Python之爬虫(十四) Scrapy框架的架构和原理
这一篇文章主要是为了对scrapy框架的工作流程以及各个组件功能的介绍
Scrapy目前已经可以很好的在python3上运行
Scrapy使用了Twisted作为框架,Twisted有些特殊的地方是它是事件驱动的,并且比较适合异步的代码。对于会阻塞线程的操作包含访问文件、数据库或者Web、产生新的进程并需要处理新进程的输出(如运行shell命令)、执行系统层次操作的代码(如等待系统队列),Twisted提供了允许执行上面的操作但不会阻塞代码执行的方法。
Scrapy data flow(流程图)
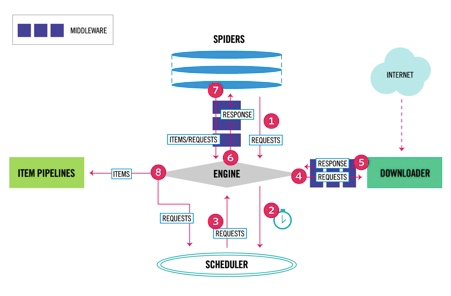
Scrapy数据流是由执行的核心引擎(engine)控制,流程是这样的:
1、爬虫引擎ENGINE获得初始请求开始抓取。
2、爬虫引擎ENGINE开始请求调度程序SCHEDULER,并准备对下一次的请求进行抓取。
3、爬虫调度器返回下一个请求给爬虫引擎。
4、引擎请求发送到下载器DOWNLOADER,通过下载中间件下载网络数据。
5、一旦下载器完成页面下载,将下载结果返回给爬虫引擎ENGINE。
6、爬虫引擎ENGINE将下载器DOWNLOADER的响应通过中间件MIDDLEWARES返回给爬虫SPIDERS进行处理。
7、爬虫SPIDERS处理响应,并通过中间件MIDDLEWARES返回处理后的items,以及新的请求给引擎。
8、引擎发送处理后的items到项目管道,然后把处理结果返回给调度器SCHEDULER,调度器计划处理下一个请求抓取。
9、重复该过程(继续步骤1),直到爬取完所有的url请求。
各个组件介绍
爬虫引擎(ENGINE)
爬虫引擎负责控制各个组件之间的数据流,当某些操作触发事件后都是通过engine来处理。
调度器(SCHEDULER)
调度接收来engine的请求并将请求放入队列中,并通过事件返回给engine。
下载器(DOWNLOADER)
通过engine请求下载网络数据并将结果响应给engine。
Spider
Spider发出请求,并处理engine返回给它下载器响应数据,以items和规则内的数据请求(urls)返回给engine。
管道项目(item pipeline)
负责处理engine返回spider解析后的数据,并且将数据持久化,例如将数据存入数据库或者文件。
下载中间件
下载中间件是engine和下载器交互组件,以钩子(插件)的形式存在,可以代替接收请求、处理数据的下载以及将结果响应给engine。
spider中间件
spider中间件是engine和spider之间的交互组件,以钩子(插件)的形式存在,可以代替处理response以及返回给engine items及新的请求集。
如何创建Scrapy项目
创建Scrapy项目
创建scrapy项目的命令是scrapy startproject 项目名,创建一个爬虫
进入到项目目录scrapy genspider 爬虫名字 爬虫的域名,例子如下:
zhaofandeMBP:python_project zhaofan$ scrapy startproject test1
New Scrapy project 'test1', using template directory '/Library/Frameworks/Python.framework/Versions/3.5/lib/python3.5/site-packages/scrapy/templates/project', created in:
/Users/zhaofan/Documents/python_project/test1 You can start your first spider with:
cd test1
scrapy genspider example example.com
zhaofandeMBP:python_project zhaofan$
zhaofandeMBP:test1 zhaofan$ scrapy genspider shSpider hshfy.sh.cn
Created spider 'shSpider' using template 'basic' in module:
test1.spiders.shSpider
scrapy项目结构
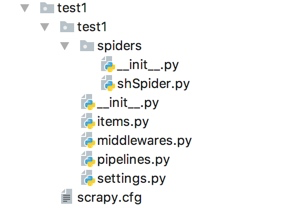
items.py 负责数据模型的建立,类似于实体类。
middlewares.py 自己定义的中间件。
pipelines.py 负责对spider返回数据的处理。
settings.py 负责对整个爬虫的配置。
spiders目录 负责存放继承自scrapy的爬虫类。
scrapy.cfg scrapy基础配置
Python之爬虫(十四) Scrapy框架的架构和原理的更多相关文章
- Python爬虫从入门到放弃(十二)之 Scrapy框架的架构和原理
这一篇文章主要是为了对scrapy框架的工作流程以及各个组件功能的介绍 Scrapy目前已经可以很好的在python3上运行Scrapy使用了Twisted作为框架,Twisted有些特殊的地方是它是 ...
- Python爬虫知识点四--scrapy框架
一.scrapy结构数据 解释: 1.名词解析: o 引擎(Scrapy Engine)o 调度器(Scheduler)o 下载器(Downloader)o 蜘蛛(Spiders)o 项目管 ...
- PYTHON网络爬虫与信息提取[scrapy框架应用](单元十、十一)
scrapy 常用命令 startproject 创建一个新的工程 scrapy startproject <name>[dir] genspider 创建一个爬虫 ...
- 第三百六十四节,Python分布式爬虫打造搜索引擎Scrapy精讲—elasticsearch(搜索引擎)的mapping映射管理
第三百六十四节,Python分布式爬虫打造搜索引擎Scrapy精讲—elasticsearch(搜索引擎)的mapping映射管理 1.映射(mapping)介绍 映射:创建索引的时候,可以预先定义字 ...
- 第三百五十四节,Python分布式爬虫打造搜索引擎Scrapy精讲—数据收集(Stats Collection)
第三百五十四节,Python分布式爬虫打造搜索引擎Scrapy精讲—数据收集(Stats Collection) Scrapy提供了方便的收集数据的机制.数据以key/value方式存储,值大多是计数 ...
- 第三百四十四节,Python分布式爬虫打造搜索引擎Scrapy精讲—craw母版l创建自动爬虫文件—以及 scrapy item loader机制
第三百四十四节,Python分布式爬虫打造搜索引擎Scrapy精讲—craw母版l创建自动爬虫文件—以及 scrapy item loader机制 用命令创建自动爬虫文件 创建爬虫文件是根据scrap ...
- 第三百三十四节,web爬虫讲解2—Scrapy框架爬虫—Scrapy爬取百度新闻,爬取Ajax动态生成的信息
第三百三十四节,web爬虫讲解2—Scrapy框架爬虫—Scrapy爬取百度新闻,爬取Ajax动态生成的信息 crapy爬取百度新闻,爬取Ajax动态生成的信息,抓取百度新闻首页的新闻rul地址 有多 ...
- 第三百六十八节,Python分布式爬虫打造搜索引擎Scrapy精讲—elasticsearch(搜索引擎)用Django实现搜索的自动补全功能
第三百六十八节,Python分布式爬虫打造搜索引擎Scrapy精讲—用Django实现搜索的自动补全功能 elasticsearch(搜索引擎)提供了自动补全接口 官方说明:https://www.e ...
- 第三百七十节,Python分布式爬虫打造搜索引擎Scrapy精讲—elasticsearch(搜索引擎)用Django实现搜索结果分页
第三百七十节,Python分布式爬虫打造搜索引擎Scrapy精讲—elasticsearch(搜索引擎)用Django实现搜索结果分页 逻辑处理函数 计算搜索耗时 在开始搜索前:start_time ...
随机推荐
- Springboot拦截器实现IP黑名单
Springboot拦截器实现IP黑名单 一·业务场景和需要实现的功能 以redis作为IP存储地址实现. 业务场景:针对秒杀活动或者常规电商业务场景等,防止恶意脚本不停的刷接口. 实现功能:写一个拦 ...
- Pikachu的暴力破解演示-----基于表单的暴力破解
1 首先打开XAMMP与burpsuite 2 打开游览器输入127.0.0.1:88进入pikachu,(由于我的端口有80改成88所以输入127.0.0.1:88要是没有更改80只需要输入127. ...
- 涨姿势了解一下Kafka消费位移可好?
摘要:Kafka中的位移是个极其重要的概念,因为数据一致性.准确性是一个很重要的语义,我们都不希望消息重复消费或者丢失.而位移就是控制消费进度的大佬.本文就详细聊聊kafka消费位移的那些事,包括: ...
- 【asp.net core 系列】10 实战之ActionFilter
0.前言 在上一篇中,我们提到了如何创建一个UnitOfWork并通过ActionFilter设置启用.这一篇我们将简单介绍一下ActionFilter以及如何利用ActionFilter,顺便补齐一 ...
- 微信小程序之后端处理
首先,来看一下后端的关系图: 这边主要介绍PHP的一些基础语法等等,关于将php代码部署到SAE新浪云,大家可以参考这个链接:https://www.cnblogs.com/dhx96/p/65617 ...
- 学习 SQL Server (5) :视图,索引,事务和锁+T_SQL
--=============== 视图的创建 =================. --create view 视图名 as 查询语句--注意:视图查询中的字段不能重名-- 视图中的数据是‘假数据’ ...
- jenkins构建报错 Error fetching remote repo 'origin'
ERROR: Error fetching remote repo 'origin' Finished: FAILURE // 原因如下 原因一:可能是配置的git分支的权限问题,检查一下配置里面的源 ...
- Linux安装docker笔记
更新yum操作 yum -y update 安装docker yum install -y docker 或者yum install -y docker-engine 启动docker servic ...
- 第一步:安装centos_8
关于centos的安装其实大部分时候都是在虚拟机环境下安装. 好处无疑有这几个:方便,快速,主要就是整出事情了我可以直接删了重装 我这边是在vmware下进行一个安装 vmware我这边给出下载链接: ...
- 注册中心(Eureka/Consul)
基于SpringBoot1.5.4与SpringCloud(Dalston.SR2)的SpringCloud学习博客,转载请标明出处,O(∩_∩)O谢谢 - Spring Cloud简介 Spring ...