Python爬虫从入门到放弃(十八)之 Scrapy爬取所有知乎用户信息(上)
爬取的思路
首先我们应该找到一个账号,这个账号被关注的人和关注的人都相对比较多的,就是下图中金字塔顶端的人,然后通过爬取这个账号的信息后,再爬取他关注的人和被关注的人的账号信息,然后爬取被关注人的账号信息和被关注信息的关注列表,爬取这些用户的信息,通过这种递归的方式从而爬取整个知乎的所有的账户信息。整个过程通过下面两个图表示:

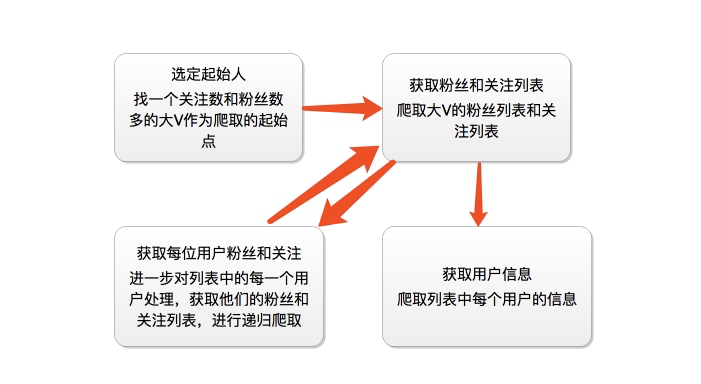
爬虫分析过程
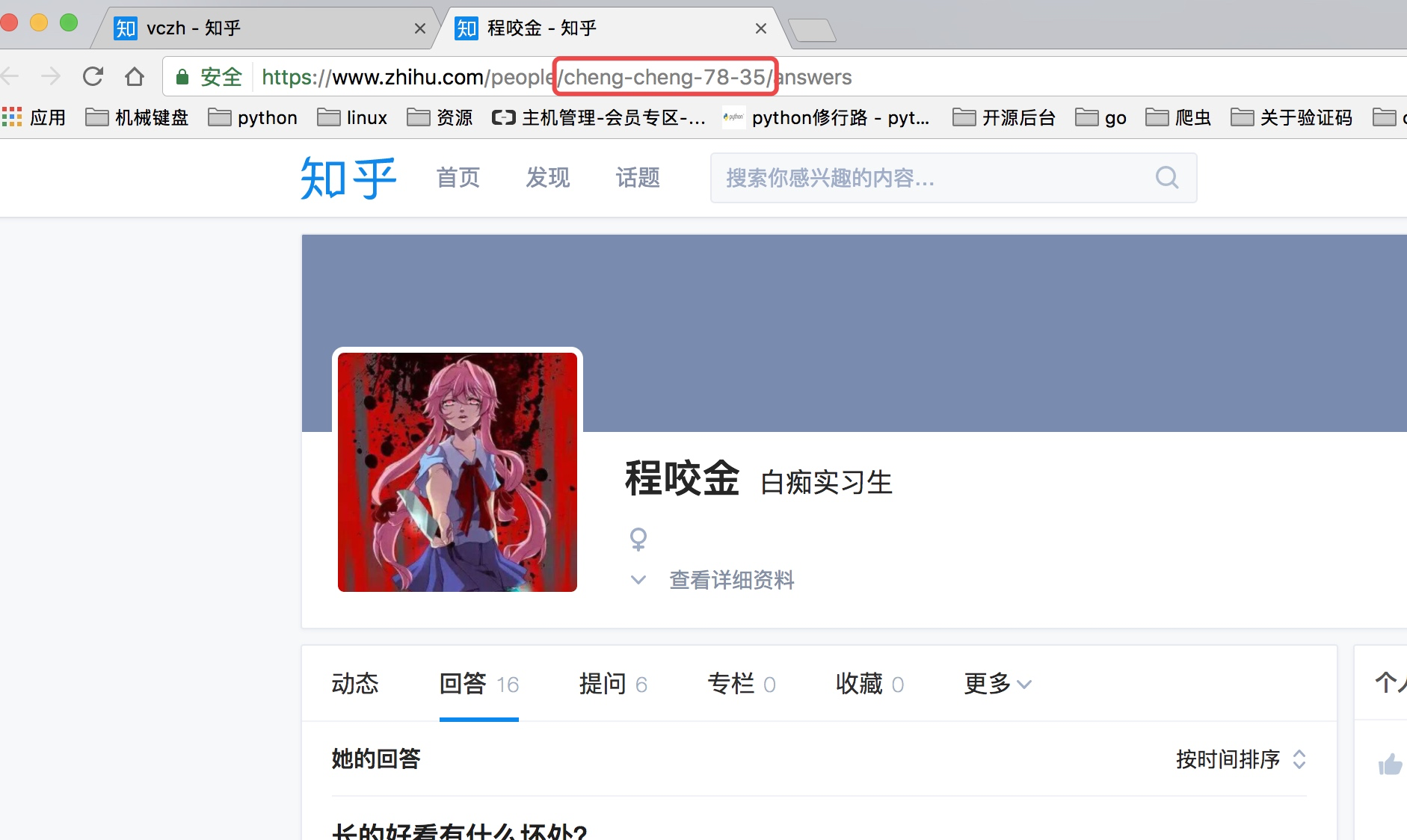
这里我们找的账号地址是:https://www.zhihu.com/people/excited-vczh/answers
我们抓取的大V账号的主要信息是:

其次我们要获取这个账号的关注列表和被关注列表
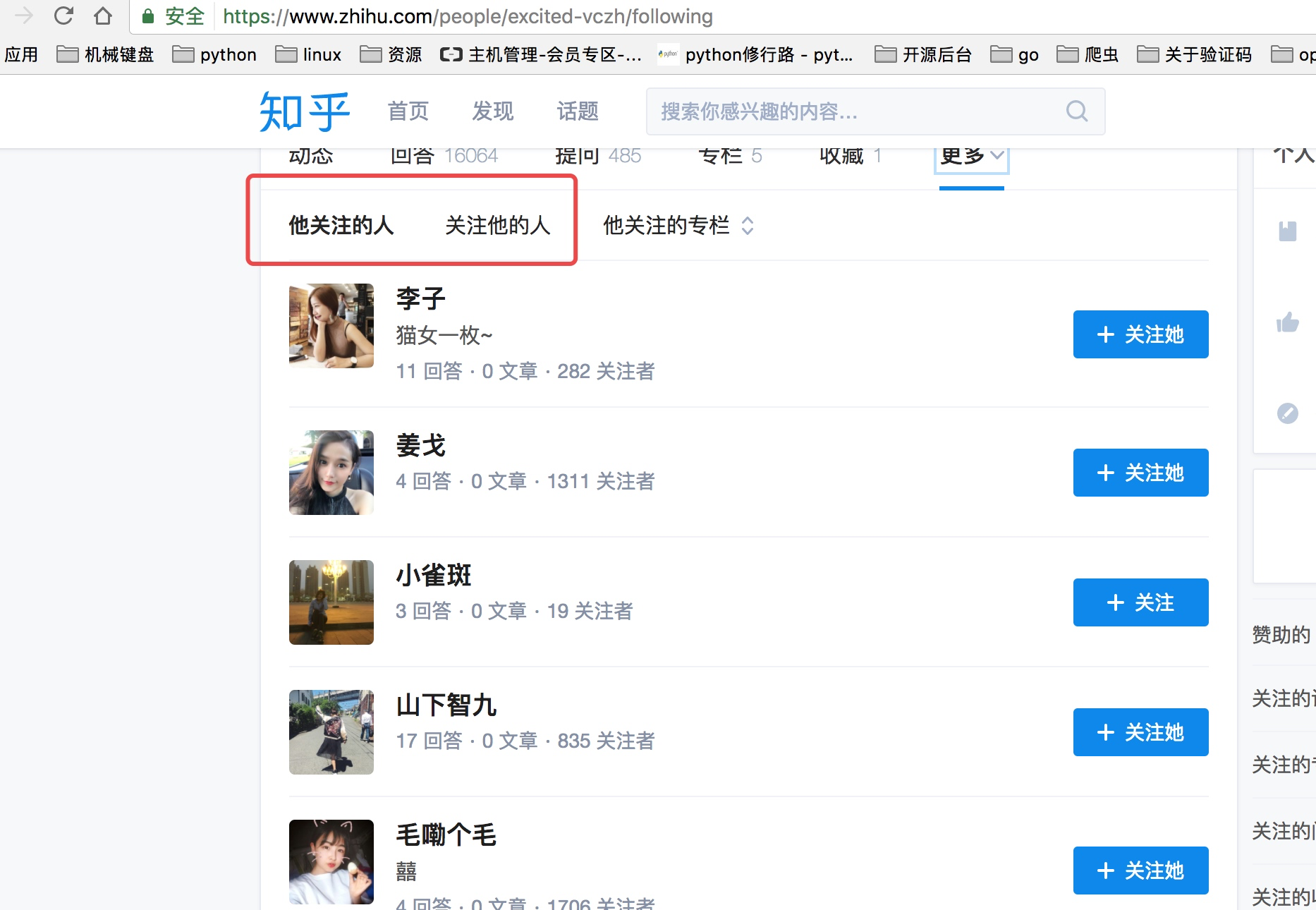
这里我们需要通过抓包分析如果获取这些列表的信息以及用户的个人信息内容
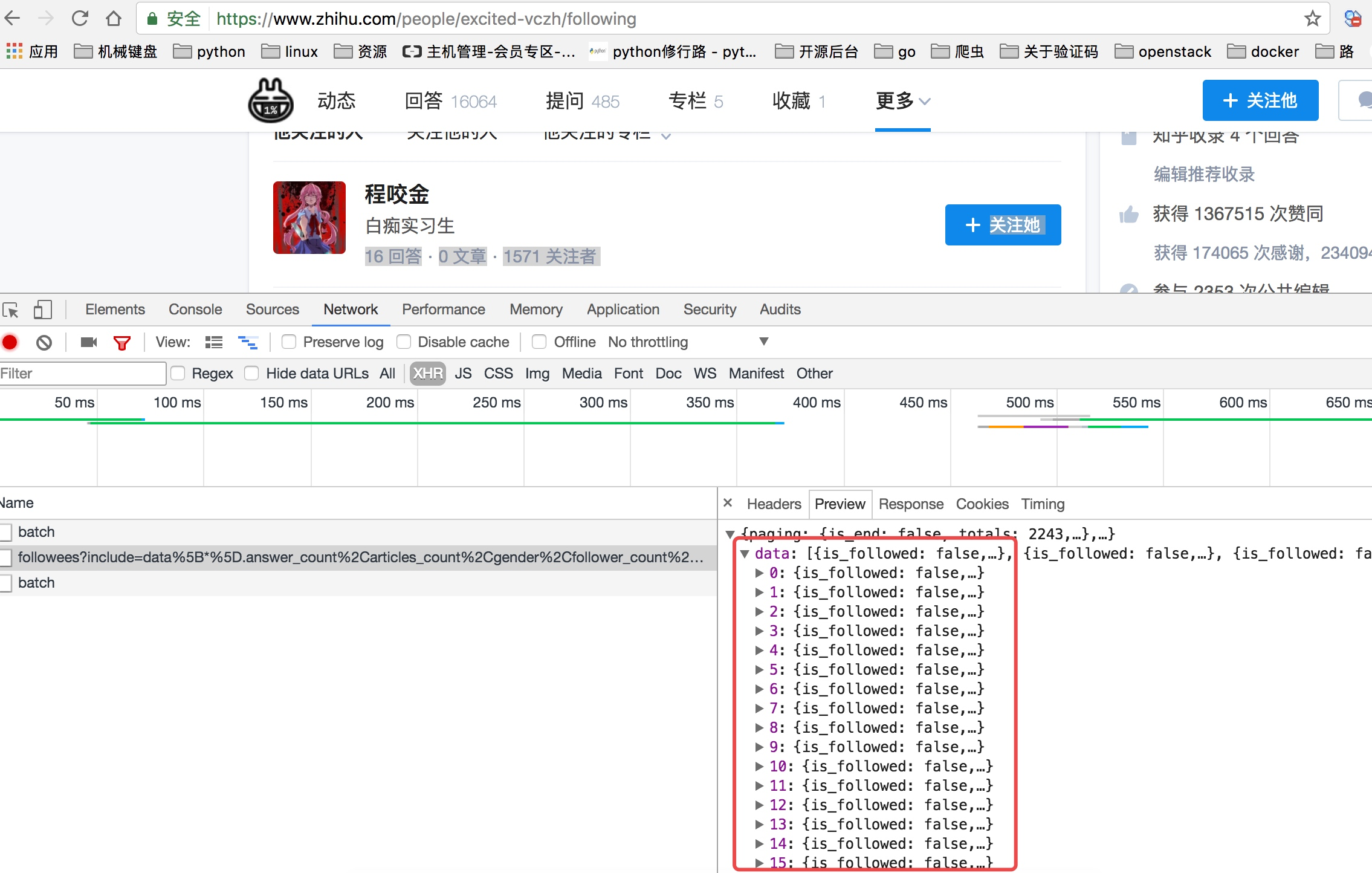
当我们查看他关注人的列表的时候我们可以看到他请求了如下图中的地址,并且我们可以看到返回去的结果是一个json数据,而这里就存着一页关乎的用户信息。


上面虽然可以获取单个用户的个人信息,但是不是特别完整,这个时候我们获取一个人的完整信息地址是当我们将鼠标放到用户名字上面的时候,可以看到发送了一个请求:
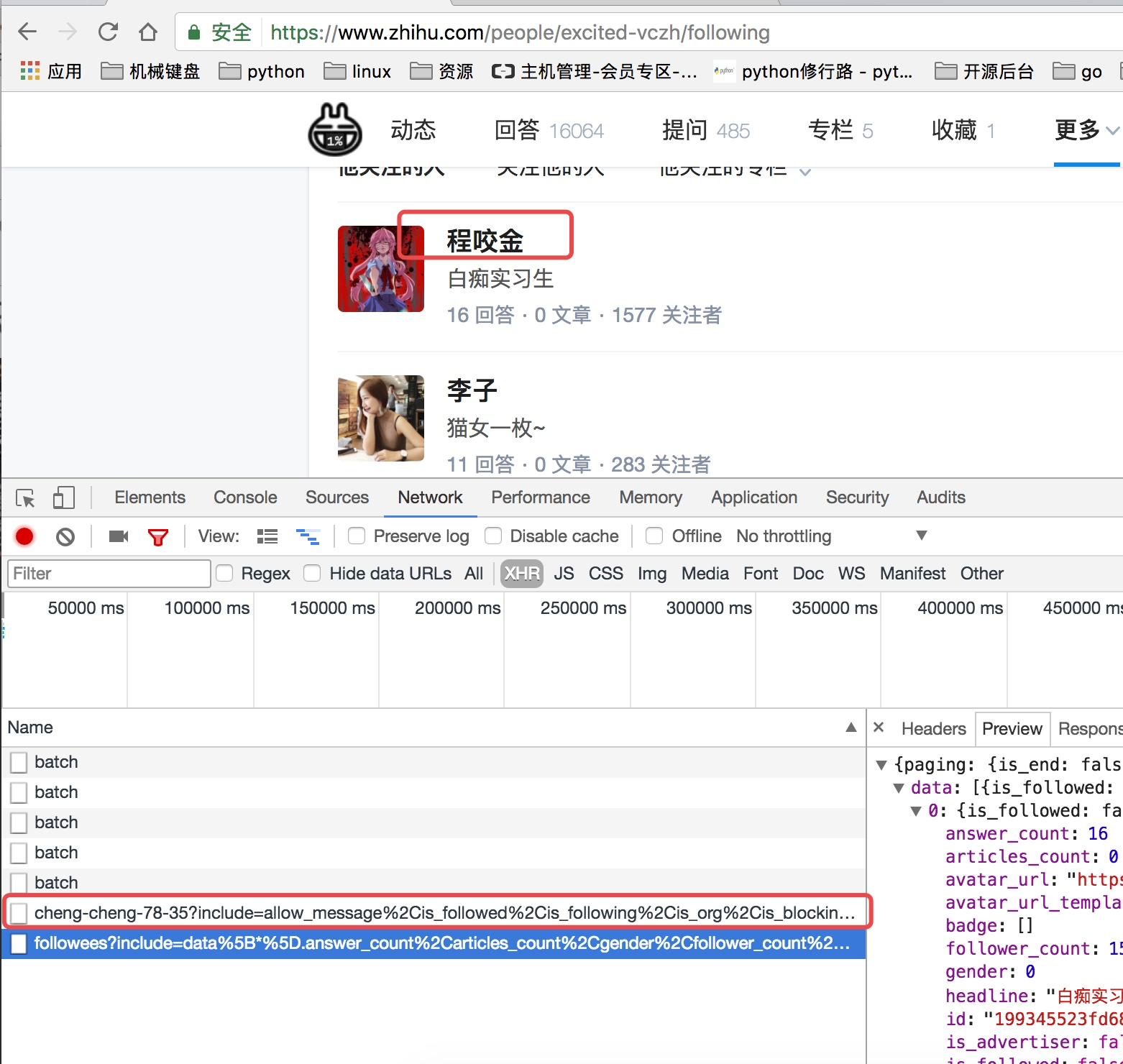
我们可以看这个地址的返回结果可以知道,这个地址请求获取的是用户的详细信息:

通过上面的分析我们知道了以下两个地址:
获取用户关注列表的地址:https://www.zhihu.com/api/v4/members/excited-vczh/followees?include=data%5B*%5D.answer_count%2Carticles_count%2Cgender%2Cfollower_count%2Cis_followed%2Cis_following%2Cbadge%5B%3F(type%3Dbest_answerer)%5D.topics&offset=0&limit=20
这里我们可以从请求的这两个地址里发现一个问题,关于用户信息里的url_token其实就是获取单个用户详细信息的一个凭证也是请求的一个重要参数,并且当我们点开关注人的的链接时发现请求的地址的唯一标识也是这个url_token
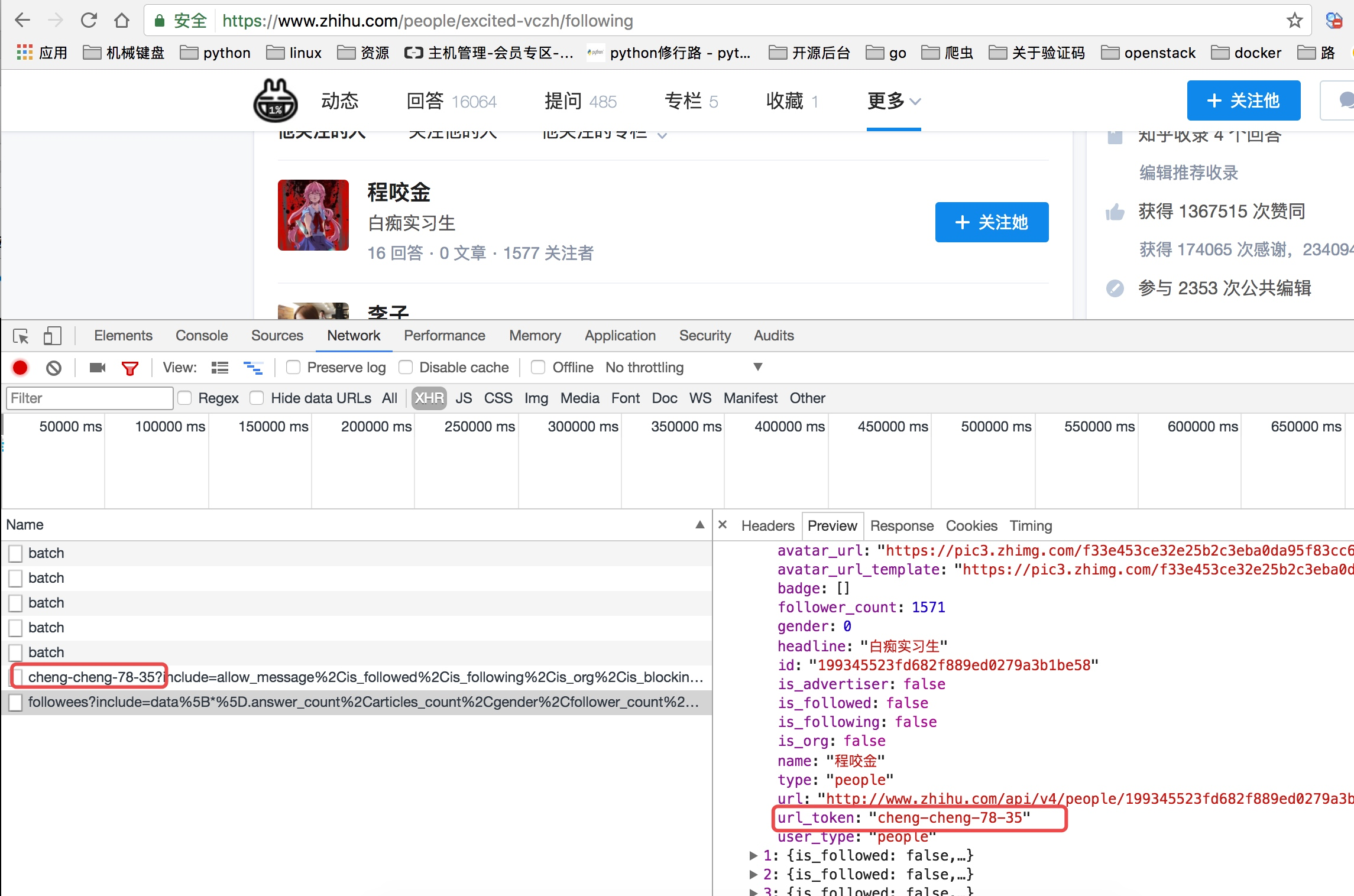
创建项目进行再次分析
通过命令创建项目
scrapy startproject zhihu_user
cd zhihu_user
scrapy genspider zhihu www.zhihu.com
直接通过scrapy crawl zhihu启动爬虫会看到如下错误:

这个问题其实是爬取网站的时候经常碰到的问题,大家以后见多了就知道是怎么回事了,是请求头的问题,应该在请求头中加User-Agent,在settings配置文件中有关于请求头的配置默认是被注释的,我们可以打开,并且加上User-Agent,如下:
关于如何获取User-Agent,可以在抓包的请求头中看到也可以在谷歌浏览里输入:chrome://version/ 查看
这样我们就可以正常通过代码访问到知乎了
然后我们可以改写第一次的请求,这个我们前面的scrapy文章关于spiders的时候已经说过如何改写start_request,我们让第一次请求分别请求获取用户列表以及获取用户信息

这个时候我们再次启动爬虫

我们会看到是一个401错误,而解决的方法其实还是请求头的问题,从这里我们也可以看出请求头中包含的很多信息都会影响我们爬取这个网站的信息,所以当我们很多时候直接请求网站都无法访问的时候就可以去看看请求头,看看是不是请求头的哪些信息导致了请求的结果,而这里则是因为如下图所示的参数:
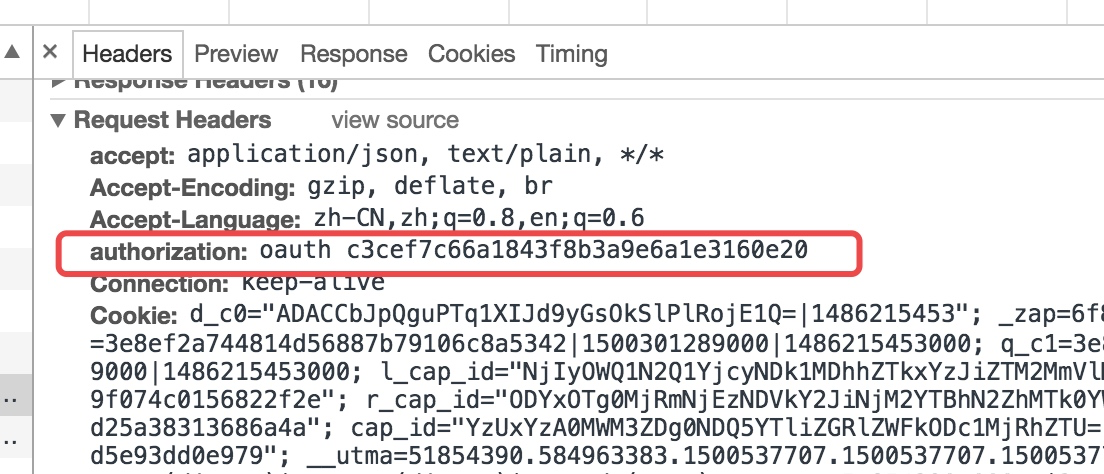
所以我们需要把这个参数同样添加到请求头中:

然后重新启动爬虫,这个时候我们已经可以获取到正常的内容
到此基本的分析可以说是都分析好了,剩下的就是具体代码的实现,在下一篇文张中写具体的实现代码内容!
Python爬虫从入门到放弃(十八)之 Scrapy爬取所有知乎用户信息(上)的更多相关文章
- Python之爬虫(二十) Scrapy爬取所有知乎用户信息(上)
爬取的思路 首先我们应该找到一个账号,这个账号被关注的人和关注的人都相对比较多的,就是下图中金字塔顶端的人,然后通过爬取这个账号的信息后,再爬取他关注的人和被关注的人的账号信息,然后爬取被关注人的账号 ...
- Python爬虫从入门到放弃(十九)之 Scrapy爬取所有知乎用户信息(下)
在上一篇文章中主要写了关于爬虫过程的分析,下面是代码的实现,完整代码在:https://github.com/pythonsite/spider items中的代码主要是我们要爬取的字段的定义 cla ...
- Python之爬虫(二十一) Scrapy爬取所有知乎用户信息(下)
在上一篇文章中主要写了关于爬虫过程的分析,下面是代码的实现,完整代码在:https://github.com/pythonsite/spider items中的代码主要是我们要爬取的字段的定义 cla ...
- python爬虫从入门到放弃(八)之 Selenium库的使用
一.什么是Selenium selenium 是一套完整的web应用程序测试系统,包含了测试的录制(selenium IDE),编写及运行(Selenium Remote Control)和测试的并行 ...
- Python爬虫从入门到放弃(二十)之 Scrapy分布式原理
关于Scrapy工作流程回顾 Scrapy单机架构 上图的架构其实就是一种单机架构,只在本机维护一个爬取队列,Scheduler进行调度,而要实现多态服务器共同爬取数据关键就是共享爬取队列. 分布式架 ...
- Python爬虫从入门到放弃(二十二)之 爬虫与反爬虫大战
爬虫与发爬虫的厮杀,一方为了拿到数据,一方为了防止爬虫拿到数据,谁是最后的赢家? 重新理解爬虫中的一些概念 爬虫:自动获取网站数据的程序反爬虫:使用技术手段防止爬虫程序爬取数据误伤:反爬虫技术将普通用 ...
- python爬虫从入门到放弃(三)之 Urllib库的基本使用
官方文档地址:https://docs.python.org/3/library/urllib.html 什么是Urllib Urllib是python内置的HTTP请求库包括以下模块urllib.r ...
- Python爬虫从入门到放弃(十一)之 Scrapy框架整体的一个了解
这里是通过爬取伯乐在线的全部文章为例子,让自己先对scrapy进行一个整理的理解 该例子中的详细代码会放到我的github地址:https://github.com/pythonsite/spider ...
- Python之爬虫从入门到放弃(十三) Scrapy框架整体的了解
这里是通过爬取伯乐在线的全部文章为例子,让自己先对scrapy进行一个整理的理解 该例子中的详细代码会放到我的github地址:https://github.com/pythonsite/spider ...
随机推荐
- 《如莲春天》Java开发框架
关于 如莲者,净洁如莲之意,希望打造一个简洁的系统框架.系统主要采用Spring相关技术,故取名:如莲春天. 如莲春天,包括一套系统界面.一个权限管理系统.一个CURD代码生成模块.一些基础模块 ...
- Vue.js 运行环境搭建详解(基于windows的手把手安装教学)及vue、node基础知识普及
Vue.js 是一套构建用户界面的渐进式框架.他自身不是一个全能框架——只聚焦于视图层.因此它非常容易学习,非常容易与其它库或已有项目整合.在与相关工具和支持库一起使用时,Vue.js 也能完美地驱动 ...
- Dojo初探之4:dojo的event(鼠标/键盘)事件绑定操作(基于dojo1.11.2版本)
前言: 上一章详解了dojo的dom/query操作,本章基于dom/query基础上进行事件绑定操作 dojo的事件 dojo的事件绑定操作分为鼠标和键盘两种进行详解 1.鼠标事件 我们沿用上一章中 ...
- 不完全翻译:Threading in C#-Getting Started
Introduction(引入,介绍) and Concepts(概念) 原文地址:http://www.albahari.com/threading/ 注:水平有限不能全文翻译,备注了个别字段和短句 ...
- 在windows下使用Qt5开发GTK3图形界面应用程序
首先,去MSYS2官网下载MSYS2环境并安装在C:/mysys64下,我安装的是64位的. 进入MSYS命令行执行: pacman -S mingw-w64-x86_64-gtk3 pacman - ...
- Bash中单引号和双引号的区别
单引号和双引号的区别 单引号:必须成对使用,它可以保护所有的字符不被翻译.如变量$1,和奇数个单引号的作用相同,偶数个单引号=1个双引号双引号:必须成对出现,它可以保护一些元字符不被翻译,但允许变量和 ...
- Python pycrypto 加密与解密
参考: python 使用 pycrypto 实现 AES 加密解密 参考: 分组对称加密模式:ECB/CBC/CFB/OFB 代码示例 : import hashlib from Crypto.C ...
- Spring boot 1: 使用IDEA创建Spring boot项目
项目用到的环境: Windows 10 JDK8 IntelliJ IDEA 2017.1.3 Apache Tomcat 8 Maven 3.3.3 使用IDEA新建spring boot项目 新建 ...
- vue中数据双向绑定注意点
最近一个vue和element的项目中遇到了一个问题: 动态生成的对象进行双向绑定是失败 直接贴代码: <el-form :model="addClass" :rules=& ...
- Hibernate执行原生态sql语句
@Override public Integer update(String id, String username){ String sql = "update Team_CheLiang ...