python爬虫——用selenium爬取京东商品信息
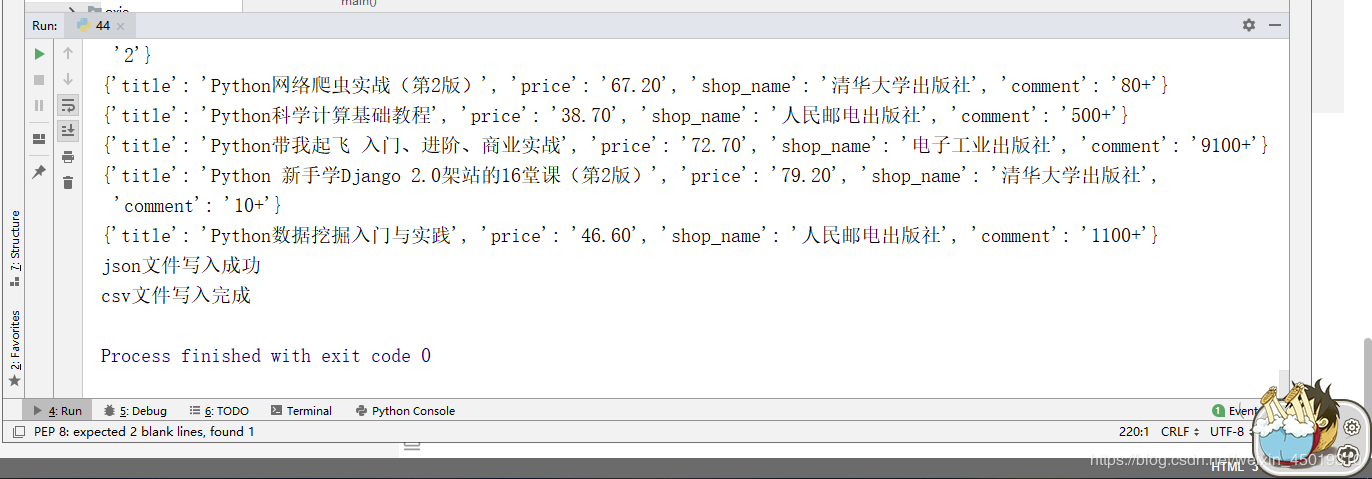
1.先附上效果图(我偷懒只爬了4页)

2.京东的网址https://www.jd.com/
3.我这里是不加载图片,加快爬取速度,也可以用Headless无弹窗模式
options = webdriver.ChromeOptions()
options.add_experimental_option('prefs', {'profile.managed_default_content_settings.images': 2})
#不加载图片
browser = webdriver.Chrome(options=options)
wait =WebDriverWait(browser,50)#设置等待时间
url = 'https://www.jd.com/'
data_list = []#设置全局变量用来存储数据
keyword="python爬虫"#关键词
4.先找到搜索框并用selenium模拟点击(这里发现京东不需要登录就能看到商品信息)
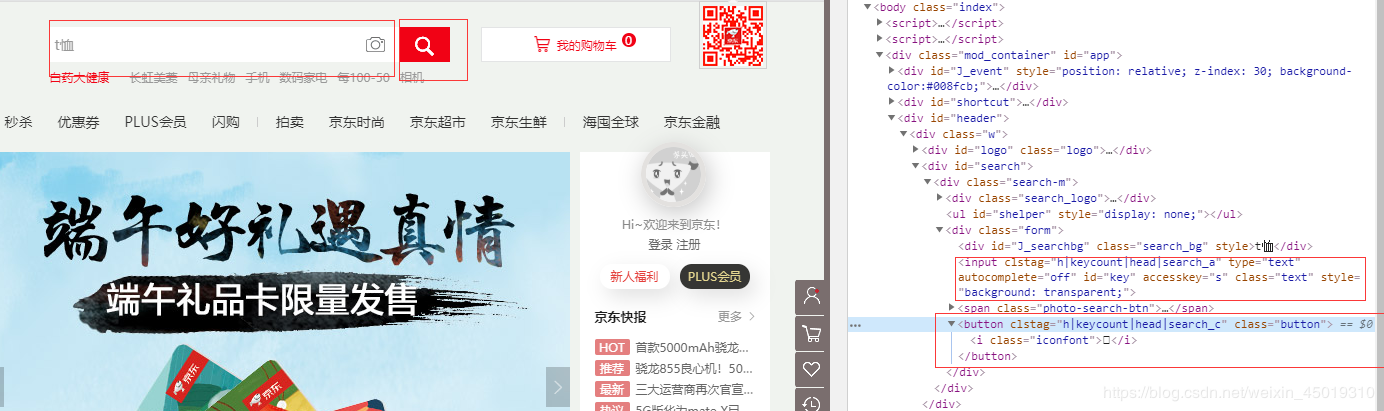
def search():
browser.get('https://www.jd.com/')
try:
input = wait.until(
EC.presence_of_all_elements_located((By.CSS_SELECTOR, "#key"))
) #等到搜索框加载出来
submit = wait.until(
EC.element_to_be_clickable((By.CSS_SELECTOR, "#search > div > div.form > button"))
)#等到搜索按钮可以被点击
input[0].send_keys(keyword)#向搜索框内输入关键词
submit.click()#点击
total = wait.until(
EC.presence_of_all_elements_located(
(By.CSS_SELECTOR, '#J_bottomPage > span.p-skip > em:nth-child(1) > b')
)
)#记录一下总页码,等到总页码加载出来
html = browser.page_source#获取网页信息
prase_html(html)#调用提取数据的函数(后面才写到)
return total[0].text
except TimeoutError:
search()
5.进入了第一页,先写好翻页的函数,需要滑动到底部才能加载后30个商品,总共有60个商品
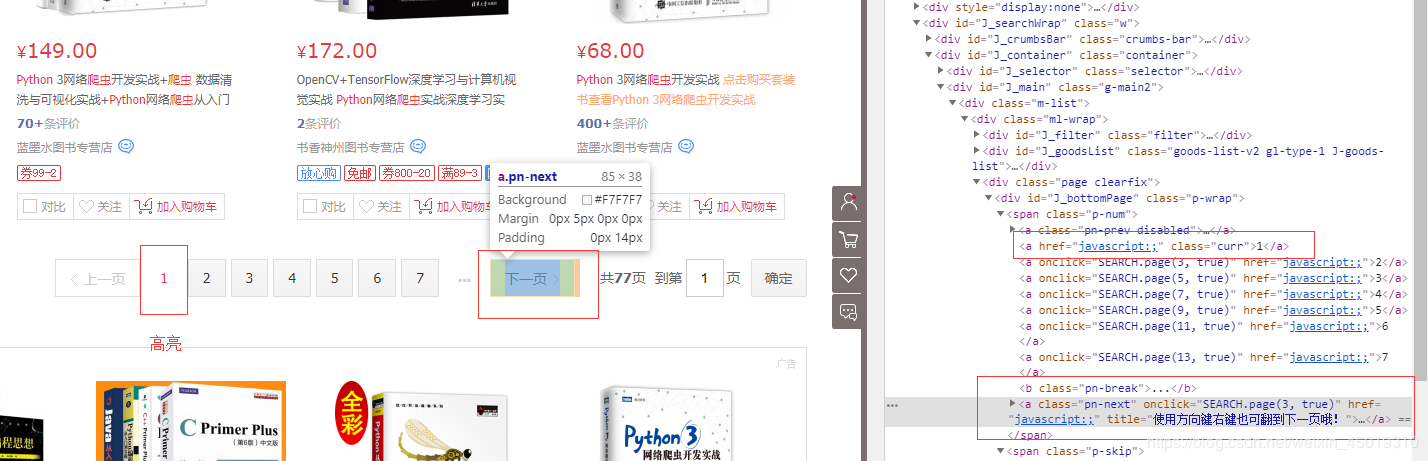
def next_page(page_number):
try:
# 滑动到底部
browser.execute_script("window.scrollTo(0, document.body.scrollHeight);")
time.sleep(random.randint(1, 3))#设置随机延迟
button = wait.until(
EC.element_to_be_clickable((By.CSS_SELECTOR, '#J_bottomPage > span.p-num > a.pn-next > em'))
)#翻页按钮
button.click()# 翻页动作
wait.until(
EC.presence_of_all_elements_located((By.CSS_SELECTOR, "#J_goodsList > ul > li:nth-child(30)"))
)#等到30个商品都加载出来
# 滑动到底部,加载出后三十个货物信息
browser.execute_script("window.scrollTo(0, document.body.scrollHeight);")
wait.until(
EC.presence_of_all_elements_located((By.CSS_SELECTOR, "#J_goodsList > ul > li:nth-child(60)"))
)#等到60个商品都加载出来
wait.until(
EC.text_to_be_present_in_element((By.CSS_SELECTOR, "#J_bottomPage > span.p-num > a.curr"), str(page_number))
)# 判断翻页成功,高亮的按钮数字与设置的页码一样
html = browser.page_source#获取网页信息
prase_html(html)#调用提取数据的函数
except TimeoutError:
return next_page(page_number)
6.能正常翻页就简单很多了,开始抽取需要的商品信息,搜索不同的关键词,页面的布局会有变化,需要重新写定位商品信息
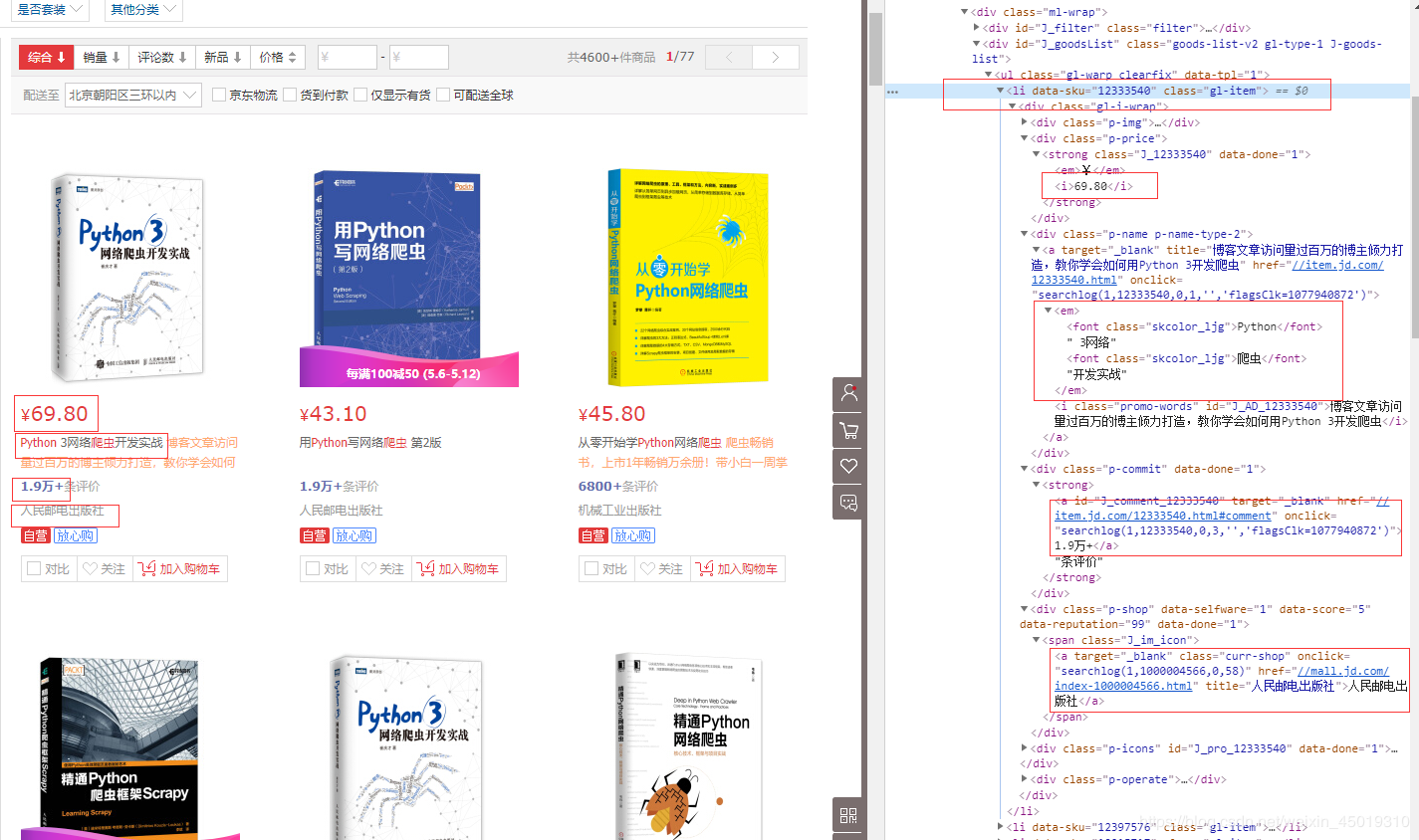
def prase_html(html):
html = etree.HTML(html)
# 开始提取信息,找到ul标签下的全部li标签
try:
lis = browser.find_elements_by_class_name('gl-item')
# 遍历
for li in lis:
# 名字
title = li.find_element_by_xpath('.//div[@class="p-name p-name-type-2"]//em').text
# 价格
price = li.find_element_by_xpath('.//div[@class="p-price"]//i').text
# 评论数
comment = li.find_elements_by_xpath('.//div[@class="p-commit"]//a')
# 商铺名字
shop_name = li.find_elements_by_xpath('.//div[@class="p-shop"]//a')
if comment:
comment = comment[0].text
else:
comment = None
if shop_name:
shop_name = shop_name[0].text
else:
shop_name = None
data_dict ={}#写入字典
data_dict["title"] = title
data_dict["price"] = price
data_dict["shop_name"] = shop_name
data_dict["comment"] = comment
print(data_dict)
data_list.append(data_dict)#写入全局变量
except TimeoutError:
prase_html(html)
7.存储方法
def save_html():
content = json.dumps(data_list, ensure_ascii=False, indent=2)
#把全局变量转化为json数据
with open("jingdong.json", "a+", encoding="utf-8") as f:
f.write(content)
print("json文件写入成功") with open('jingdong.csv', 'w', encoding='utf-8', newline='') as f:
# 表头
title = data_list[0].keys()
# 声明writer
writer = csv.DictWriter(f, title)
# 写入表头
writer.writeheader()
# 批量写入数据
writer.writerows(data_list)
print('csv文件写入完成')
8.开始调用
def main():
print("第", 1, "页:")
total = int(search())
for i in range(2, 5):
# for i in range(2, total + 1):#想全爬的就用这个循环
time.sleep(random.randint(1, 3))#设置随机延迟
print("第", i, "页:")
next_page(i)
save_html() if __name__ == "__main__":
main()
9.附上完整代码
import time
from selenium import webdriver
from selenium.webdriver.support import expected_conditions as EC
from selenium.webdriver.common.by import By
from selenium.webdriver.support.ui import WebDriverWait
import random
import json
import csv
from lxml import etree options = webdriver.ChromeOptions()
options.add_experimental_option('prefs', {'profile.managed_default_content_settings.images': 2})
#不加载图片
browser = webdriver.Chrome(options=options)
wait =WebDriverWait(browser,50)#设置等待时间
url = 'https://www.jd.com/'
data_list= []#设置全局变量用来存储数据
keyword ="python爬虫"#关键词 def search():
browser.get('https://www.jd.com/')
try:
input = wait.until(
EC.presence_of_all_elements_located((By.CSS_SELECTOR, "#key"))
) #等到搜索框加载出来
submit = wait.until(
EC.element_to_be_clickable((By.CSS_SELECTOR, "#search > div > div.form > button"))
)#等到搜索按钮可以被点击
input[0].send_keys(keyword)#向搜索框内输入关键词
submit.click()#点击
total = wait.until(
EC.presence_of_all_elements_located(
(By.CSS_SELECTOR, '#J_bottomPage > span.p-skip > em:nth-child(1) > b')
)
)#记录一下总页码,等到总页码加载出来
# # 滑动到底部,加载出后三十个货物信息
# browser.execute_script("window.scrollTo(0, document.body.scrollHeight);")
# wait.until(
# EC.presence_of_all_elements_located((By.CSS_SELECTOR, "#J_goodsList > ul > li:nth-child(60)"))
# )
html = browser.page_source#获取网页信息
prase_html(html)#调用提取数据的函数
return total[0].text#返回总页数
except TimeoutError:
search() def next_page(page_number):
try:
# 滑动到底部
browser.execute_script("window.scrollTo(0, document.body.scrollHeight);")
time.sleep(random.randint(1, 3))#设置随机延迟
button = wait.until(
EC.element_to_be_clickable((By.CSS_SELECTOR, '#J_bottomPage > span.p-num > a.pn-next > em'))
)#翻页按钮
button.click()# 翻页动作
wait.until(
EC.presence_of_all_elements_located((By.CSS_SELECTOR, "#J_goodsList > ul > li:nth-child(30)"))
)#等到30个商品都加载出来
# 滑动到底部,加载出后三十个货物信息
browser.execute_script("window.scrollTo(0, document.body.scrollHeight);")
wait.until(
EC.presence_of_all_elements_located((By.CSS_SELECTOR, "#J_goodsList > ul > li:nth-child(60)"))
)#等到60个商品都加载出来
wait.until(
EC.text_to_be_present_in_element((By.CSS_SELECTOR, "#J_bottomPage > span.p-num > a.curr"), str(page_number))
)# 判断翻页成功,高亮的按钮数字与设置的页码一样
html = browser.page_source#获取网页信息
prase_html(html)#调用提取数据的函数
except TimeoutError:
return next_page(page_number) def prase_html(html):
html = etree.HTML(html)
# 开始提取信息,找到ul标签下的全部li标签
try:
lis = browser.find_elements_by_class_name('gl-item')
# 遍历
for li in lis:
# 名字
title = li.find_element_by_xpath('.//div[@class="p-name p-name-type-2"]//em').text
# 价格
price = li.find_element_by_xpath('.//div[@class="p-price"]//i').text
# 评论数
comment = li.find_elements_by_xpath('.//div[@class="p-commit"]//a')
# 商铺名字
shop_name = li.find_elements_by_xpath('.//div[@class="p-shop"]//a')
if comment:
comment = comment[0].text
else:
comment = None
if shop_name:
shop_name = shop_name[0].text
else:
shop_name = None
data_dict ={}#写入字典
data_dict["title"] = title
data_dict["price"] = price
data_dict["shop_name"] = shop_name
data_dict["comment"] = comment
print(data_dict)
data_list.append(data_dict)#写入全局变量
except TimeoutError:
prase_html(html) def save_html():
content = json.dumps(data_list, ensure_ascii=False, indent=2)
#把全局变量转化为json数据
with open("jingdong1.json", "a+", encoding="utf-8") as f:
f.write(content)
print("json文件写入成功") with open('jingdong1.csv', 'w', encoding='utf-8', newline='') as f:
# 表头
title = data_list[0].keys()
# 声明writer
writer = csv.DictWriter(f, title)
# 写入表头
writer.writeheader()
# 批量写入数据
writer.writerows(data_list)
print('csv文件写入完成') def main():
print("第", 1, "页:")
total = int(search())
for i in range(2, 5):
# for i in range(2, total + 1):
time.sleep(random.randint(1, 3)) # 设置随机延迟
print("第", i, "页:")
next_page(i)
save_html() if __name__ == "__main__":
main()
最后再分享一些小福利
链接:https://pan.baidu.com/s/1sMxwTn7P2lhvzvWRwBjFrQ
提取码:kt2v
链接容易被举报过期,如果失效了就在这里领取吧
python爬虫——用selenium爬取京东商品信息的更多相关文章
- 爬虫之selenium爬取京东商品信息
import json import time from selenium import webdriver """ 发送请求 1.1生成driver对象 2.1窗口最大 ...
- selenium模块使用详解、打码平台使用、xpath使用、使用selenium爬取京东商品信息、scrapy框架介绍与安装
今日内容概要 selenium的使用 打码平台使用 xpath使用 爬取京东商品信息 scrapy 介绍和安装 内容详细 1.selenium模块的使用 # 之前咱们学requests,可以发送htt ...
- 利用selenium爬取京东商品信息存放到mongodb
利用selenium爬取京东商城的商品信息思路: 1.首先进入京东的搜索页面,分析搜索页面信息可以得到路由结构 2.根据页面信息可以看到京东在搜索页面使用了懒加载,所以为了解决这个问题,使用递归.等待 ...
- 爬虫系列(十三) 用selenium爬取京东商品
这篇文章,我们将通过 selenium 模拟用户使用浏览器的行为,爬取京东商品信息,还是先放上最终的效果图: 1.网页分析 (1)初步分析 原本博主打算写一个能够爬取所有商品信息的爬虫,可是在分析过程 ...
- Python爬虫-爬取京东商品信息-按给定关键词
目的:按给定关键词爬取京东商品信息,并保存至mongodb. 字段:title.url.store.store_url.item_id.price.comments_count.comments 工具 ...
- selenium+phantomjs爬取京东商品信息
selenium+phantomjs爬取京东商品信息 今天自己实战写了个爬取京东商品信息,和上一篇的思路一样,附上链接:https://www.cnblogs.com/cany/p/10897618. ...
- 爬虫—Selenium爬取JD商品信息
一,抓取分析 本次目标是爬取京东商品信息,包括商品的图片,名称,价格,评价人数,店铺名称.抓取入口就是京东的搜索页面,这个链接可以通过直接构造参数访问https://search.jd.com/Sea ...
- Python爬虫使用selenium爬取qq群的成员信息(全自动实现自动登陆)
前言 本文的文字及图片来源于网络,仅供学习.交流使用,不具有任何商业用途,版权归原作者所有,如有问题请及时联系我们以作处理. 作者: python小爬虫 PS:如有需要Python学习资料的小伙伴可以 ...
- 八个commit让你学会爬取京东商品信息
我发现现在不用标题党的套路还真不好吸引人,最近在做相关的事情,从而稍微总结出了一些文字.我一贯的想法吧,虽然才疏学浅,但是还是希望能帮助需要的人.博客园实在不适合这种章回体的文章.这里,我贴出正文的前 ...
随机推荐
- 码云上开源JAVA项目收藏
一. 个人学习项目 1. BootDo面向学习型的开源框架 (可以当做 管理台脚手架) BootDo是高效率,低封装,面向学习型,面向微服的开源Java EE开发框架. BootDo是在SpringB ...
- netcore webapi参数
1.参数带[FormBody]标签 2.ajax 请求 content-type:application/json 3.post时 需要JSON.stringify 4.GET 时不需要JSON.st ...
- 201771030103-陈正丽 实验一 软件工程准备—<快速浏览 邹欣老师博客—读后感>
项目 内容 <软件工程> 代祖华老师博客 作业要求 邹欣老师博客 学习目标 具体目标 在大概阅读邹欣老师的博客时,发现老师写了关于很多方面的内容,有基础的也有比较深奥的,这次阅读过程中主要 ...
- 1012 The Best Rank (25 分)
To evaluate the performance of our first year CS majored students, we consider their grades of three ...
- 开启sftp服务日志并限制sftp访问目录
目录导航 目录导航 开启sftp日志 修改sshd_config 修改syslogs 重启服务查看日志 限制sftp用户操作目录 前提说明 1. home目录做根目录 2. 单独创建目录做根目录 方法 ...
- redis 安装and对外开放端口
第一步: $ cd /usr/local/src $ wget http://download.redis.io/releases/redis-5.0.4.tar.gz $ tar xzf redis ...
- Linux服务器架设篇,DNS服务器(三),正反解区域的配置
一.大体架构 DNS服务器其实只有一个"真正"的配置文件,即 /etc/named.conf .其他的配置文件都是依据此配置展开的.每个域都需要两个配置文件,即正解文件和反解文件. ...
- pythone 时间模块
时间模块(时区) 计算方式:时间戳是一串数字,从计算机诞生的那一秒到现在过了多少秒,每过一秒+1 #时间戳#由时间戳获取格式化时间#由格式化时间获取时间戳 import time def timene ...
- eclipse 使用 快捷键
ctrl + t :查看类的子类和实现类 ctrl + o 查看类实现的方法 ctrl + 1 相当于idea的 alt + enter 补全变量 syso 点 alt + / System.out ...
- JS 浏览器BOM-->简介和属性
1.简介: BOM:浏览器对象模型(Browser Object Model),是一个用于访问浏览器和计算机屏幕的对象集合.我们可以通过全局对象window来访问这些对象. 2.属性 window. ...