Decision Trees 决策树
Decision Trees (DT)是用于分类和回归的非参数监督学习方法。 目标是创建一个模型,通过学习从数据特征推断出的简单决策规则来预测目标变量的值。
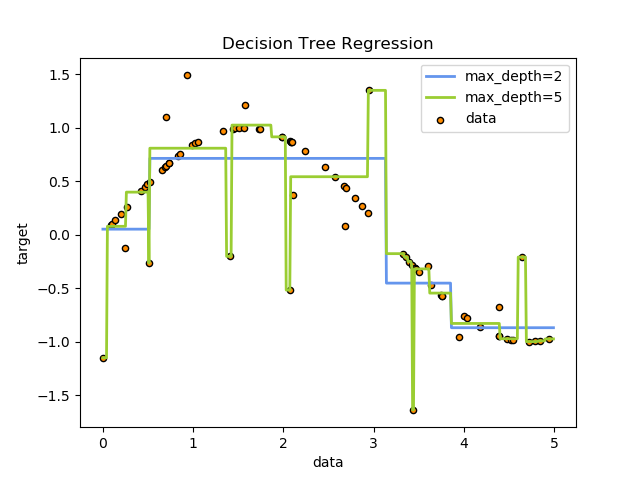
例如,在下面的例子中,决策树从数据中学习用一组if-then-else决策规则逼近正弦曲线。 树越深,决策规则越复杂,模型也越复杂。
决策树的优点:
- 易于理解和解释。树可以被可视化。
- 需要很少的数据准备。其他技术通常需要数据标准化,需要创建虚拟变量,并删除空白值。但请注意,该模块不支持缺少的值。
- 使用树(即,预测数据)的成本在用于训练树的数据点的数量上是对数级别的。
- 能够处理数字和分类数据。其他技术通常专门用于分析只有一种变量的数据集。查看更多信息的算法。
- 能够处理多输出问题
- 使用白盒模型。如果一个给定的情况在一个模型中是可观察的,那么这个条件的解释可以用布尔逻辑来解释。相反,在黑盒模型(例如,在人造神经网络中),结果可能更难以解释。
- 可以使用统计测试来验证模型。这可以说明模型的可靠性
- 即使其假设受到数据生成的真实模型的某些违反,也能很好地执行。
决策树的缺点:
- 决策树学习者可以创建过于复杂的树,不能很好地概括数据。这被称为过度拟合。修剪(目前不支持)等机制,设置叶节点所需的最小样本数或设置树的最大深度是避免此问题所必需的。
- 决策树可能是不稳定的,因为数据的小变化可能导致生成完全不同的树。通过在集合(ensemble)中使用决策树可以缓解这个问题。
- 学习最优决策树的问题在最优化的几个方面甚至简单的概念上都被认为是NP完全的。因此,实际的决策树学习算法基于启发式算法,例如在每个节点处进行局部最优决策的贪婪算法。这样的算法不能保证返回全局最优的决策树。这可以通过在集合学习器(ensemble learner)中训练多个树来减轻,其中特征和样本随机地被替换。
- 有些概念很难学,因为决策树不能很容易地表达它们,比如XOR,奇偶校验或多路复用器问题。
- 决策树学习者如果某些类占主导地位,就会创建偏向性树。因此建议在拟合决策树之前平衡数据集。
Classification
DecisionTreeClassifier是一个能够对数据集进行多类分类的类。
与其他分类器一样,DecisionTreeClassifier采用两个数组作为输入:保存训练样本的大小为[n_samples,n_features]的稀疏或密集数组X,以及保存类标签的整数值数组Y [n_samples] 训练样本:
>>> from sklearn import tree
>>> X = [[0, 0], [1, 1]]
>>> Y = [0, 1]
>>> clf = tree.DecisionTreeClassifier()
>>> clf = clf.fit(X, Y)
经过拟合后,模型可以用来预测样本的类别:
>>> clf.predict([[2., 2.]])
array([1])
或者,可以预测每个类的概率,这是叶子节点中同一类的训练样本的比值:
>>> clf.predict_proba([[2., 2.]])
array([[ 0., 1.]])
DecisionTreeClassifier具有二进制(其中标签是[-1,1])分类和多类(其中标签是[0,...,K-1])分类的能力。
使用Iris数据集,我们可以构建一棵树,如下所示:
>>> from sklearn.datasets import load_iris
>>> from sklearn import tree
>>> iris = load_iris()
>>> clf = tree.DecisionTreeClassifier()
>>> clf = clf.fit(iris.data, iris.target)
一旦训练完成,我们可以使用export_graphviz导出器以Graphviz格式导出树。 如果您使用conda软件包管理器,则可以使用graphviz二进制文件和python软件包进行安装
conda install python-graphviz
或者,可以从graphviz项目主页下载graphviz的二进制文件,并使用pip安装graphviz从pypi安装Python包装程序。
下面是在整个Iris数据集上训练的上述树的graphviz输出示例; 结果保存在一个输出文件iris.pdf中:
>>> import graphviz
>>> dot_data = tree.export_graphviz(clf, out_file=None)
>>> graph = graphviz.Source(dot_data)
>>> graph.render("iris")
export_graphviz导出器还支持各种美观的选项,包括按类别(或回归值)着色节点,并根据需要使用显式变量和类名称。 Jupyter笔记本也自动内联这些图。
>>> dot_data = tree.export_graphviz(clf, out_file=None,
feature_names=iris.feature_names,
class_names=iris.target_names,
filled=True, rounded=True,
special_characters=True)
>>> graph = graphviz.Source(dot_data)
>>> graph

经过拟合后,模型可以用来预测样本的类别:
>>> clf.predict(iris.data[:1, :])
array([0])
或者,可以预测每个类的概率,这是叶子节点中同一类的训练样本的比值:
>>> clf.predict_proba([[2., 2.]])
array([[ 0., 1.]])
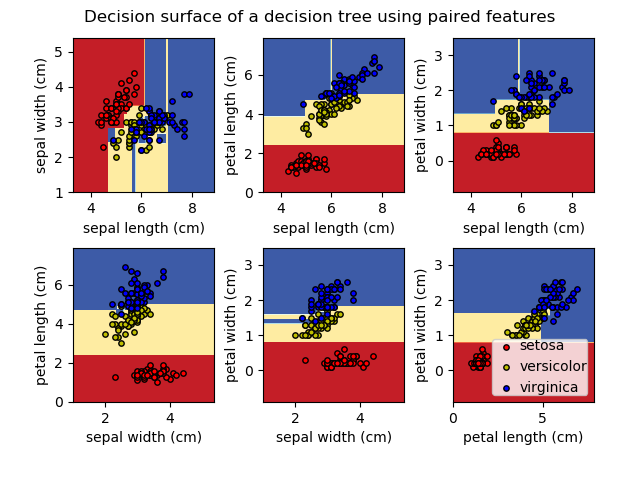
实际使用中的Tips:
- 决策树倾向于过度拟合具有大量特征的数据。获得正确的样本数与特征数之间的比例是重要的,因为在高维空间中具有很少样本的树很可能过度拟合。
- 考虑预先执行降维(PCA, ICA, or Feature selection),以使您的树更有可能找到具有区分性的特征。
- 通过使用
exportfunction来训练您正在训练的树。使用max_depth = 3作为初始树深度,以了解树如何适合您的数据,然后增加深度。 - 请记住,填充树所需的样本数是树增长的每个附加等级的两倍(原话:number of samples required to populate the tree doubles for each additional level the tree grows to)。使用max_depth来控制树的大小以防止过度拟合。
- 使用min_samples_split或min_samples_leaf来控制叶节点处的采样数量。一个非常小的数字通常意味着树会过度拟合,而大的数值将阻止树学习数据。尝试min_samples_leaf = 5作为初始值。如果样本量变化很大,则可以使用浮点数作为这两个参数的百分比。两者之间的主要区别在于,min_samples_leaf保证叶子中的样本数量最小,而min_samples_split可以创建任意的小叶子,尽管min_samples_split在文献中更为常见。
- 在训练之前平衡你的数据集,以防止树偏向于占优势的类。类平衡可以通过从每个类中采样相同数量的样本来完成,或者优选地通过将每个类的样本权重的总和(sample_weight)归一化为相同的值来完成。还要注意,像min_weight_fraction_leaf这样的基于权重的预剪枝标准将不会比不知道样本权重的标准(如min_samples_leaf)偏向于显性类。
- 如果样本被加权,使用基于权重的预剪枝准则(如min_weight_fraction_leaf)可以更容易地优化树结构,从而确保叶节点至少包含样本权重总和的一小部分。
- 所有决策树都在内部使用np.float32数组。如果训练数据不是这种格式,将会创建一个数据集的副本。
- 如果输入矩阵X非常稀疏,则建议在调用预测之前将其转换为稀疏csc_matrix,然后稀疏csr_matrix。对于稀疏矩阵输入,相比于密集矩阵,当特征在大多数采样中具有零值时,训练时间可以快几个数量级。
未完待续。。。
详见:http://scikit-learn.org/stable/modules/tree.html
Decision Trees 决策树的更多相关文章
- Decision trees决策树
信息熵(entropy) 信息熵模型(香农Shannon's Entropy Model) 在一个随机事件中,某个事件发生的不确定度越大,熵也就越大,那我们要搞清楚所需要的信息量越 信息增益(IG,I ...
- 海量数据挖掘MMDS week6: 决策树Decision Trees
http://blog.csdn.net/pipisorry/article/details/49445465 海量数据挖掘Mining Massive Datasets(MMDs) -Jure Le ...
- Facebook Gradient boosting 梯度提升 separate the positive and negative labeled points using a single line 梯度提升决策树 Gradient Boosted Decision Trees (GBDT)
https://www.quora.com/Why-do-people-use-gradient-boosted-decision-trees-to-do-feature-transform Why ...
- CatBoost使用GPU实现决策树的快速梯度提升CatBoost Enables Fast Gradient Boosting on Decision Trees Using GPUs
python机器学习-乳腺癌细胞挖掘(博主亲自录制视频)https://study.163.com/course/introduction.htm?courseId=1005269003&ut ...
- Logistic Regression vs Decision Trees vs SVM: Part II
This is the 2nd part of the series. Read the first part here: Logistic Regression Vs Decision Trees ...
- Logistic Regression Vs Decision Trees Vs SVM: Part I
Classification is one of the major problems that we solve while working on standard business problem ...
- 机器学习算法 --- Pruning (decision trees) & Random Forest Algorithm
一.Table for Content 在之前的文章中我们介绍了Decision Trees Agorithms,然而这个学习算法有一个很大的弊端,就是很容易出现Overfitting,为了解决此问题 ...
- 机器学习算法 --- Decision Trees Algorithms
一.Decision Trees Agorithms的简介 决策树算法(Decision Trees Agorithms),是如今最流行的机器学习算法之一,它即能做分类又做回归(不像之前介绍的其他学习 ...
- Machine Learning Methods: Decision trees and forests
Machine Learning Methods: Decision trees and forests This post contains our crib notes on the basics ...
随机推荐
- 配置kubernetes.client的参数遇到的坑
配置kubernetes.client遇到的一些坑: 一,job-name不能重名,如果job-name已经有了,再创建job,则会发生冲突cliflict 这样将会报以下错误:Reason : Co ...
- List of Mozilla-Based Applications
List of Mozilla-Based Applications The following is a list of all known active applications that are ...
- JavaScript json loop item in array
Iterating through/Parsing JSON Object via JavaScript 解答1 Your JSON object is incorrect because it ha ...
- bootstrap 讲解(中)
bootstrap:常用于后台开发,如学生管理系统,虽然稍显笨重,但也是一个开发的利器 推荐下载 3.3.7 版本 也可下载最新版4.3.1 (最新版在手机端不起效果) 且依赖 jQuery 的封装库 ...
- rtmpdump禁用openssl
rtmpdump禁用openssl 主要是编译方便 很多地方根本不需要用openssl 先找到librtmp/rtmp_sys.h 然后加入宏#define NO_CRYPTO在#ifdef _WIN ...
- C# WPF 擦出效果,刮图效果
找了很久 <Window x:Class="TestWebbowser.TestMaskWind" xmlns="http://schemas.microsoft. ...
- docker镜像和加速
首先,需要明确一个问题:Mirror 与 Private Registry 有什么区别? Private Registry 是开发者或者企业自建的镜像存储库,通常用来保存企业内部的 Docker 镜像 ...
- redis 管理工具
1.redis studio 2.redis desktop manager
- PushConsumer 消费消息
CLUSTERING 模式下,消费者会订阅 retry topic // DefaultMQPushConsumerImpl#copySubscription private void copySub ...
- 【漏洞复现】局域网 ARP 中间人攻击 获取他人账号密码
日期:2019-07-18 14:24:42 更新: 作者:Bay0net 介绍:如何在局域网内,窃取其他用户的账号密码? 0x01. 漏洞环境 攻击工具 arpspoof 基本用法: arpspoo ...