基于scrapy框架输入关键字爬取有关贴吧帖子
基于scrapy框架输入关键字爬取有关贴吧帖子
站点分析
首先进入一个贴吧,要想达到输入关键词爬取爬取指定贴吧,必然需要利用搜索引擎
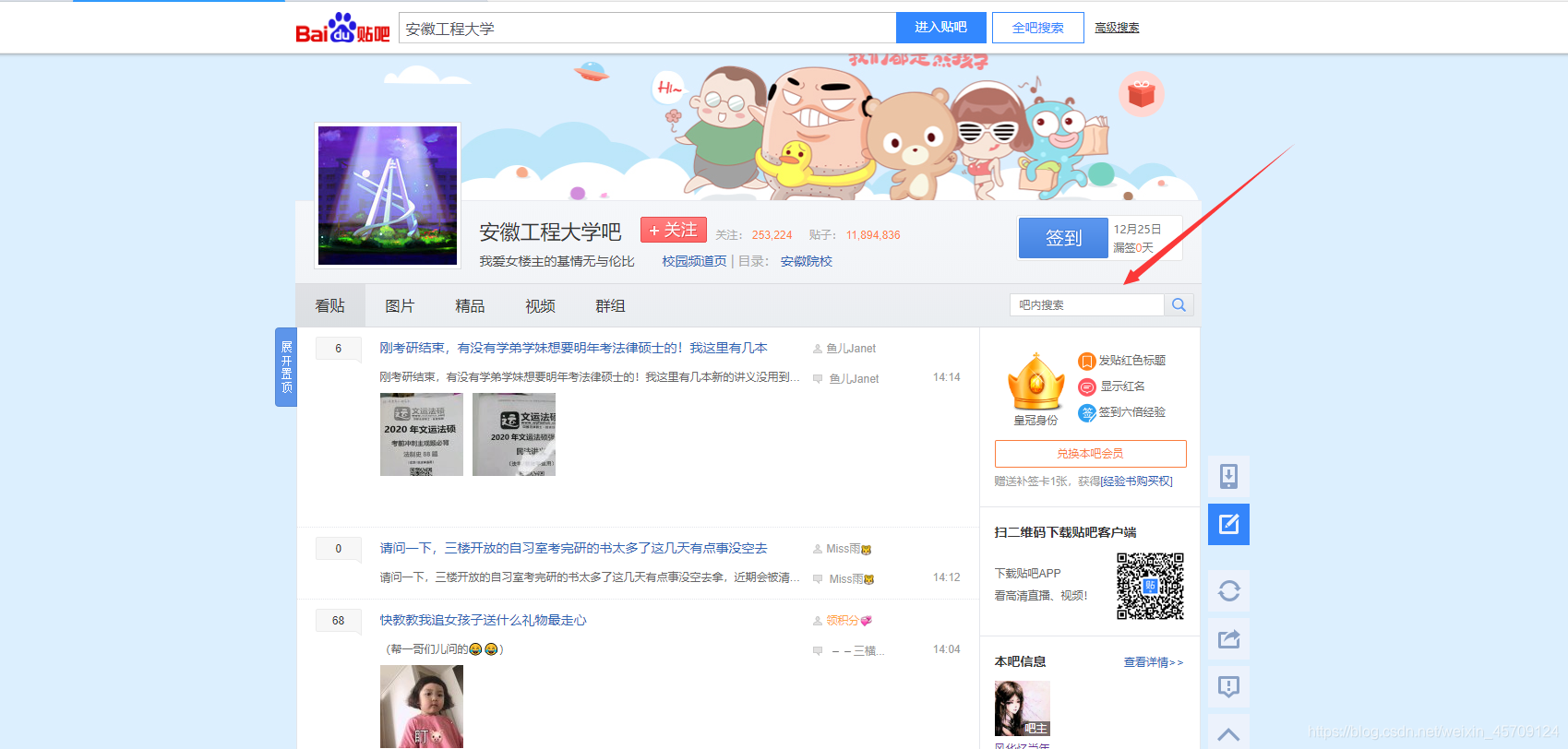
点进看到有四种搜索方式,分别试一次,观察url变化

我们得知:
搜索贴吧:http://tieba.baidu.com/f/search/fm?ie=UTF-8&qw=dfd
搜索帖子:http://tieba.baidu.com/f/search/res?ie=utf-8&qw=dfd
其中参数qw是搜索关键词,由此我们可以构建搜索贴吧的url
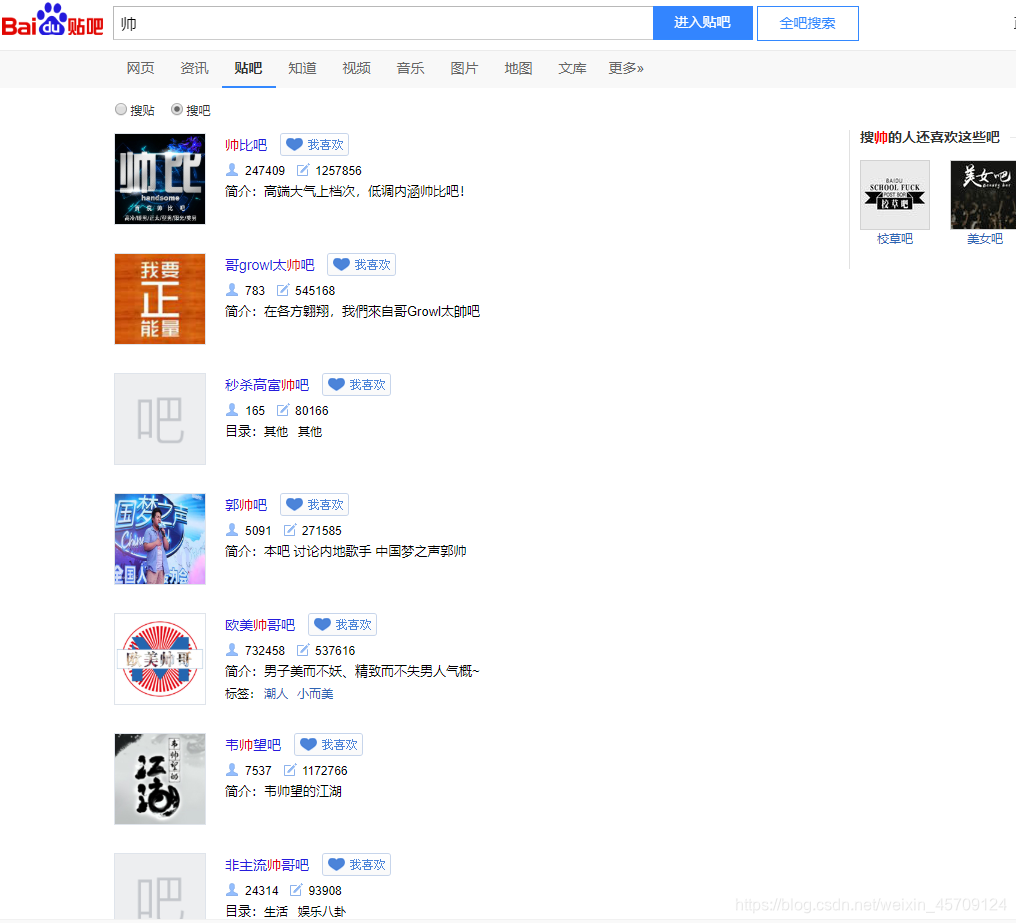
搜索得到的页面,可以得到我们需要的贴吧url
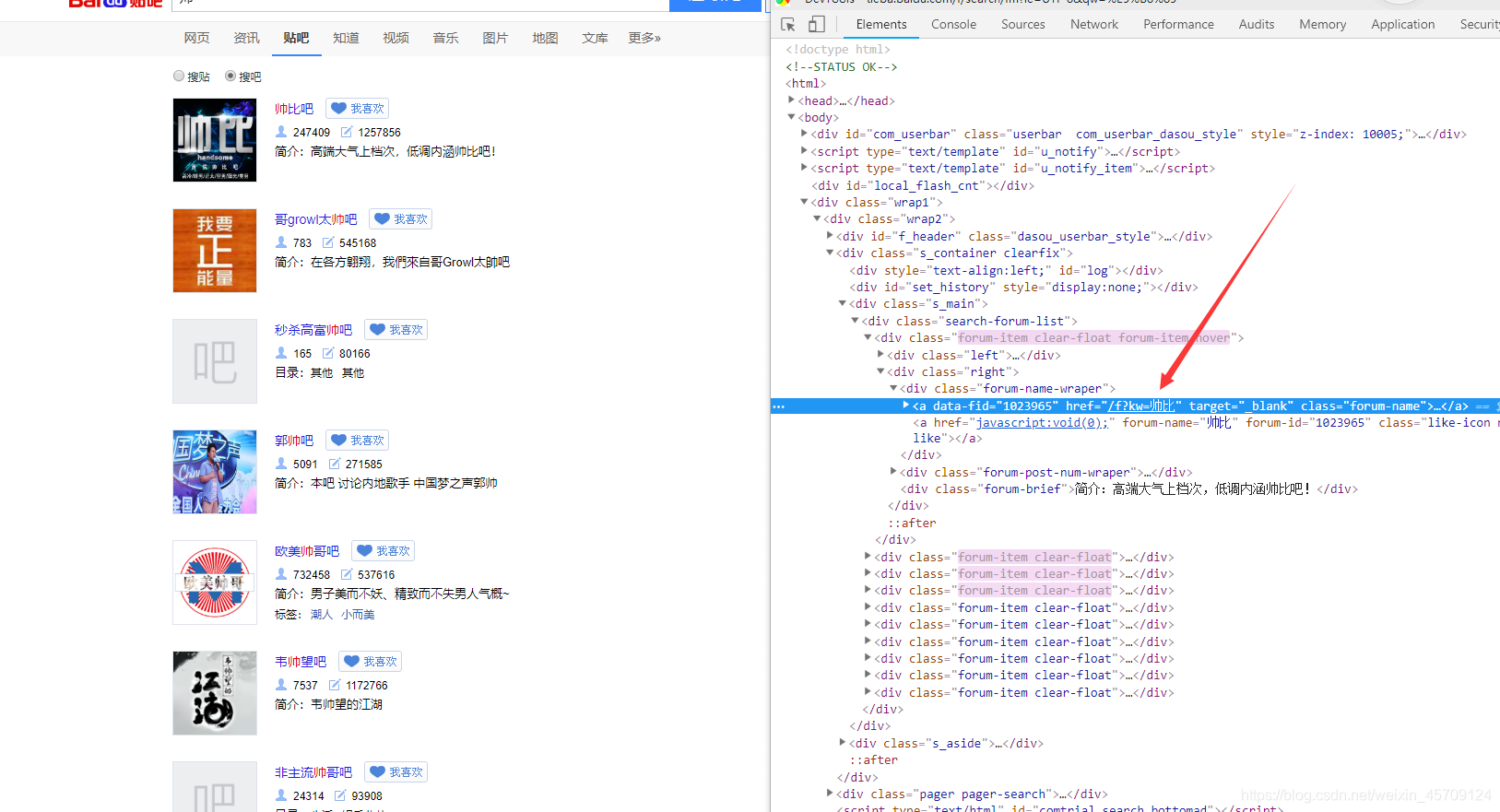
我们就可以轻而易举的得到我们搜索的相关贴吧
下面对贴吧主页进行分析
进入贴吧F12查看

显然我们知道#thread_list这个列表,观察看到这就是每个贴在,注意li标签里的data-field字段有我们需要的信息, 不过我们只需要得到帖子的url,之后对帖子进一步提取,其中data-tid就是贴子的id,通过这个我们可以定位唯一的帖子
如data-tid="6410699527", 则帖子的url为teiba.baidu.com/p/6410699527具体的探索过程就不一一阐述了。。。
对帖子分析

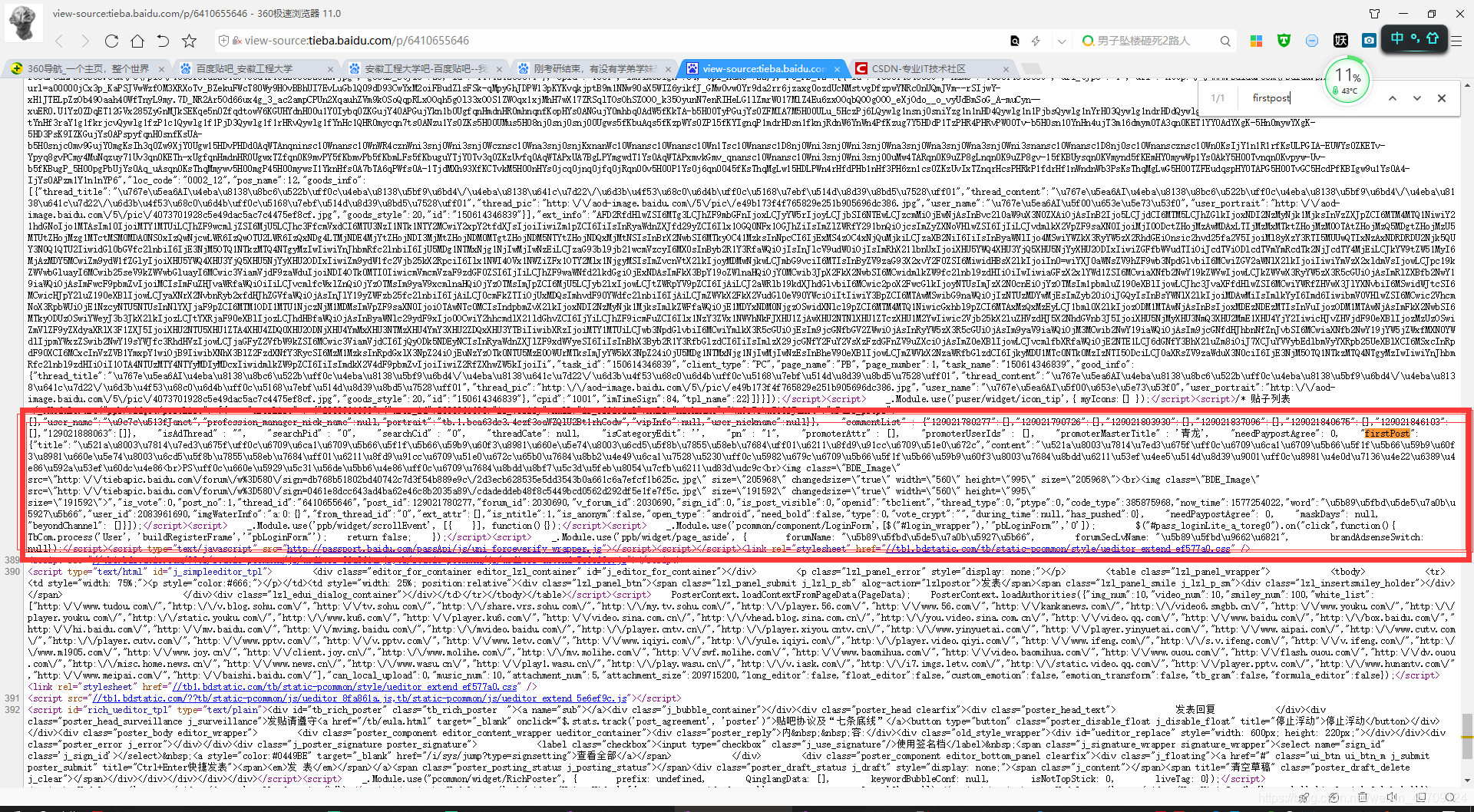
直接源码省去很多字、、、的寻找过程,我们在源码找到了一段JavaScript代码,其中firstpost就是楼主发的帖子。。为什么不在HTML便签中提取?因为你试试就知道了,开始我就是在HTML便签中提取的,部分贴吧标题提取不出来。firstpost有着很详细的信息,标题,内容,时间
现在对贴吧的回复贴吧提取:
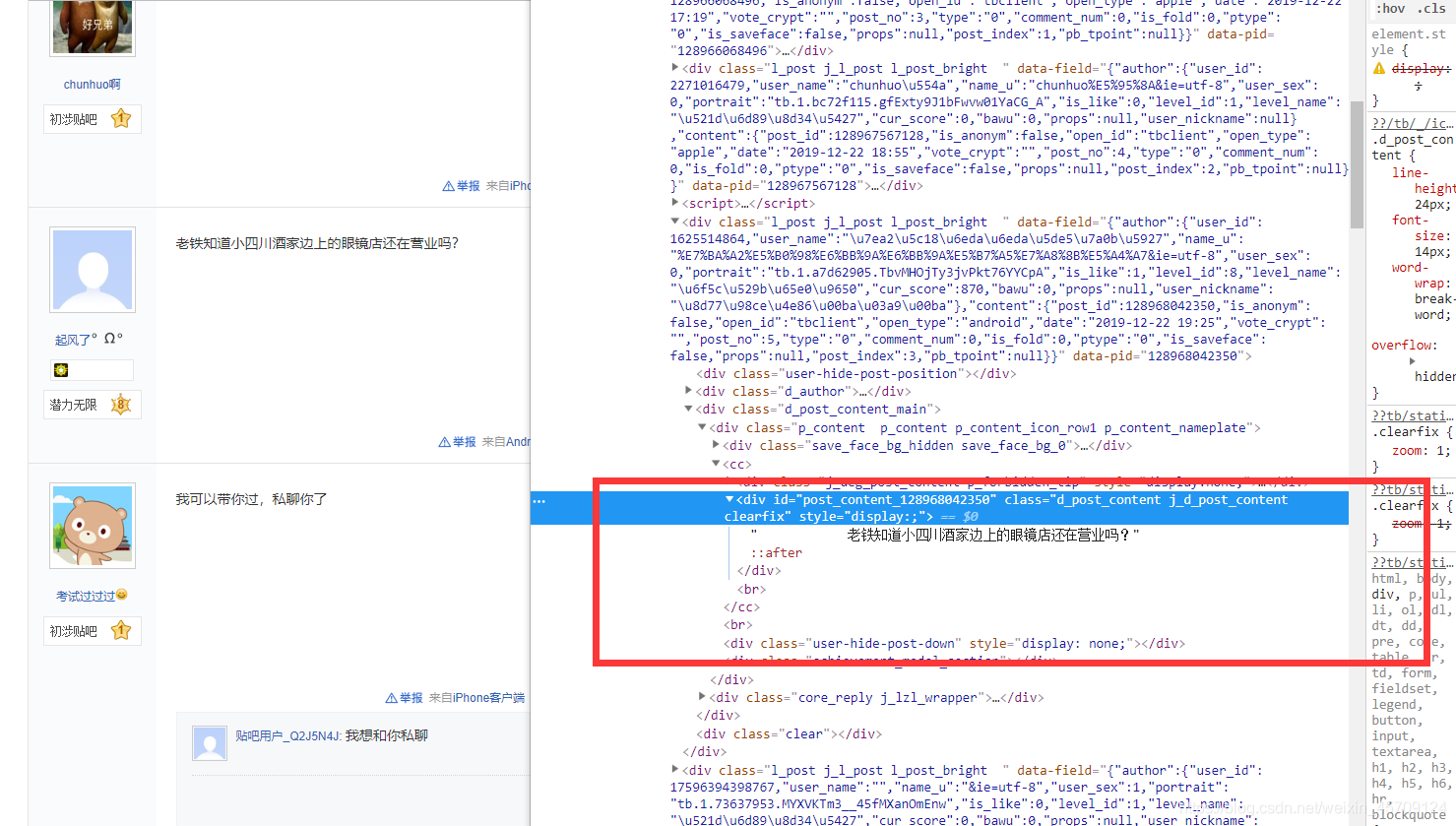
探索得知,很多带有表情的回复帖,内容很乱,打算正则提取。。。
一个小白的分析过程想的多,看的慢,难受!这里就不在阐述了,不然分析过程写不下
items.py编写
在这个模块里定义自己的字段,这里我们需要帖子的标题,内容,作者,时间,回复数,回复内容
源码:
# -*- coding: utf-8 -*-
import scrapy
class postDataItem(scrapy.Item):
tid = scrapy.Field()
title = scrapy.Field()
content = scrapy.Field()
author_name = scrapy.Field()
date = scrapy.Field()
reply_content = scrapy.Field()
reply_num = scrapy.Field()
device = scrapy.Field()#这给字段读者不必关注,项目所需
pipelines.py的编写
没有;
哈哈,还没想好用什么数据库
爬虫模块的编写
# -*- coding: utf-8 -*-
import scrapy
from urllib.parse import urlencode
from scrapy.http import Request
import re
import time
from ..items import postDataItem
class BtspiderSpider(scrapy.Spider):
name = 'btSpider'
allowed_domains = ['tieba.baidu.com']
base_url = 'http://tieba.baidu.com'
def start_requests(self):
"""
开始搜索相关学校贴吧
"""
search_base_url = 'http://tieba.baidu.com/f/search/fm?ie=UTF-8&'
arg1 = urlencode({'qw':self.school}) #通过命令行传递属性
search_url = search_base_url + arg1
yield Request(url=search_url, callback=self.get_search_page_urls, dont_filter=True) #搜索的url送到调度器, 注意:这个url不参与去重下面用到
def get_search_page_urls(self, response):
"""
获得搜索结果所有页面,
发送每页的url到调度器
"""
pager_search = response.xpath("//div[@class='pager pager-search']/a/@href").extract()[:-2]
pager_search = [(self.base_url + pager) for pager in pager_search ]
pager_search.append(response.url)
for pager_url in pager_search:
yield Request(url=pager_url, callback=self.get_forum_urls)
def get_forum_urls(self, response):
"""
获得所有相关贴吧的url送到调度器
"""
forum_lists = response.xpath('//div[@class="search-forum-list"]/div[@class="forum-item clear-float"]')
for forum in forum_lists:
forum_url = self.base_url + forum.xpath('./div[@class="left"]/a/@href').extract_first()
yield Request(url=forum_url, callback=self.get_post_urls)
def get_post_urls(self, response):
"""
获得所有帖子的url
"""
postList = response.xpath("//li[@class=' j_thread_list clearfix']")
for post in postList:
data_tid = post.xpath("./@data-tid").extract_first()
post_url = self.base_url + '/p/' + data_tid
yield Request(url=post_url, callback=self.get_post_data)
#实现翻页操作
url_list = response.xpath("//div[@id='frs_list_pager']/a")[:-2]
for url in url_list:
if int(re.findall('.*pn=(\d*)', url.xpath('./@href').extract_first())[0]) <= 20000:
yield response.follow(url=url, callback=self.get_post_urls)
else:
break
def get_post_data(self, response):
post_data_item = postDataItem()
# 提取帖子id
tid = re.compile("https?://tieba.baidu.com/p/(\d*).*").findall(response.url)[0]
post_data_item['tid'] = tid
# 提取帖子内容的正则表达式,来源为页面底部JavaScript代码
rpost = '"firstPost": {"title":"(?P<title>.*)","content":"(?P<content>.*)","is_vote".*"now_time":(?P<date>\d*)'
post = re.search(rpost, response.text)
# 将字符串Unicode编码转换为中文
dirty_title = post.group('title').encode('utf-8').decode("unicode_escape")
dirty_content = post.group('content').encode('utf-8').decode("unicode_escape")
# 找到所有标签替换为空
post_data_item['title'] = re.sub('<.*?>', '', dirty_title)
post_data_item['content'] = re.sub('<.*?>', '', dirty_content)
# 时间戳转换为字符串时间
post_data_item['date'] = time.strftime("%Y-%m-%d %X", time.localtime(int(post.group('date'))))
# 提取作者的xpath表达式
xauthor = "//div[contains(@class, 'louzhubiaoshi')]/@author"
post_data_item['author_name'] = response.xpath(xauthor).extract_first()
# 提取楼层回复内容的xpath表达式,是所有的内容
# 这是经过清洗的数据用它来做分析
xreply_content = "//div[contains(@class, 'd_post_content')]/text()"
all_content = response.xpath(xreply_content).extract()
all_content_dirty = ''.join(all_content)
post_data_item['reply_content'] = ''.join(re.findall(r'[\u4e00-\u9fa5]', all_content_dirty))
# 提取帖子回复数量的xpath表达式
xreply_num = "//span[@class='red']/text()"
post_data_item['reply_num'] = response.xpath(xreply_num).extract_first()
for key, value in post_data_item.items():
print(key, value)
运行结果
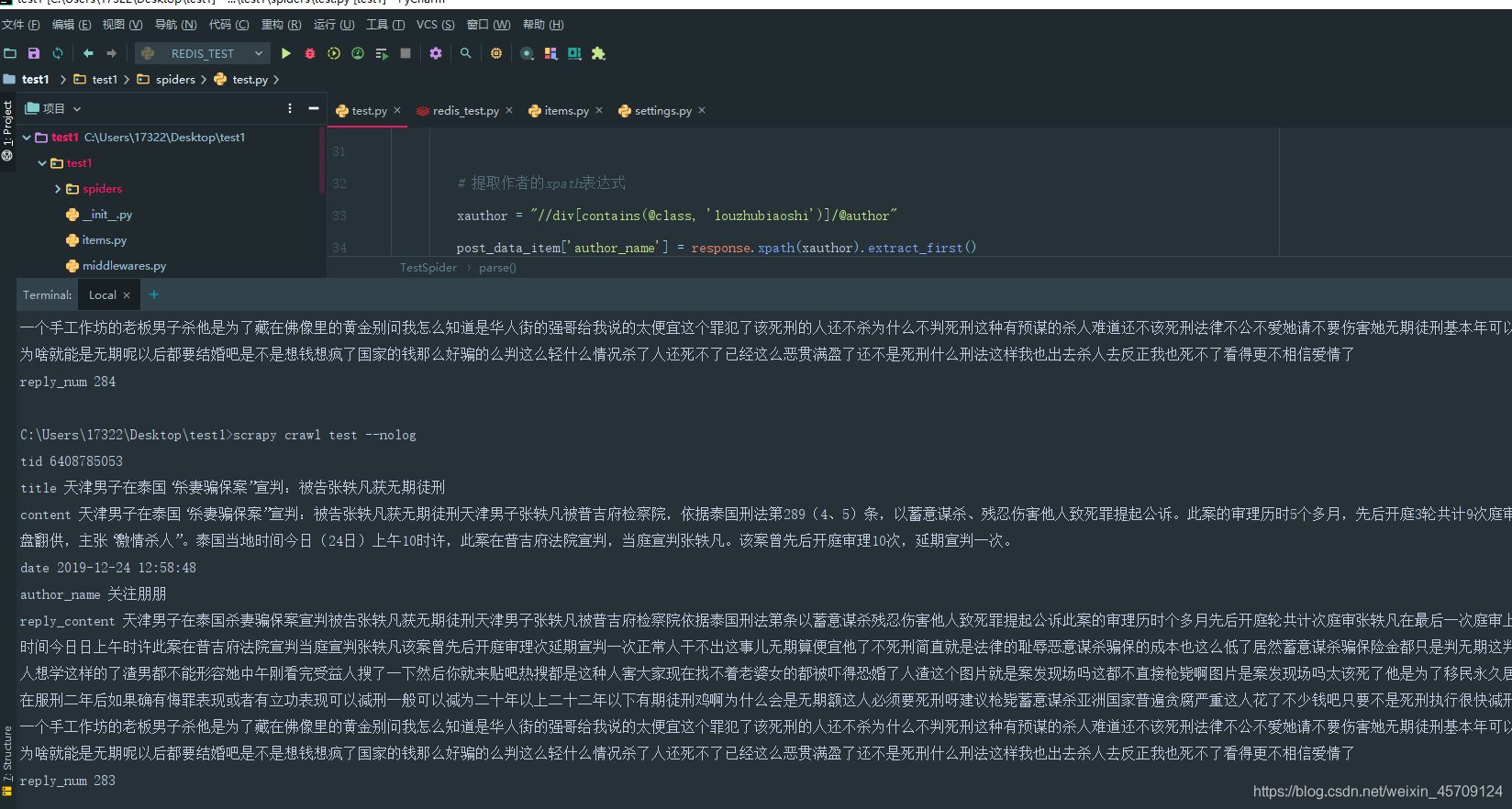
注意这是,我爬虫的精简版,只专注于一个帖子爬取
基于scrapy框架输入关键字爬取有关贴吧帖子的更多相关文章
- 一个scrapy框架的爬虫(爬取京东图书)
我们的这个爬虫设计来爬取京东图书(jd.com). scrapy框架相信大家比较了解了.里面有很多复杂的机制,超出本文的范围. 1.爬虫spider tips: 1.xpath的语法比较坑,但是你可以 ...
- scrapy框架综合运用 爬取天气预报 + 定时任务
爬取目标网站: http://www.weather.com.cn/ 具体区域天气地址: http://www.weather.com.cn/weather1d/101280601.shtm(深圳) ...
- Scrapy 框架 使用 selenium 爬取动态加载内容
使用 selenium 爬取动态加载内容 开启中间件 DOWNLOADER_MIDDLEWARES = { 'wangyiPro.middlewares.WangyiproDownloaderMidd ...
- Scrapy框架——使用CrawlSpider爬取数据
引言 本篇介绍Crawlspider,相比于Spider,Crawlspider更适用于批量爬取网页 Crawlspider Crawlspider适用于对网站爬取批量网页,相对比Spider类,Cr ...
- 信息技术手册可视化进度报告 基于BeautifulSoup框架的python3爬取数据并连接保存到MySQL数据库
老师给我们提供了一个word文档,里面是一份信息行业热词解释手册,要求我们把里面的文字存进数据库里面,然后在前台展示出来. 首先面临的问题是怎么把数据导进MySQL数据库,大家都有自己的方法,我采用了 ...
- scrapy框架基于CrawlSpider的全站数据爬取
引入 提问:如果想要通过爬虫程序去爬取”糗百“全站数据新闻数据的话,有几种实现方法? 方法一:基于Scrapy框架中的Spider的递归爬取进行实现(Request模块递归回调parse方法). 方法 ...
- Python爬虫:通过关键字爬取百度图片
使用工具:Python2.7 点我下载 scrapy框架 sublime text3 一.搭建python(Windows版本) 1.安装python2.7 ---然后在cmd当中输入python,界 ...
- 基于scrapy框架的爬虫
Scrapy是一个为了爬取网站数据,提取结构性数据而编写的应用框架. 可以应用在包括数据挖掘,信息处理或存储历史数据等一系列的程序中. scrapy 框架 高性能的网络请求 高性能的数据解析 高性能的 ...
- 基于Scrapy框架的Python新闻爬虫
概述 该项目是基于Scrapy框架的Python新闻爬虫,能够爬取网易,搜狐,凤凰和澎湃网站上的新闻,将标题,内容,评论,时间等内容整理并保存到本地 详细 代码下载:http://www.demoda ...
随机推荐
- 打造Worktile敏捷开发管理工具的思与惑
从2019年初,我们团队准备开发一款适合研发团队使用的敏捷开发管理工具,那时候我们也在思考,到底什么样的工具才算是优秀的研发管理工具,研发管理的场景.方法和流派有很多,市面上关于研发管理工具的产品也是 ...
- nginx 报 502 bad gateway 分析解决
出现nginx 502 bad gateway 问题,先从nginx端日志入手,分析排查原因. 1.排查问题 首先需要打开nginx错误日志. 编辑nginx.conf,默认路径在/usr/local ...
- [vijos1145]小胖吃巧克力<概率dp>
题目链接:https://vijos.org/p/1145 貌似还有一个一样的题是poj1322 chocolate,两个题只是描述不一样,意思都是一样的,不贵最近貌似poj炸了,所以也没法去poj ...
- html第一个程序
2020-04-05 每日一例第27天 1.打开记事本,输入html格式语言: 2.后台代码注释: <html> <head><!--标题语句--> <ti ...
- Windows 7集成IE11(离线安装包、补丁)
当Win7系统需要集成IE11时,我们需要提前打入6个补丁 KB2731771.KB2786081.KB2834140.KB2670838.KB2729094.KB2533623 32位 ★百度网盘 ...
- C++中的字符串切片操作
string str = "hello"; str.substr(0,2); //输出"he", 表示[0,2)
- MariaDB使用数据库查询《三》
MariaDB使用数据库查询 案例5:使用数据库查询 5.1 问题 本例要求配 ...
- Java对字母大小写转换
Java对字母大小写转换 1.小写——大写String aa = "abc".toUpperCase(); 2.大写——小写 String bb = "ABC" ...
- javascript入门 之 ztree (十 checkbox选中事件)
<!DOCTYPE html> <HTML> <HEAD> <TITLE> ZTREE DEMO - beforeCheck / onCheck< ...
- TP5快速入门
一.查询 //order支持使用数组对多个字段的排序,例如order(['order','id'=>'desc']) //group方法只有一个参数,并且只能使用字符串. //having方法只 ...