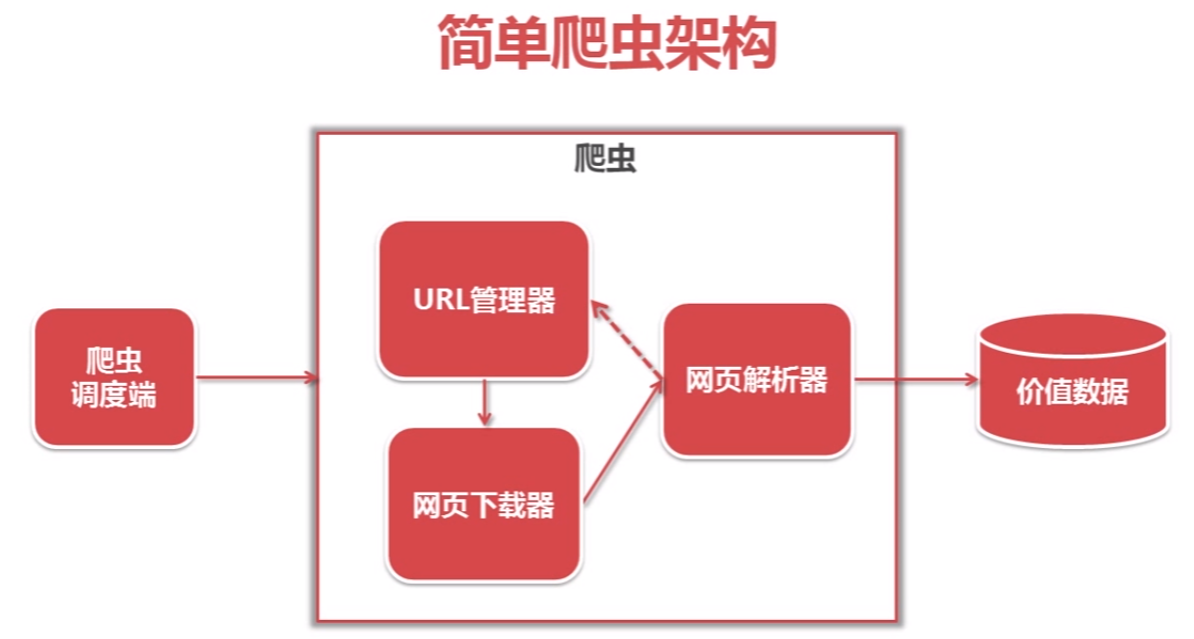
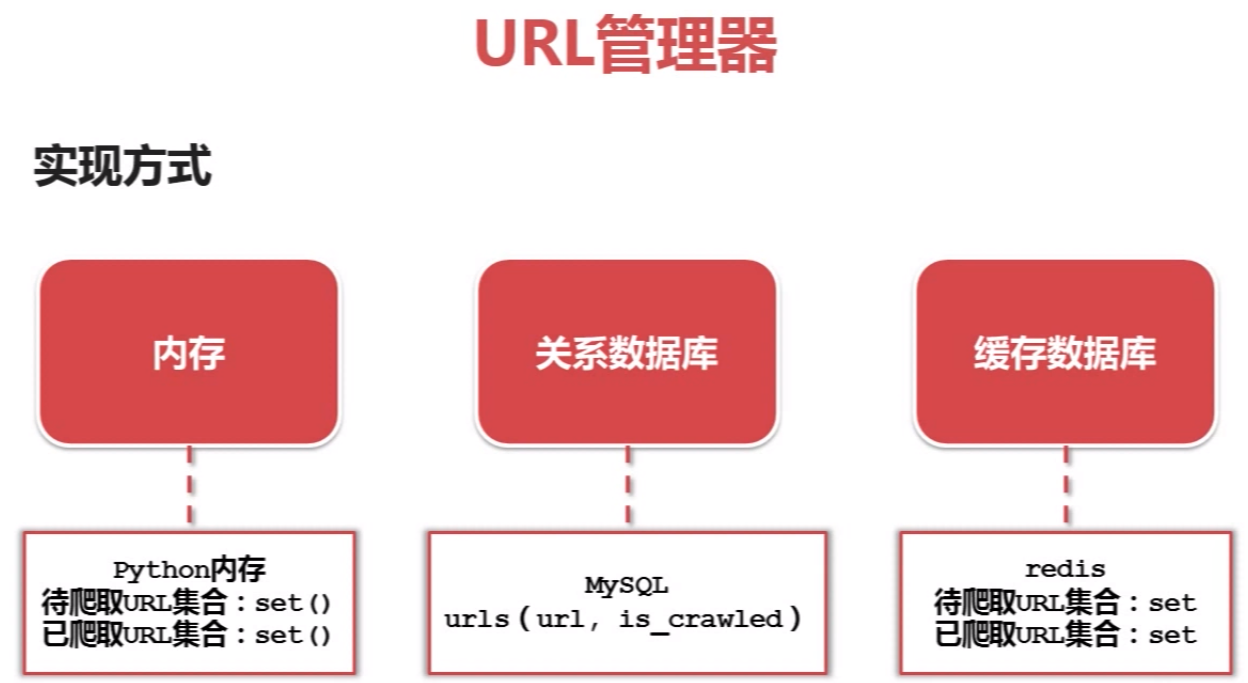
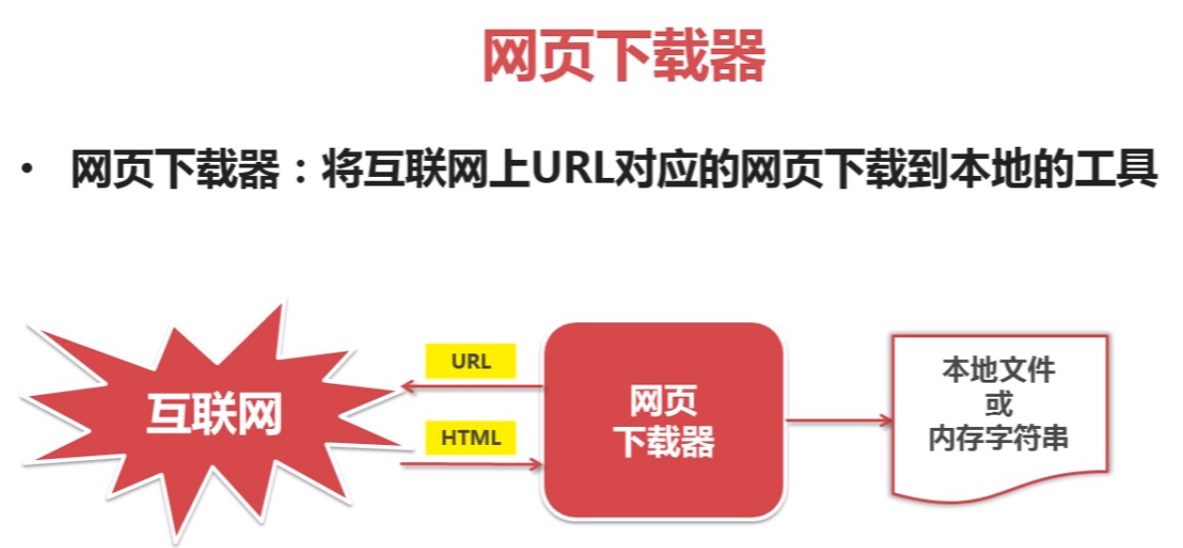
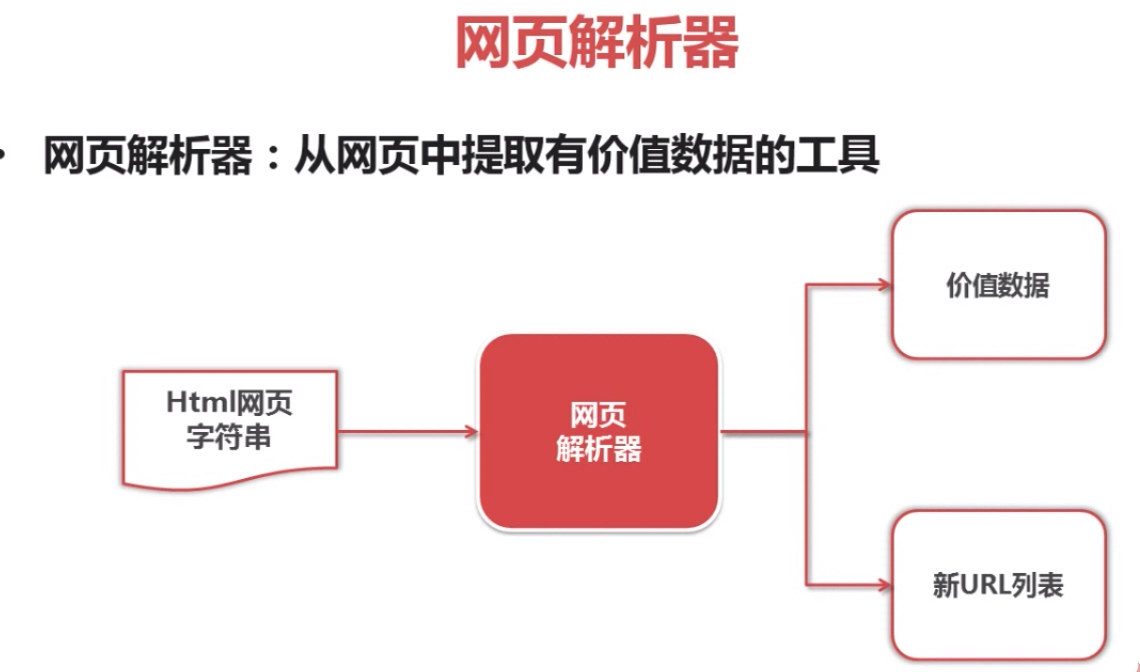
python爬虫简单架构原理及示例



网页下载器示例:
# coding:utf-8
import urllib2
import cookielib
url = "http://www.baidu.com" print u"第一种方法"
# pip install urllib2
response1 = urllib2.urlopen(url)
print response1.getcode()
print len(response1.read()) print u"第二种方法"
request = urllib2.Request(url)
# 把爬虫伪装成浏览器
request.add_header("user-agent", "Mozilla/5.0")
response2 = urllib2.urlopen(request)
print response2.getcode()
print len(response2.read()) print u"第三种方法"
# pip install cookielib
cj = cookielib.CookieJar()
opener = urllib2.build_opener(urllib2.HTTPCookieProcessor(cj))
urllib2.install_opener(opener)
response3 = urllib2.urlopen(request)
print response3.getcode()
print cj
print len(response3.read())
# 运行结果


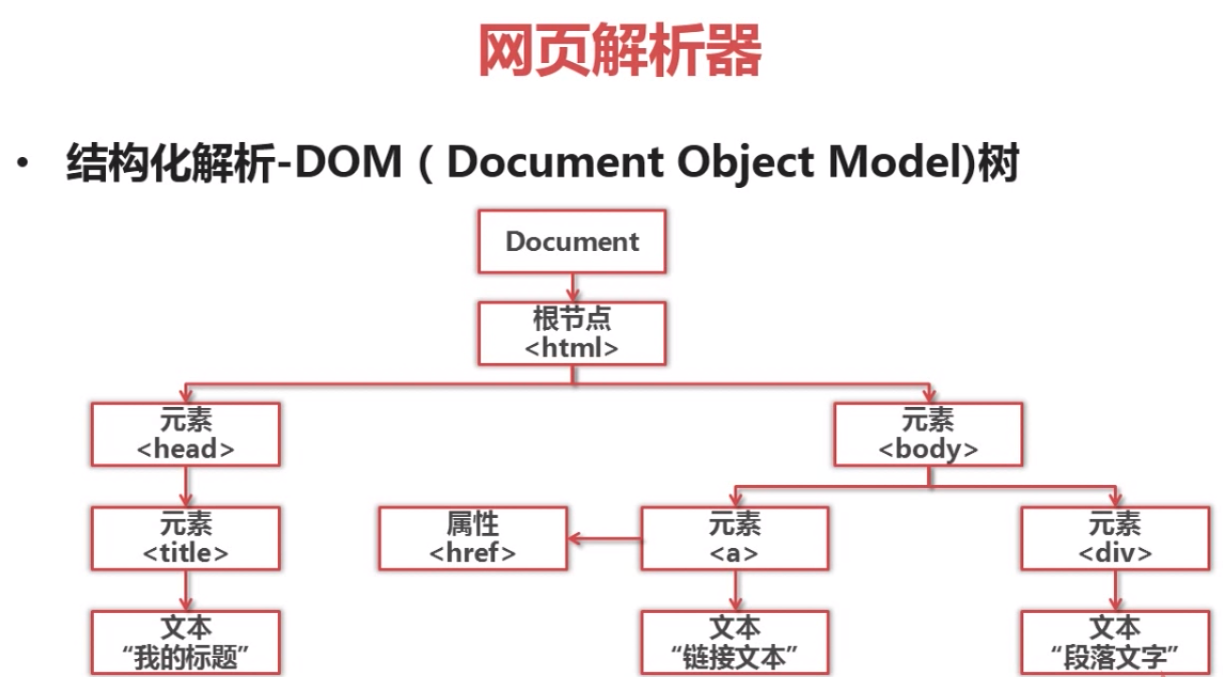
beautifulsoap使用示例
#coding:utf-8 # 安装beautifulsoap4 D:\Python27\Lib>pip install beautifulsoup4 from bs4 import BeautifulSoup
import re html_doc = """
<html><head><title>The Dormouse's story</title></head>
<body>
<p class="title"><b>The Dormouse's story</b></p> <p class="story">Once upon a time there were three little sisters; and their names were
<a href="http://example.com/elsie" class="sister" id="link1">Elsie</a>,
<a href="http://example.com/lacie" class="sister" id="link2">Lacie</a> and
<a href="http://example.com/tillie" class="sister" id="link3">Tillie</a>;
and they lived at the bottom of a well.</p> <p class="story">...</p>
""" soup = BeautifulSoup(html_doc, 'html.parser', from_encoding='utf-8') print u'获取所有的链接'
links = soup.find_all('a') for link in links:
print link.name,link['href'], link.get_text() print u'获取lacie的链接'
link_node = soup.find('a', href='http://example.com/lacie')
print link_node.name, link_node['href'],link_node.get_text() print u'正则匹配'
link_node = soup.find('a', href=re.compile(r"ill"))
print link_node.name, link_node['href'],link_node.get_text() print u'获取p段落名字'
link_node = soup.find('p', class_="title")
print link_node.name, link_node.get_text()
python爬虫简单架构原理及示例的更多相关文章
- Python爬虫简单实现CSDN博客文章标题列表
Python爬虫简单实现CSDN博客文章标题列表 操作步骤: 分析接口,怎么获取数据? 模拟接口,尝试提取数据 封装接口函数,实现函数调用. 1.分析接口 打开Chrome浏览器,开启开发者工具(F1 ...
- Python爬虫简单入门及小技巧
刚刚申请博客,内心激动万分.于是为了扩充一下分类,随便一个随笔,也为了怕忘记新学的东西由于博主十分怠惰,所以本文并不包含安装python(以及各种模块)和python语法. 目标 前几天上B站时看到一 ...
- [python爬虫]简单爬虫功能
在我们日常上网浏览网页的时候,经常会看到某个网站中一些好看的图片,它们可能存在在很多页面当中,我们就希望把这些图片保存下载,或者用户用来做桌面壁纸,或者用来做设计的素材. 我们最常规的做法就是通过鼠标 ...
- Python爬虫--简单爬取图片
今天晚上弄了一个简单的爬虫,可以爬取网页的图片,现在现在做一下准备工作. 需要的库:urllib 和 re urllib库可以理解为是一个url下载器,其中有三个重要的方法 urllib.urlope ...
- python爬虫简单的添加代理进行访问
在使用python对网页进行多次快速爬取的时候,访问次数过于频繁,服务器不会考虑User-Agent的信息,会直接把你视为爬虫,从而过滤掉,拒绝你的访问,在这种时候就需要设置代理,我们可以给proxi ...
- Python爬虫简单介绍
相关环境: Python3 requests库 BeautifulSoup库 一.requests库简单使用 简单获取一个网页的源代码: import requests sessions = requ ...
- Python爬虫简单实现之Q乐园图片下载
根据需求写代码实现.然而跟我并没有什么关系,我只是打开电脑望着屏幕想着去干点什么,于是有了这个所谓的“需求”. 终于,我发现了Q乐园——到底是我老了还是我小了,这是什么神奇的网站,没听过啊,就是下面酱 ...
- 用python爬虫简单爬取 笔趣网:类“起点网”的小说
首先:文章用到的解析库介绍 BeautifulSoup: Beautiful Soup提供一些简单的.python式的函数用来处理导航.搜索.修改分析树等功能. 它是一个工具箱,通过解析文档为用户提供 ...
- Python爬虫--简单的单词查询
Refer to: https://github.com/gaopu/Python/blob/master/Dict.py 本程序参考自上面Github连接 该程序功能是输入一个单词可以给出这个单词的 ...
随机推荐
- 【2000*】【Codeforces Round #518 (Div. 1) [Thanks, Mail.Ru!] B】Multihedgehog
[链接] 我是链接,点我呀:) [题意] [题解] 找到度数为1的点. 他们显然是叶子节点. 然后每个叶子节点. 往上进行bfs. 累计他们的父亲节点的儿子的个数. 如果都满足要求那么就继续往上走. ...
- 洛谷 P2813 母舰
题目描述 在小A的星际大战游戏中,一艘强力的母舰往往决定了一场战争的胜负.一艘母舰的攻击力是普通的MA(Mobile Armor)无法比较的. 对于一艘母舰而言,它是由若干个攻击系统和若干个防御系统组 ...
- poj 2942 求点双联通+二分图判断奇偶环+交叉染色法判断二分图
http://blog.csdn.net/lyy289065406/article/details/6756821 http://www.cnblogs.com/wuyiqi/archive/2011 ...
- 0719show engine innodb status解读
转自 http://www.cnblogs.com/zengkefu/p/5678100.html 注:以下内容为根据<高性能mysql第三版>和<mysql技术内幕innodb存储 ...
- LINUX内核内存屏障
================= LINUX内核内存屏障 ================= By ...
- android中常见的内存泄漏和解决的方法
android中的内存溢出预计大多数人在写代码的时候都出现过,事实上突然认为工作一年和工作三年的差别是什么呢.事实上干的工作或许都一样,产品汪看到的结果也都一样,那差别就是速度和质量了. 写在前面的一 ...
- 自己写的php curl库实现整站克隆
有时候常常会用到一些在线手冊,比方国内或国外的.有些是訪问速度慢,有些是作者直接吧站点关闭了,有些是server总是宕机.所以还是全盘克隆到自己server比較爽.所 已这里给了一个demo < ...
- js限制checkbox选中个数
今天在做项目时,碰到一个问题,我须要展示多个checkbox复选框,而仅仅能同意最多选6个.调试了老半天.最终出来了,代码例如以下: <SCRIPT LANGUAGE="JavaScr ...
- maven环境配置好,一直提示mvn不是内部命令
设置了环境变量 M2_HOME 跟path ,在cmd中输入mvn一直提示不是内部命令 解决办法:通过命令设置path 如下:set path=输入值
- get post 的区别
比较 GET 与 POST 还有一个问题就是:form 表单的get post 的默认传输量是多少? 期待评论区来解答!!! 一个获取数据,一个修改数据. 下面的表格比较了两种 HTTP 方法:GET ...