数据可视化实例(十一): 矩阵图(matplotlib,pandas)
矩阵图
https://datawhalechina.github.io/pms50/#/chapter9/chapter9
导入所需要的库
import numpy as np # 导入numpy库
import pandas as pd # 导入pandas库
import matplotlib as mpl # 导入matplotlib库
import matplotlib.pyplot as plt
import seaborn as sns # 导入seaborn库
%matplotlib inline # 在jupyter notebook显示图像
设定图像各种属性
large = 22; med = 16; small = 12
params = {'axes.titlesize': large, # 设置子图上的标题字体
'legend.fontsize': med, # 设置图例的字体
'figure.figsize': (16, 10), # 设置图像的画布
'axes.labelsize': med, # 设置标签的字体
'xtick.labelsize': med, # 设置x轴上的标尺的字体
'ytick.labelsize': med, # 设置整个画布的标题字体
'figure.titlesize': large}
#plt.rcParams.update(params) # 更新默认属性
plt.style.use('seaborn-whitegrid') # 设定整体风格
sns.set_style("white") # 设定整体背景风格
程序代码
# step1:导入数据
df = sns.load_dataset('iris')
# step2: 绘制矩阵图
# 画布
plt.figure(figsize = (12, 10), # 画布尺寸_(12, 10)
dpi = 80) # 分辨率_80
# 矩阵图
sns.pairplot(df, # 使用的数据
kind = 'scatter', # 绘制图像的类型_scatter
hue = 'species', # 类别的列,让不同类别具有不谈的颜色
plot_kws = dict(s = 50, # 点的尺寸
edgecolor = 'white', # 边缘颜色
linewidth = 2.5)) # 线宽

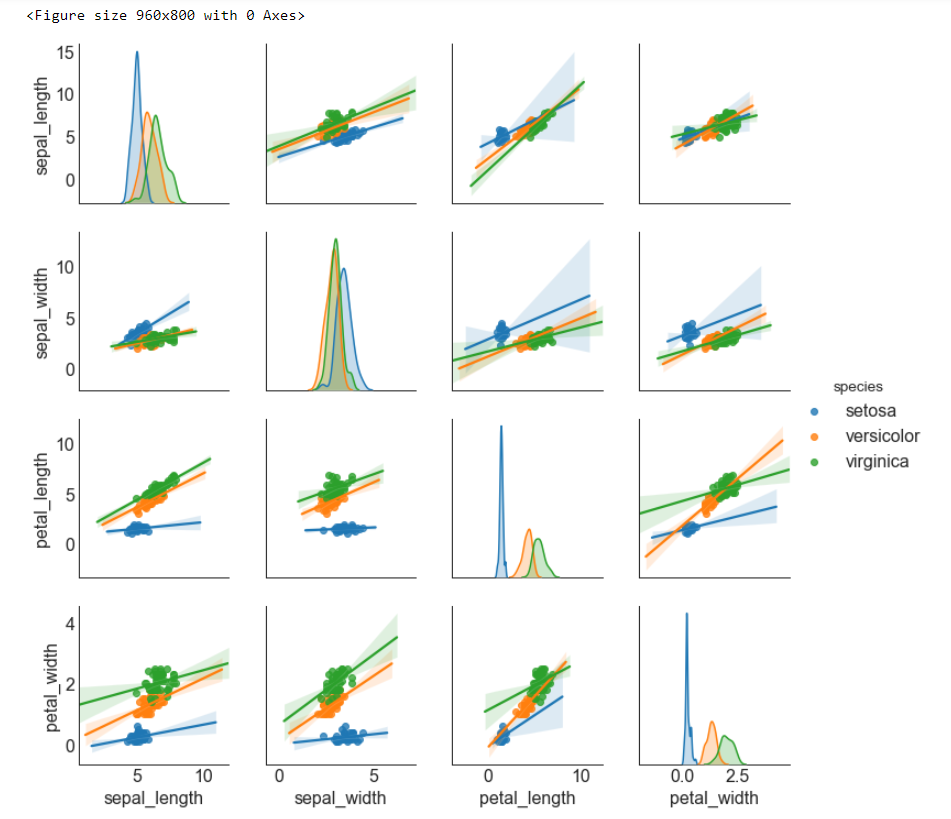
# step1:导入数据
df = sns.load_dataset('iris')
# step2: 绘制矩阵图
# 画布
plt.figure(figsize = (12, 10), # 画布尺寸_(12, 10)
dpi = 80) # 分辨率_80
# 矩阵图(带有拟合线的散点图)
sns.pairplot(df, # 使用的数据
kind = 'reg', # 绘制图像的类型_reg
hue = 'species') # 类别的列,让不同类别具有不谈的颜色
博文总结
seaborn.pairplot
seaborn.pairplot(data, hue=None, hue_order=None,
palette=None, vars=None, x_vars=None, y_vars=None, kind='scatter',
diag_kind='auto', markers=None, height=2.5, aspect=1,
dropna=True, plot_kws=None, diag_kws=None, grid_kws=None, size=None)
Plot pairwise relationships in a dataset.
By default, this function will create a grid of Axes such that each variable in data will by shared in the y-axis across a single row and in the x-axis across a single column.
The diagonal Axes are treated differently, drawing a plot to show the univariate distribution of the data for the variable in that column.
It is also possible to show a subset of variables or plot different variables on the rows and columns.
This is a high-level interface for PairGrid that is intended to make it easy to draw a few common styles. You should use PairGriddirectly if you need more flexibility.
参数:data:DataFrame
Tidy (long-form) dataframe where each column is a variable and each row is an observation.
hue:string (variable name), optional
Variable in
datato map plot aspects to different colors.
hue_order:list of strings
Order for the levels of the hue variable in the palette
palette:dict or seaborn color palette
Set of colors for mapping the
huevariable. If a dict, keys should be values in thehuevariable.
vars:list of variable names, optional
Variables within
datato use, otherwise use every column with a numeric datatype.
{x, y}_vars:lists of variable names, optional
Variables within
datato use separately for the rows and columns of the figure; i.e. to make a non-square plot.
kind:{‘scatter’, ‘reg’}, optional
Kind of plot for the non-identity relationships.
diag_kind:{‘auto’, ‘hist’, ‘kde’}, optional
Kind of plot for the diagonal subplots. The default depends on whether
"hue"is used or not.
markers:single matplotlib marker code or list, optional
Either the marker to use for all datapoints or a list of markers with a length the same as the number of levels in the hue variable so that differently colored points will also have different scatterplot markers.
height:scalar, optional
Height (in inches) of each facet.
aspect:scalar, optional
Aspect * height gives the width (in inches) of each facet.
dropna:boolean, optional
Drop missing values from the data before plotting.
{plot, diag, grid}_kws:dicts, optional
Dictionaries of keyword arguments.
返回值:grid:PairGrid
Returns the underlying
PairGridinstance for further tweaking.
seaborn.load_dataset
seaborn.load_dataset(name, cache=True, data_home=None, **kws)
从在线库中获取数据集(需要联网)。
参数:name:字符串
数据集的名字 (<cite>name</cite>.csv on https://github.com/mwaskom/seaborn-data)。 您可以通过
get_dataset_names()获取可用的数据集。
cache:boolean, 可选
如果为True,则在本地缓存数据并在后续调用中使用缓存。
data_home:string, 可选
用于存储缓存数据的目录。 默认情况下使用 ~/seaborn-data/
kws:dict, 可选
传递给 pandas.read_csv
数据可视化实例(十一): 矩阵图(matplotlib,pandas)的更多相关文章
- 【Matplotlib】数据可视化实例分析
数据可视化实例分析 作者:白宁超 2017年7月19日09:09:07 摘要:数据可视化主要旨在借助于图形化手段,清晰有效地传达与沟通信息.但是,这并不就意味着数据可视化就一定因为要实现其功能用途而令 ...
- 数据可视化实例(十四):面积图 (matplotlib,pandas)
偏差 (Deviation) 面积图 (Area Chart) 通过对轴和线之间的区域进行着色,面积图不仅强调峰和谷,而且还强调高点和低点的持续时间. 高点持续时间越长,线下面积越大. https:/ ...
- 数据可视化实例(三): 散点图(pandas,matplotlib,numpy)
关联 (Correlation) 关联图表用于可视化2个或更多变量之间的关系. 也就是说,一个变量如何相对于另一个变化. 散点图(Scatter plot) 散点图是用于研究两个变量之间关系的经典的和 ...
- seaborn线性关系数据可视化:时间线图|热图|结构化图表可视化
一.线性关系数据可视化lmplot( ) 表示对所统计的数据做散点图,并拟合一个一元线性回归关系. lmplot(x, y, data, hue=None, col=None, row=None, p ...
- seaborn分布数据可视化:直方图|密度图|散点图
系统自带的数据表格(存放在github上https://github.com/mwaskom/seaborn-data),使用时通过sns.load_dataset('表名称')即可,结果为一个Dat ...
- 数据可视化实例(十四):带标记的发散型棒棒糖图 (matplotlib,pandas)
偏差 (Deviation) 带标记的发散型棒棒糖图 (Diverging Lollipop Chart with Markers) 带标记的棒棒糖图通过强调您想要引起注意的任何重要数据点并在图表中适 ...
- 数据可视化实例(十七):包点图 (matplotlib,pandas)
排序 (Ranking) 包点图 (Dot Plot) 包点图表传达了项目的排名顺序,并且由于它沿水平轴对齐,因此您可以更容易地看到点彼此之间的距离. https://datawhalechina.g ...
- 数据可视化实例(九): 边缘箱形图(matplotlib,pandas)
https://datawhalechina.github.io/pms50/#/chapter7/chapter7 边缘箱形图 (Marginal Boxplot) 边缘箱图与边缘直方图具有相似的用 ...
- 数据可视化实例(七): 计数图(matplotlib,pandas)
https://datawhalechina.github.io/pms50/#/chapter5/chapter5 计数图 (Counts Plot) 避免点重叠问题的另一个选择是增加点的大小,这取 ...
随机推荐
- ORM框架 Mybatis、Hibernate、Spring Data JPA之到底该用谁,谁更牛*
在持久层框架中无可厚非的就是mybatis了,但是也会经常被人问到为啥要用mybatis,为啥不用hibernate,jpa.很多人各级都是地铁爷爷看手机的表情,似乎从来没想过这个问题.“公司叫用我就 ...
- 【原创】Linux中断子系统(三)-softirq和tasklet
背景 Read the fucking source code! --By 鲁迅 A picture is worth a thousand words. --By 高尔基 说明: Kernel版本: ...
- python自如爬虫
如果你想入门数据分析,但是苦于没有数据,那就看下文如何用 10 行代码写一个最简单的自如房源爬虫 首先我们通过分析看到自如手机版有个 url 如下:http://m.ziroom.com/list/a ...
- C# WPF - MVVM实现OPC Client管理系统
前言 本文主要讲解采用WPF MVVM模式设计OPC Client的过程,算作对于WPF MVVM架构的学习记录吧!不足之处请不吝赐教,感谢! 涉及知识点 C#基础 Xaml基础 命令.通知和数据绑定 ...
- selenium(5)-解读强制等待,隐式等待,显式等待的区别
背景 为什么要设置元素等待 因为,目前大多数Web应用程序都是使用Ajax和Javascript开发的:每次加载一个网页,就会加载各种HTML标签.JS文件 但是,加载肯定有加载顺序,大型网站很难说一 ...
- SpringMVC 学习笔记(7)异常操作
如何使用HandleException 在程序中,异常是最常见的,我们需要捕捉异常并处理它,才能保证程序不被终止. 最常见的异常处理方法就是用try catch来捕捉异常.这次我们使用springmv ...
- Jmeter系列(30)- 详解 JDBC Request
如果你想从头学习Jmeter,可以看看这个系列的文章哦 https://www.cnblogs.com/poloyy/category/1746599.html 前言 JDBC Request 主要是 ...
- Alink漫谈(八) : 二分类评估 AUC、K-S、PRC、Precision、Recall、LiftChart 如何实现
Alink漫谈(八) : 二分类评估 AUC.K-S.PRC.Precision.Recall.LiftChart 如何实现 目录 Alink漫谈(八) : 二分类评估 AUC.K-S.PRC.Pre ...
- JAVA集合框架 - Map接口
Map 接口大致说明(jdk11): 整体介绍: 一个将键映射到值的(key-value)对象, 键值(key)不能重复, 每个键值只能影射一个对象(一一对应). 这个接口取代了Dictionary类 ...
- 入门大数据---Hbase协处理器详解
一.简述 Hbase 作为列族数据库最经常被人诟病的特性包括:无法轻易建立"二级索引",难以执 行求和.计数.排序等操作.比如,在旧版本的(<0.92)Hbase 中,统计数 ...