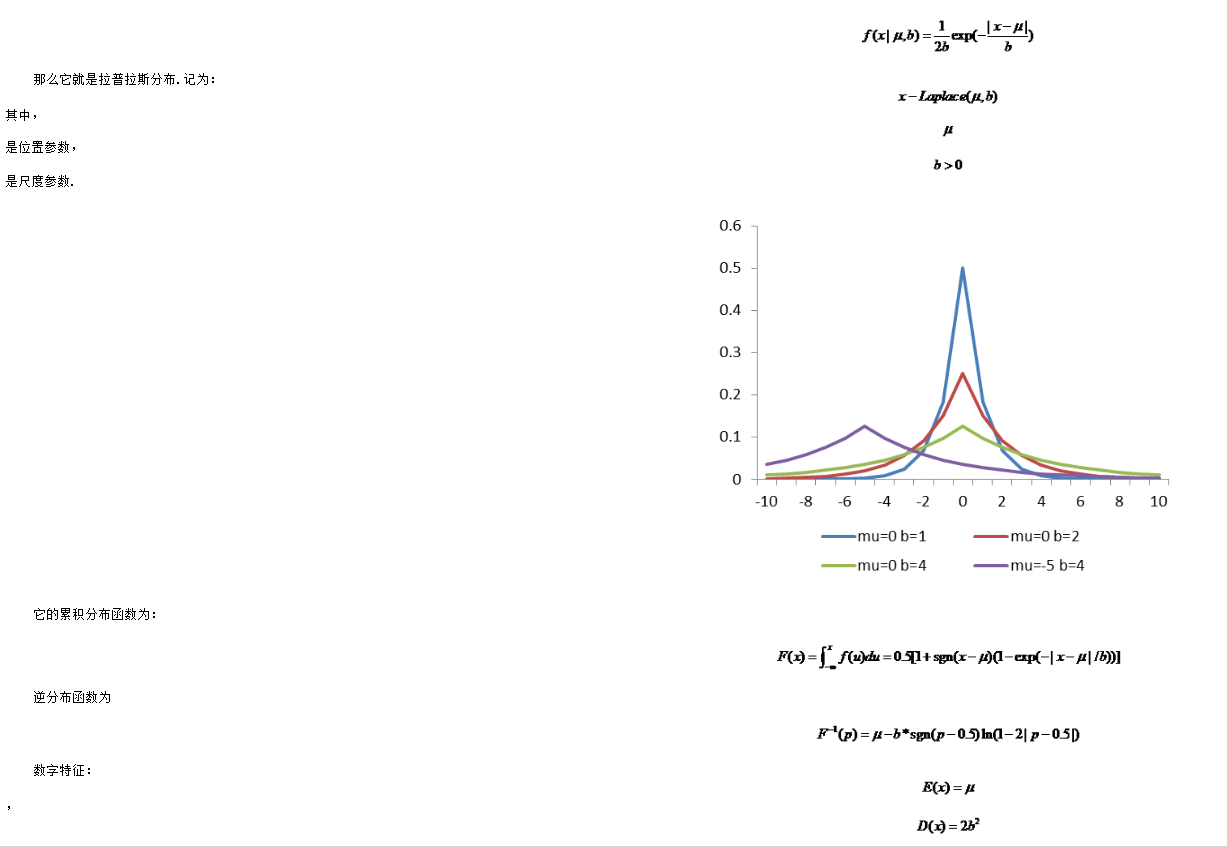
拉普拉斯分布
- 在概率论与统计学中,拉普拉斯分布是以皮埃尔-西蒙·拉普拉斯的名字命名的一种连续概率分布.由于它可以看作是两个不同位置的指数分布背靠背拼接在一起,所以它也叫作双指数分布.两个相互独立同概率分布指数随机变量之间的差别是按照指数分布的随机时间布朗运动,所以它遵循拉普拉斯分布.
如果随机变量的概率密度函数为
极大既然估计和高斯分布推导最小二乘、LASSO、Ridge回归的更多相关文章
- [白话解析] 深入浅出 极大似然估计 & 极大后验概率估计
[白话解析] 深入浅出极大似然估计 & 极大后验概率估计 0x00 摘要 本文在少用数学公式的情况下,尽量仅依靠感性直觉的思考来讲解 极大似然估计 & 极大后验概率估计,并且从名著中找 ...
- 【ML数学知识】极大似然估计
它是建立在极大似然原理的基础上的一个统计方法,极大似然原理的直观想法是,一个随机试验如有若干个可能的结果A,B,C,... ,若在一次试验中,结果A出现了,那么可以认为实验条件对A的出现有利,也即出现 ...
- B-概率论-极大似然估计
[TOC] 更新.更全的<机器学习>的更新网站,更有python.go.数据结构与算法.爬虫.人工智能教学等着你:https://www.cnblogs.com/nickchen121/ ...
- LR为什么用极大似然估计,损失函数为什么是log损失函数(交叉熵)
首先,逻辑回归是一个概率模型,不管x取什么值,最后模型的输出也是固定在(0,1)之间,这样就可以代表x取某个值时y是1的概率 这里边的参数就是θ,我们估计参数的时候常用的就是极大似然估计,为什么呢?可 ...
- 数值分析:最小二乘与岭回归(Pytorch实现)
Chapter 4 1. 最小二乘和正规方程 1.1 最小二乘的两种视角 从数值计算视角看最小二乘法 我们在学习数值线性代数时,学习了当方程的解存在时,如何找到\(\textbf{A}\bm{x}=\ ...
- L1,L2范数和正则化 到lasso ridge regression
一.范数 L1.L2这种在机器学习方面叫做正则化,统计学领域的人喊她惩罚项,数学界会喊她范数. L0范数 表示向量xx中非零元素的个数. L1范数 表示向量中非零元素的绝对值之和. L2范数 表 ...
- 【机器学习】Linear least squares, Lasso,ridge regression有何本质区别?
Linear least squares, Lasso,ridge regression有何本质区别? Linear least squares, Lasso,ridge regression有何本质 ...
- 《机器学习_01_线性模型_线性回归_正则化(Lasso,Ridge,ElasticNet)》
一.过拟合 建模的目的是让模型学习到数据的一般性规律,但有时候可能会学过头,学到一些噪声数据的特性,虽然模型可以在训练集上取得好的表现,但在测试集上结果往往会变差,这时称模型陷入了过拟合,接下来造一些 ...
- 极大似然估计MLE 极大后验概率估计MAP
https://www.cnblogs.com/sylvanas2012/p/5058065.html 写的贼好 http://www.cnblogs.com/washa/p/3222109.html ...
随机推荐
- [OpenCV] Samples 06: logistic regression
logistic regression,这个算法只能解决简单的线性二分类,在众多的机器学习分类算法中并不出众,但它能被改进为多分类,并换了另外一个名字softmax, 这可是深度学习中响当当的分类算法 ...
- C# FileSystemWatcher 在监控文件夹和文件时的用法
概述 最近学习FileSystemWatcher的用法,它主要是监控一个文件夹,当文件夹内的文件要是有更改就要记录下来,我就整理下我对FileSystemWatcher 的理解和用法. FileSys ...
- TCP拥塞控制算法纵横谈-Illinois和YeAH
周五晚上.终于下了雨.所以也终于能够乱七八糟多写点松散的东西了... 方法论问题. 这个题目太大以至于内容和题目的关联看起来有失偏颇.只是也无所谓,既然被人以为"没有方法论"而歧视 ...
- pip更换下载源(提升下载速度)
经常在使用Python的时候需要安装各种模块,而pip是很强大的模块安装工具,但是由于国外官方pypi经常被墙,导致不可用,或者下载速度很慢,所以我们最好是将自己使用的pip源更换一下,这样就能解决被 ...
- 【ArcGIS】WebAdaptorIIS 安装前准备及配置Portal For ArcGIS的问题解决
1.计算机全名配置 2.IIS-服务器证书配置 3.端口绑定 备注:配置Portal For ArcGIS总会提示计算机域名.全名错误.完全限定域名,可能就是没有进行第一步操作 4.Portal目录
- IIS日志清理(VBS版,JS版)
IIS默认日志记录在C:\WINDOWS\system32\LogFiles,时间一长,特别是子站点多的服务器,一个稍微有流量的网站,其日志每天可以达到上百兆,这些文件日积月累会严重的占用服务器磁盘空 ...
- iOS开发--打印NSRange,CGRect等结构体
使用对应的转换NSStringFromCGPoint NSStringFromCGSize NSStringFromCGRect NSStringFromCGAffineTransform ...
- java.lang.NumberFormatException: For input string: "${jdbc.maxActive}"
一.问题 使用SpringMVC和MyBatis整合,将jdbc配置隔离出来的时候出现下面的错误,百度了很久没有找到解决方法,回家谷歌下,就找到解决方法了,不得不说谷歌就是强大,不废话,下面是具体的错 ...
- MVC的初步认识理论
说起来写博客可以说一个月没来啦,我们狠狠的放假一个月,想一想都奇怪.而是想一下以后的假期还会这样吗?或许这是作为学生的我们的最后一个长的假期啦,以后就要面对工作再也没有寒假暑假之分啦,在这一个月的时间 ...
- 转:ANDROID音频系统散记之四:4.0音频系统HAL初探
昨天(2011-11-15)发布了Android4.0的源码,今天download下来,开始挺进4.0时代.简单看了一下,发现音频系统方面与2.3的有较多地方不同,下面逐一描述. 一.代码模块位置 1 ...